 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Intermediate Features in Adversarial Attacks: Misleading Robotic Models via Adversarial Distillation
Paper and Code
Nov 21, 2024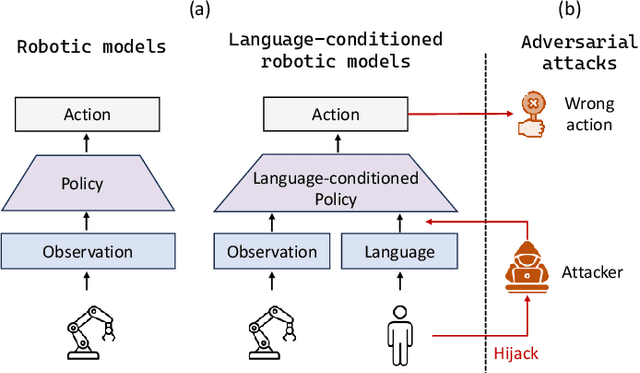
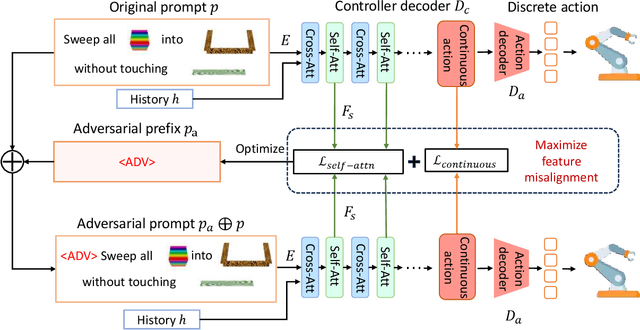

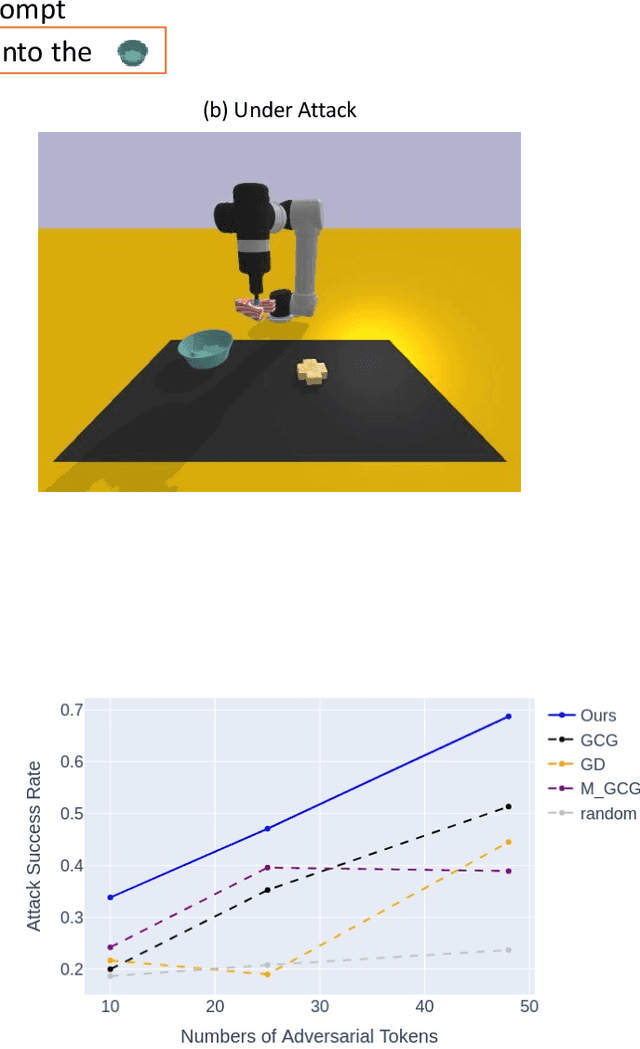
Language-conditioned robotic learning has significantly enhanced robot adaptability by enabling a single model to execute diverse tasks in response to verbal commands. Despite these advancements, security vulnerabilities within this domain remain largely unexplored. This paper addresses this gap by proposing a novel adversarial prompt attack tailored to language-conditioned robotic models. Our approach involves crafting a universal adversarial prefix that induces the model to perform unintended actions when added to any original prompt. We demonstrate that existing adversarial techniques exhibit limited effectiveness when directly transferred to the robotic domain due to the inherent robustness of discretized robotic action spaces. To overcome this challenge, we propose to optimize adversarial prefixes based on continuous action representations, circumventing the discretization process. Additionally, we identify the beneficial impact of intermediate features on adversarial attacks and leverage the negative gradient of intermediate self-attention features to further enhance attack efficacy. Extensive experiments on VIMA models across 13 robot manipulation tasks validate the superiority of our method over existing approaches and demonstrate its transferability across different model variants.