 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Multiple Kernel Learning approaches for multi-omics data integration
Mar 27, 2024Advances in high-throughput technologies have originated an ever-increasing availability of omics datasets. The integration of multiple heterogeneous data sources is currently an issue for biology and bioinformatics. Multiple kernel learning (MKL) has shown to be a flexible and valid approach to consider the diverse nature of multi-omics inputs, despite being an underused tool in genomic data mining.We provide novel MKL approaches based on different kernel fusion strategies.To learn from the meta-kernel of input kernels, we adaptedunsupervised integration algorithms for supervised tasks with support vector machines.We also tested deep learning architectures for kernel fusion and classification.The results show that MKL-based models can compete with more complex, state-of-the-art, supervised multi-omics integrative approaches. Multiple kernel learning offers a natural framework for predictive models in multi-omics genomic data. Our results offer a direction for bio-data mining research and further development of methods for heterogeneous data integration.
Exploring Plausible Patches Using Source Code Embeddings in JavaScript
Mar 31, 2021


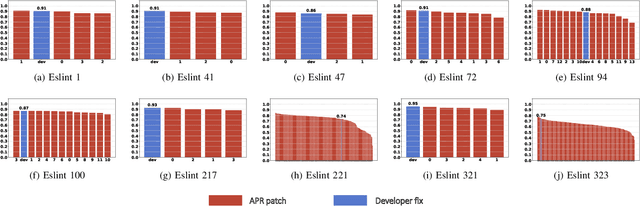
Despite the immense popularity of the Automated Program Repair (APR) field, the question of patch validation is still open. Most of the present-day approaches follow the so-called Generate-and-Validate approach, where first a candidate solution is being generated and after validated against an oracle. The latter, however, might not give a reliable result, because of the imperfections in such oracles; one of which is usually the test suite. Although (re-) running the test suite is right under one's nose, in real life applications the problem of over- and underfitting often occurs, resulting in inadequate patches. Efforts that have been made to tackle with this problem include patch filtering, test suite expansion, careful patch producing and many more. Most approaches to date use post-filtering relying either on test execution traces or make use of some similarity concept measured on the generated patches. Our goal is to investigate the nature of these similarity-based approaches. To do so, we trained a Doc2Vec model on an open-source JavaScript project and generated 465 patches for 10 bugs in it. These plausible patches alongside with the developer fix are then ranked based on their similarity to the original program. We analyzed these similarity lists and found that plain document embeddings may lead to misclassification - it fails to capture nuanced code semantics. Nevertheless, in some cases it also provided useful information, thus helping to better understand the area of Automated Program Repair.