 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSRefSeg 2: Decoupling Referring Remote Sensing Image Segmentation with Foundation Models
Jul 08, 2025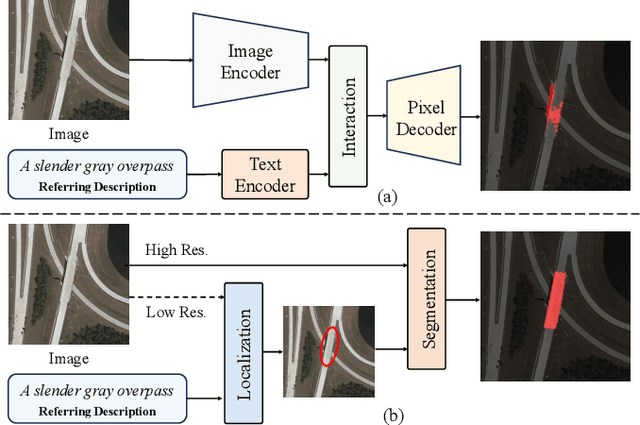
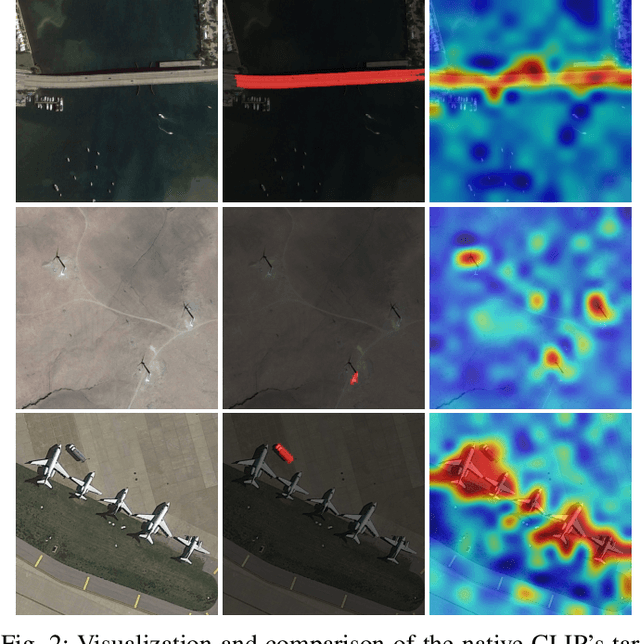
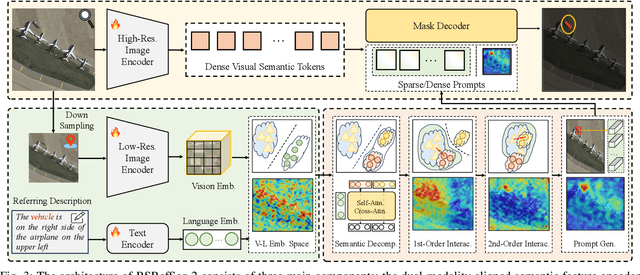
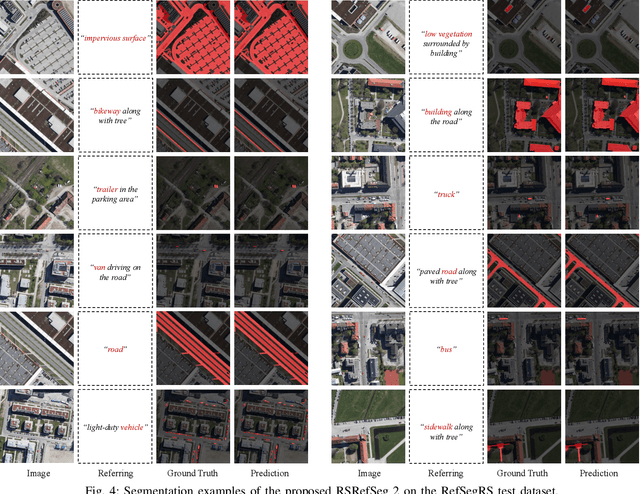
Referring Remote Sensing Image Segmentation provides a flexible and fine-grained framework for remote sensing scene analysis via vision-language collaborative interpretation. Current approaches predominantly utilize a three-stage pipeline encompassing dual-modal encoding, cross-modal interaction, and pixel decoding. These methods demonstrate significant limitations in managing complex semantic relationships and achieving precise cross-modal alignment, largely due to their coupled processing mechanism that conflates target localization with boundary delineation. This architectural coupling amplifies error propagation under semantic ambiguity while restricting model generalizability and interpretability. To address these issues, we propose RSRefSeg 2, a decoupling paradigm that reformulates the conventional workflow into a collaborative dual-stage framework: coarse localization followed by fine segmentation. RSRefSeg 2 integrates CLIP's cross-modal alignment strength with SAM's segmentation generalizability through strategic foundation model collaboration. Specifically, CLIP is employed as the dual-modal encoder to activate target features within its pre-aligned semantic space and generate localization prompts. To mitigate CLIP's misactivation challenges in multi-entity scenarios described by referring texts, a cascaded second-order prompter is devised, which enhances precision through implicit reasoning via decomposition of text embeddings into complementary semantic subspaces. These optimized semantic prompts subsequently direct the SAM to generate pixel-level refined masks, thereby completing the semantic transmission pipeline. Extensive experiments (RefSegRS, RRSIS-D, and RISBench) demonstrate that RSRefSeg 2 surpasses contemporary methods in segmentation accuracy (+~3% gIoU) and complex semantic interpretation. Code is available at: https://github.com/KyanChen/RSRefSeg2.
RSRefSeg: Referring Remote Sensing Image Segmentation with Foundation Models
Jan 12, 2025


