 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Real Grasp Pose Estimation for Adaptive Robotic Applications
Nov 02, 2022Adaptive robotics plays an essential role in achieving truly co-creative cyber physical systems. In robotic manipulation tasks, one of the biggest challenges is to estimate the pose of given workpieces. Even though the recent deep-learning-based models show promising results, they require an immense dataset for training. In this paper, we propose two vision-based, multiobject grasp-pose estimation models, the MOGPE Real-Time (RT) and the MOGPE High-Precision (HP). Furthermore, a sim2real method based on domain randomization to diminish the reality gap and overcome the data shortage. We yielded an 80% and a 96.67% success rate in a real-world robotic pick-and-place experiment, with the MOGPE RT and the MOGPE HP model respectively. Our framework provides an industrial tool for fast data generation and model training and requires minimal domain-specific data.
Object Detection Using Sim2Real Domain Randomization for Robotic Applications
Aug 08, 2022

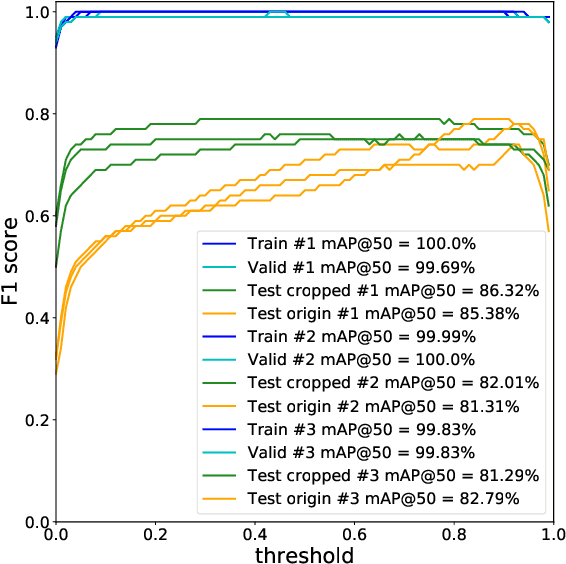

Robots working in unstructured environments must be capable of sensing and interpreting their surroundings. One of the main obstacles of deep learning based models in the field of robotics is the lack of domain-specific labeled data for different industrial applications. In this paper, we propose a sim2real transfer learning method based on domain randomization for object detection with which labeled synthetic datasets of arbitrary size and object types can be automatically generated. Subsequently, a state-of-the-art convolutional neural network, YOLOv4, is trained to detect the different types of industrial objects. With the proposed domain randomization method, we could shrink the reality gap to a satisfactory level, achieving 86.32% and 97.38% mAP50 scores respectively in the case of zero-shot and one-shot transfers, on our manually annotated dataset containing 190 real images. On a GeForce RTX 2080 Ti GPU, the data generation process takes less than 0.5s per image and the training lasts around 12h which makes it convenient for industrial use. Our solution matches industrial needs as it can reliably differentiate similar classes of objects by using only 1 real image for training. To our best knowledge, this is the only work thus far satisfying these constraints.