 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiER: Highlight Experience Replay and Easy2Hard Curriculum Learning for Boosting Off-Policy Reinforcement Learning Agents
Dec 14, 2023



Even though reinforcement-learning-based algorithms achieved superhuman performance in many domains, the field of robotics poses significant challenges as the state and action spaces are continuous, and the reward function is predominantly sparse. In this work, we propose: 1) HiER: highlight experience replay that creates a secondary replay buffer for the most relevant experiences, 2) E2H-ISE: an easy2hard data collection curriculum-learning method based on controlling the entropy of the initial state-goal distribution and with it, indirectly, the task difficulty, and 3) HiER+: the combination of HiER and E2H-ISE. They can be applied with or without the techniques of hindsight experience replay (HER) and prioritized experience replay (PER). While both HiER and E2H-ISE surpass the baselines, HiER+ further improves the results and significantly outperforms the state-of-the-art on the push, slide, and pick-and-place robotic manipulation tasks. Our implementation and further media materials are available on the project site.
Sim2Real Grasp Pose Estimation for Adaptive Robotic Applications
Nov 02, 2022Adaptive robotics plays an essential role in achieving truly co-creative cyber physical systems. In robotic manipulation tasks, one of the biggest challenges is to estimate the pose of given workpieces. Even though the recent deep-learning-based models show promising results, they require an immense dataset for training. In this paper, we propose two vision-based, multiobject grasp-pose estimation models, the MOGPE Real-Time (RT) and the MOGPE High-Precision (HP). Furthermore, a sim2real method based on domain randomization to diminish the reality gap and overcome the data shortage. We yielded an 80% and a 96.67% success rate in a real-world robotic pick-and-place experiment, with the MOGPE RT and the MOGPE HP model respectively. Our framework provides an industrial tool for fast data generation and model training and requires minimal domain-specific data.
Object Detection Using Sim2Real Domain Randomization for Robotic Applications
Aug 08, 2022

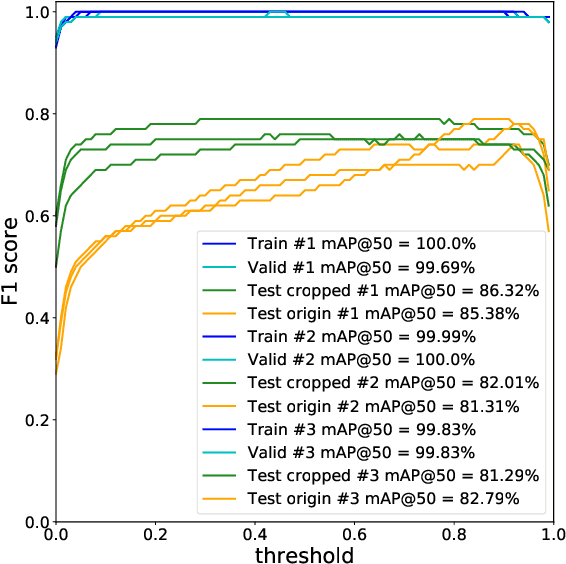

Robots working in unstructured environments must be capable of sensing and interpreting their surroundings. One of the main obstacles of deep learning based models in the field of robotics is the lack of domain-specific labeled data for different industrial applications. In this paper, we propose a sim2real transfer learning method based on domain randomization for object detection with which labeled synthetic datasets of arbitrary size and object types can be automatically generated. Subsequently, a state-of-the-art convolutional neural network, YOLOv4, is trained to detect the different types of industrial objects. With the proposed domain randomization method, we could shrink the reality gap to a satisfactory level, achieving 86.32% and 97.38% mAP50 scores respectively in the case of zero-shot and one-shot transfers, on our manually annotated dataset containing 190 real images. On a GeForce RTX 2080 Ti GPU, the data generation process takes less than 0.5s per image and the training lasts around 12h which makes it convenient for industrial use. Our solution matches industrial needs as it can reliably differentiate similar classes of objects by using only 1 real image for training. To our best knowledge, this is the only work thus far satisfying these constraints.
Exploring Plausible Patches Using Source Code Embeddings in JavaScript
Mar 31, 2021


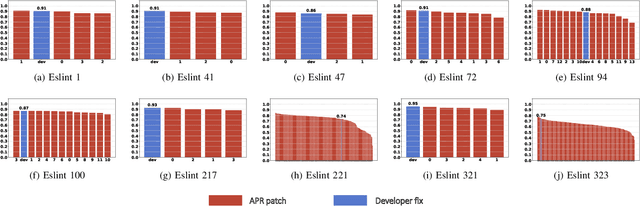
Despite the immense popularity of the Automated Program Repair (APR) field, the question of patch validation is still open. Most of the present-day approaches follow the so-called Generate-and-Validate approach, where first a candidate solution is being generated and after validated against an oracle. The latter, however, might not give a reliable result, because of the imperfections in such oracles; one of which is usually the test suite. Although (re-) running the test suite is right under one's nose, in real life applications the problem of over- and underfitting often occurs, resulting in inadequate patches. Efforts that have been made to tackle with this problem include patch filtering, test suite expansion, careful patch producing and many more. Most approaches to date use post-filtering relying either on test execution traces or make use of some similarity concept measured on the generated patches. Our goal is to investigate the nature of these similarity-based approaches. To do so, we trained a Doc2Vec model on an open-source JavaScript project and generated 465 patches for 10 bugs in it. These plausible patches alongside with the developer fix are then ranked based on their similarity to the original program. We analyzed these similarity lists and found that plain document embeddings may lead to misclassification - it fails to capture nuanced code semantics. Nevertheless, in some cases it also provided useful information, thus helping to better understand the area of Automated Program Repair.