Referring remote sensing image segmentation is crucial for achieving fine-grained visual understanding through free-format textual input, enabling enhanced scene and object extraction in remote sensing applications. Current research primarily utilizes pre-trained language models to encode textual descriptions and align them with visual modalities, thereby facilitating the expression of relevant visual features. However, these approaches often struggle to establish robust alignments between fine-grained semantic concepts, leading to inconsistent representations across textual and visual information. To address these limitations, we introduce a referring remote sensing image segmentation foundational model, RSRefSeg. RSRefSeg leverages CLIP for visual and textual encoding, employing both global and local textual semantics as filters to generate referring-related visual activation features in the latent space. These activated features then serve as input prompts for SAM, which refines the segmentation masks through its robust visual generalization capabilities. Experimental results on the RRSIS-D dataset demonstrate that RSRefSeg outperforms existing methods, underscoring the effectiveness of foundational models in enhancing multimodal task comprehension. The code is available at \url{https://github.com/KyanChen/RSRefSeg}.
Remote Sensing Temporal Vision-Language Models: A Comprehensive Survey
Dec 03, 2024



Temporal image analysis in remote sensing has traditionally centered on change detection, which identifies regions of change between images captured at different times. However, change detection remains limited by its focus on visual-level interpretation, often lacking contextual or descriptive information. The rise of Vision-Language Models (VLMs) has introduced a new dimension to remote sensing temporal image analysis by integrating visual information with natural language, creating an avenue for advanced interpretation of temporal image changes. Remote Sensing Temporal VLMs (RSTVLMs) allow for dynamic interactions, generating descriptive captions, answering questions, and providing a richer semantic understanding of temporal images. This temporal vision-language capability is particularly valuable for complex remote sensing applications, where higher-level insights are crucial. This paper comprehensively reviews the progress of RSTVLM research, with a focus on the latest VLM applications for temporal image analysis. We categorize and discuss core methodologies, datasets, and metrics, highlight recent advances in temporal vision-language tasks, and outline key challenges and future directions for research in this emerging field. This survey fills a critical gap in the literature by providing an integrated overview of RSTVLM, offering a foundation for further advancements in remote sensing temporal image understanding. We will keep tracing related works at \url{https://github.com/Chen-Yang-Liu/Awesome-RS-Temporal-VLM}