 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedVAR: Towards Scalable and Efficient Medical Image Generation via Next-scale Autoregressive Prediction
Feb 16, 2026Medical image generation is pivotal in applications like data augmentation for low-resource clinical tasks and privacy-preserving data sharing. However, developing a scalable generative backbone for medical imaging requires architectural efficiency, sufficient multi-organ data, and principled evaluation, yet current approaches leave these aspects unresolved. Therefore, we introduce MedVAR, the first autoregressive-based foundation model that adopts the next-scale prediction paradigm to enable fast and scale-up-friendly medical image synthesis. MedVAR generates images in a coarse-to-fine manner and produces structured multi-scale representations suitable for downstream use. To support hierarchical generation, we curate a harmonized dataset of around 440,000 CT and MRI images spanning six anatomical regions. Comprehensive experiments across fidelity, diversity, and scalability show that MedVAR achieves state-of-the-art generative performance and offers a promising architectural direction for future medical generative foundation models.
PulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
Unleashing the Power of Image-Tabular Self-Supervised Learning via Breaking Cross-Tabular Barriers
Dec 16, 2025Multi-modal learning integrating medical images and tabular data has significantly advanced clinical decision-making in recent years. Self-Supervised Learning (SSL) has emerged as a powerful paradigm for pretraining these models on large-scale unlabeled image-tabular data, aiming to learn discriminative representations. However, existing SSL methods for image-tabular representation learning are often confined to specific data cohorts, mainly due to their rigid tabular modeling mechanisms when modeling heterogeneous tabular data. This inter-tabular barrier hinders the multi-modal SSL methods from effectively learning transferrable medical knowledge shared across diverse cohorts. In this paper, we propose a novel SSL framework, namely CITab, designed to learn powerful multi-modal feature representations in a cross-tabular manner. We design the tabular modeling mechanism from a semantic-awareness perspective by integrating column headers as semantic cues, which facilitates transferrable knowledge learning and the scalability in utilizing multiple data sources for pretraining. Additionally, we propose a prototype-guided mixture-of-linear layer (P-MoLin) module for tabular feature specialization, empowering the model to effectively handle the heterogeneity of tabular data and explore the underlying medical concepts. We conduct comprehensive evaluations on Alzheimer's disease diagnosis task across three publicly available data cohorts containing 4,461 subjects. Experimental results demonstrate that CITab outperforms state-of-the-art approaches, paving the way for effective and scalable cross-tabular multi-modal learning.
Does Training with Synthetic Data Truly Protect Privacy?
Feb 18, 2025As synthetic data becomes increasingly popular in machine learning tasks, numerous methods--without formal differential privacy guarantees--use synthetic data for training. These methods often claim, either explicitly or implicitly, to protect the privacy of the original training data. In this work, we explore four different training paradigms: coreset selection, dataset distillation, data-free knowledge distillation, and synthetic data generated from diffusion models. While all these methods utilize synthetic data for training, they lead to vastly different conclusions regarding privacy preservation. We caution that empirical approaches to preserving data privacy require careful and rigorous evaluation; otherwise, they risk providing a false sense of privacy.
Community Detection with Heterogeneous Block Covariance Model
Dec 04, 2024Community detection is the task of clustering objects based on their pairwise relationships. Most of the model-based community detection methods, such as the stochastic block model and its variants, are designed for networks with binary (yes/no) edges. In many practical scenarios, edges often possess continuous weights, spanning positive and negative values, which reflect varying levels of connectivity. To address this challenge, we introduce the heterogeneous block covariance model (HBCM) that defines a community structure within the covariance matrix, where edges have signed and continuous weights. Furthermore, it takes into account the heterogeneity of objects when forming connections with other objects within a community. A novel variational expectation-maximization algorithm is proposed to estimate the group membership. The HBCM provides provable consistent estimates of memberships, and its promising performance is observed in numerical simulations with different setups. The model is applied to a single-cell RNA-seq dataset of a mouse embryo and a stock price dataset. Supplementary materials for this article are available online.
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Jun 04, 2024



Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
Spatial Temporal Graph Convolution with Graph Structure Self-learning for Early MCI Detection
Nov 11, 2022



