 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Hierarchical Crop Type Classification from Integrated Hyperspectral EnMAP Data and Multispectral Sentinel-2 Time Series: A Large-scale Dataset and Dual-stream Transformer Method
Jun 09, 2025Fine-grained crop type classification serves as the fundamental basis for large-scale crop mapping and plays a vital role in ensuring food security. It requires simultaneous capture of both phenological dynamics (obtained from multi-temporal satellite data like Sentinel-2) and subtle spectral variations (demanding nanometer-scale spectral resolution from hyperspectral imagery). Research combining these two modalities remains scarce currently due to challenges in hyperspectral data acquisition and crop types annotation costs. To address these issues, we construct a hierarchical hyperspectral crop dataset (H2Crop) by integrating 30m-resolution EnMAP hyperspectral data with Sentinel-2 time series. With over one million annotated field parcels organized in a four-tier crop taxonomy, H2Crop establishes a vital benchmark for fine-grained agricultural crop classification and hyperspectral image processing. We propose a dual-stream Transformer architecture that synergistically processes these modalities. It coordinates two specialized pathways: a spectral-spatial Transformer extracts fine-grained signatures from hyperspectral EnMAP data, while a temporal Swin Transformer extracts crop growth patterns from Sentinel-2 time series. The designed hierarchical classification head with hierarchical fusion then simultaneously delivers multi-level crop type classification across all taxonomic tiers. Experiments demonstrate that adding hyperspectral EnMAP data to Sentinel-2 time series yields a 4.2% average F1-scores improvement (peaking at 6.3%). Extensive comparisons also confirm our method's higher accuracy over existing deep learning approaches for crop type classification and the consistent benefits of hyperspectral data across varying temporal windows and crop change scenarios. Codes and dataset are available at https://github.com/flyakon/H2Crop.
A Novel Large-scale Crop Dataset and Dual-stream Transformer Method for Fine-grained Hierarchical Crop Classification from Integrated Hyperspectral EnMAP Data and Multispectral Sentinel-2 Time Series
Jun 06, 2025Fine-grained crop classification is crucial for precision agriculture and food security monitoring. It requires simultaneous capture of both phenological dynamics (obtained from multi-temporal satellite data like Sentinel-2) and subtle spectral variations (demanding nanometer-scale spectral resolution from hyperspectral imagery). Research combining these two modalities remains scarce currently due to challenges in hyperspectral data acquisition and crop types annotation costs. To address these issues, we construct a hierarchical hyperspectral crop dataset (H2Crop) by integrating 30m-resolution EnMAP hyperspectral data with Sentinel-2 time series. With over one million annotated field parcels organized in a four-tier crop taxonomy, H2Crop establishes a vital benchmark for fine-grained agricultural crop classification and hyperspectral image processing. We propose a dual-stream Transformer architecture that synergistically processes these modalities. It coordinates two specialized pathways: a spectral-spatial Transformer extracts fine-grained signatures from hyperspectral EnMAP data, while a temporal Swin Transformer extracts crop growth patterns from Sentinel-2 time series. The designed hierarchy classification heads with hierarchical fusion then simultaneously delivers multi-level classification across all taxonomic tiers. Experiments demonstrate that adding hyperspectral EnMAP data to Sentinel-2 time series yields a 4.2% average F1-scores improvement (peaking at 6.3%). Extensive comparisons also confirming our method's higher accuracy over existing deep learning approaches for crop type classification and the consistent benefits of hyperspectral data across varying temporal windows and crop change scenarios. Codes and dataset will be available at https://github.com/flyakon/H2Crop and www.glass.hku.hk Keywords: Crop type classification, precision agriculture, remote sensing, deep learning, hyperspectral data, Sentinel-2 time series, fine-grained crops
MetaEarth: A Generative Foundation Model for Global-Scale Remote Sensing Image Generation
May 22, 2024



The recent advancement of generative foundational models has ushered in a new era of image generation in the realm of natural images, revolutionizing art design, entertainment, environment simulation, and beyond. Despite producing high-quality samples, existing methods are constrained to generating images of scenes at a limited scale. In this paper, we present MetaEarth, a generative foundation model that breaks the barrier by scaling image generation to a global level, exploring the creation of worldwide, multi-resolution, unbounded, and virtually limitless remote sensing images. In MetaEarth, we propose a resolution-guided self-cascading generative framework, which enables the generating of images at any region with a wide range of geographical resolutions. To achieve unbounded and arbitrary-sized image generation, we design a novel noise sampling strategy for denoising diffusion models by analyzing the generation conditions and initial noise. To train MetaEarth, we construct a large dataset comprising multi-resolution optical remote sensing images with geographical information. Experiments have demonstrated the powerful capabilities of our method in generating global-scale images. Additionally, the MetaEarth serves as a data engine that can provide high-quality and rich training data for downstream tasks. Our model opens up new possibilities for constructing generative world models by simulating Earth visuals from an innovative overhead perspective.
Semantic decoupled representation learning for remote sensing image change detection
Jan 15, 2022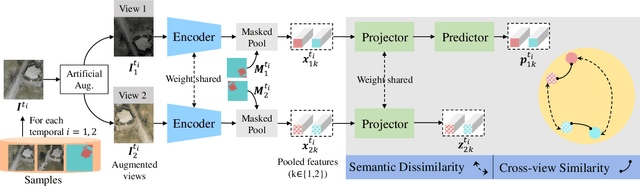
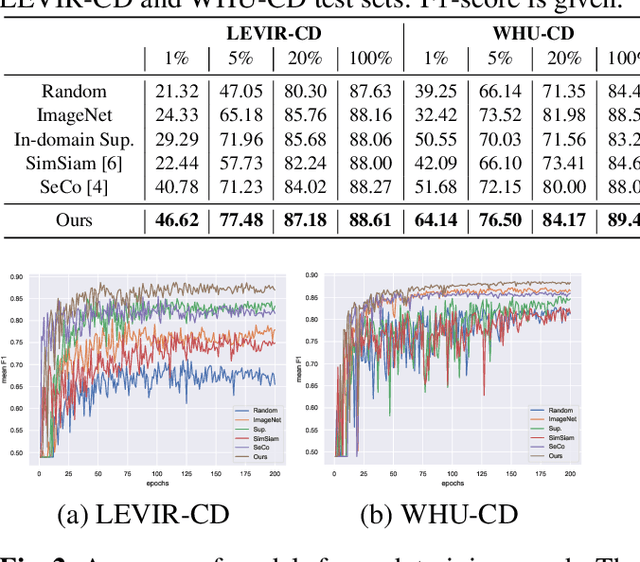
Contemporary transfer learning-based methods to alleviate the data insufficiency in change detection (CD) are mainly based on ImageNet pre-training. Self-supervised learning (SSL) has recently been introduced to remote sensing (RS) for learning in-domain representations. Here, we propose a semantic decoupled representation learning for RS image CD. Typically, the object of interest (e.g., building) is relatively small compared to the vast background. Different from existing methods expressing an image into one representation vector that may be dominated by irrelevant land-covers, we disentangle representations of different semantic regions by leveraging the semantic mask. We additionally force the model to distinguish different semantic representations, which benefits the recognition of objects of interest in the downstream CD task. We construct a dataset of bitemporal images with semantic masks in an effortless manner for pre-training. Experiments on two CD datasets show our model outperforms ImageNet pre-training, in-domain supervised pre-training, and several recent SSL methods.