 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard Cases Detection in Motion Prediction by Vision-Language Foundation Models
May 31, 2024


Addressing hard cases in autonomous driving, such as anomalous road users, extreme weather conditions, and complex traffic interactions, presents significant challenges. To ensure safety, it is crucial to detect and manage these scenarios effectively for autonomous driving systems. However, the rarity and high-risk nature of these cases demand extensive, diverse datasets for training robust models. Vision-Language Foundation Models (VLMs) have shown remarkable zero-shot capabilities as being trained on extensive datasets. This work explores the potential of VLMs in detecting hard cases in autonomous driving. We demonstrate the capability of VLMs such as GPT-4v in detecting hard cases in traffic participant motion prediction on both agent and scenario levels. We introduce a feasible pipeline where VLMs, fed with sequential image frames with designed prompts, effectively identify challenging agents or scenarios, which are verified by existing prediction models. Moreover, by taking advantage of this detection of hard cases by VLMs, we further improve the training efficiency of the existing motion prediction pipeline by performing data selection for the training samples suggested by GPT. We show the effectiveness and feasibility of our pipeline incorporating VLMs with state-of-the-art methods on NuScenes datasets. The code is accessible at https://github.com/KTH-RPL/Detect_VLM.
Human-Centric Autonomous Systems With LLMs for User Command Reasoning
Nov 14, 2023The evolution of autonomous driving has made remarkable advancements in recent years, evolving into a tangible reality. However, a human-centric large-scale adoption hinges on meeting a variety of multifaceted requirements. To ensure that the autonomous system meets the user's intent, it is essential to accurately discern and interpret user commands, especially in complex or emergency situations. To this end, we propose to leverage the reasoning capabilities of Large Language Models (LLMs) to infer system requirements from in-cabin users' commands. Through a series of experiments that include different LLM models and prompt designs, we explore the few-shot multivariate binary classification accuracy of system requirements from natural language textual commands. We confirm the general ability of LLMs to understand and reason about prompts but underline that their effectiveness is conditioned on the quality of both the LLM model and the design of appropriate sequential prompts. Code and models are public with the link \url{https://github.com/KTH-RPL/DriveCmd_LLM}.
Fully Sparse Long Range 3D Object Detection Using Range Experts and Multimodal Virtual Points
Oct 07, 20233D object detection at long-range is crucial for ensuring the safety and efficiency of self-driving cars, allowing them to accurately perceive and react to objects, obstacles, and potential hazards from a distance. But most current state-of-the-art LiDAR based methods are limited by the sparsity of range sensors, which generates a form of domain gap between points closer to and farther away from the ego vehicle. Another related problem is the label imbalance for faraway objects, which inhibits the performance of Deep Neural Networks at long-range. Although image features could be beneficial for long-range detections, and some recently proposed multimodal methods incorporate image features, they do not scale well computationally at long ranges or are limited by depth estimation accuracy. To address the above limitations, we propose to combine two LiDAR based 3D detection networks, one specializing at near to mid-range objects, and one at long-range 3D detection. To train a detector at long range under a scarce label regime, we further propose to weigh the loss according to the labelled objects' distance from ego vehicle. To mitigate the LiDAR sparsity issue, we leverage Multimodal Virtual Points (MVP), an image based depth completion algorithm, to enrich our data with virtual points. Our method, combining two range experts trained with MVP, which we refer to as RangeFSD, achieves state-of-the-art performance on the Argoverse2 (AV2) dataset, with improvements at long range. The code will be released soon.
RMP: A Random Mask Pretrain Framework for Motion Prediction
Sep 16, 2023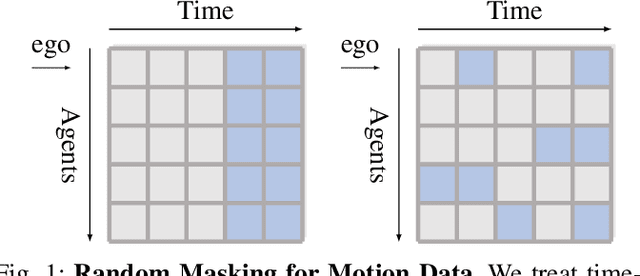
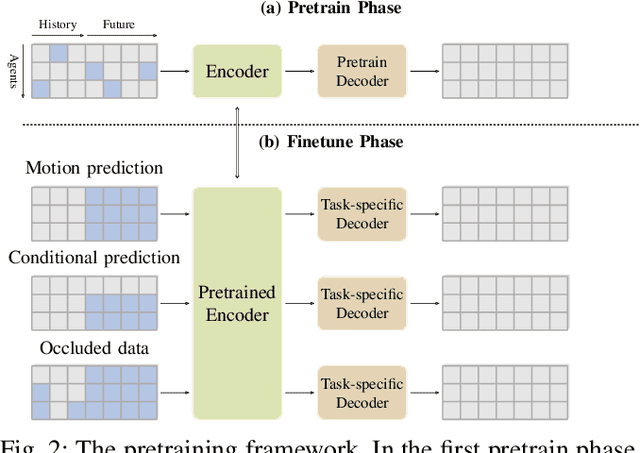
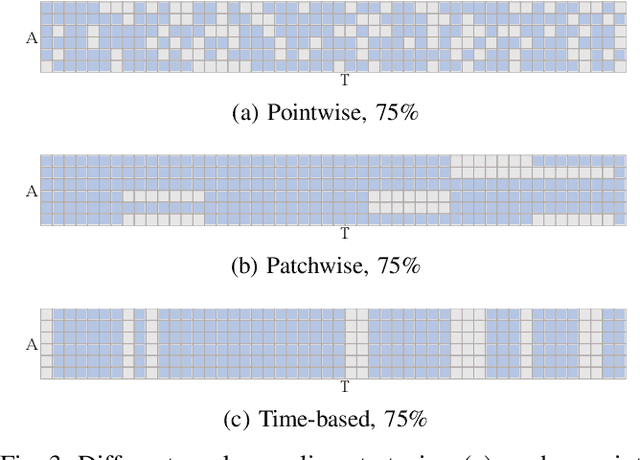
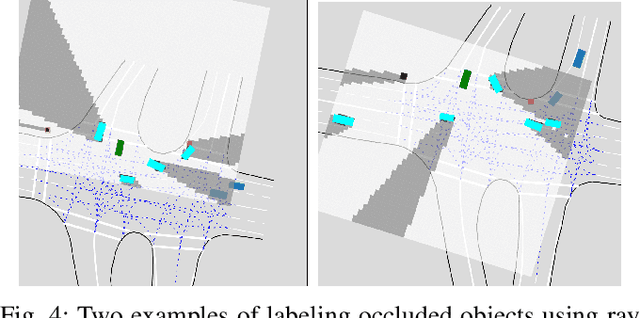
As the pretraining technique is growing in popularity, little work has been done on pretrained learning-based motion prediction methods in autonomous driving. In this paper, we propose a framework to formalize the pretraining task for trajectory prediction of traffic participants. Within our framework, inspired by the random masked model in natural language processing (NLP) and computer vision (CV), objects' positions at random timesteps are masked and then filled in by the learned neural network (NN). By changing the mask profile, our framework can easily switch among a range of motion-related tasks. We show that our proposed pretraining framework is able to deal with noisy inputs and improves the motion prediction accuracy and miss rate, especially for objects occluded over time by evaluating it on Argoverse and NuScenes datasets.