Graph neural networks (GNNs) have been successfully applied to early mild cognitive impairment (EMCI) detection, with the usage of elaborately designed features constructed from blood oxygen level-dependent (BOLD) time series. However, few works explored the feasibility of using BOLD signals directly as features. Meanwhile, existing GNN-based methods primarily rely on hand-crafted explicit brain topology as the adjacency matrix, which is not optimal and ignores the implicit topological organization of the brain. In this paper, we propose a spatial temporal graph convolutional network with a novel graph structure self-learning mechanism for EMCI detection. The proposed spatial temporal graph convolution block directly exploits BOLD time series as input features, which provides an interesting view for rsfMRI-based preclinical AD diagnosis. Moreover, our model can adaptively learn the optimal topological structure and refine edge weights with the graph structure self-learning mechanism. Results on the Alzheimer's Disease Neuroimaging Initiative (ADNI) database show that our method outperforms state-of-the-art approaches. Biomarkers consistent with previous studies can be extracted from the model, proving the reliable interpretability of our method.
Variational Estimators of the Degree-corrected Latent Block Model for Bipartite Networks
Jun 16, 2022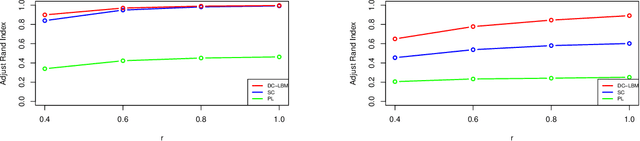
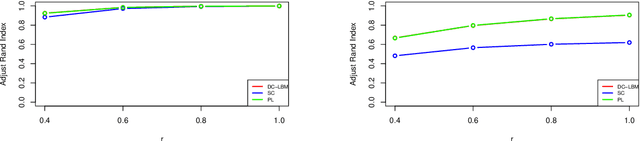


Biclustering on bipartite graphs is an unsupervised learning task that simultaneously clusters the two types of objects in the graph, for example, users and movies in a movie review dataset. The latent block model (LBM) has been proposed as a model-based tool for biclustering. Biclustering results by the LBM are, however, usually dominated by the row and column sums of the data matrix, i.e., degrees. We propose a degree-corrected latent block model (DC-LBM) to accommodate degree heterogeneity in row and column clusters, which greatly outperforms the classical LBM in the MovieLens dataset and simulated data. We develop an efficient variational expectation-maximization algorithm by observing that the row and column degrees maximize the objective function in the M step given any probability assignment on the cluster labels. We prove the label consistency of the variational estimator under the DC-LBM, which allows the expected graph density goes to zero as long as the average expected degrees of rows and columns go to infinity.
Deep Learning Models in Detection of Dietary Supplement Adverse Event Signals from Twitter
Jun 21, 2021

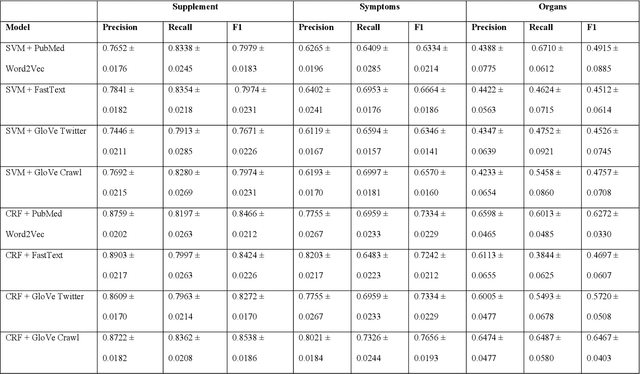

Objective: The objective of this study is to develop a deep learning pipeline to detect signals on dietary supplement-related adverse events (DS AEs) from Twitter. Material and Methods: We obtained 247,807 tweets ranging from 2012 to 2018 that mentioned both DS and AE. We annotated biomedical entities and relations on 2,000 randomly selected tweets. For the concept extraction task, we compared the performance of traditional word embeddings with SVM, CRF and LSTM-CRF classifiers to BERT models. For the relation extraction task, we compared GloVe vectors with CNN classifiers to BERT models. We chose the best performing models in each task to assemble an end-to-end deep learning pipeline to detect DS AE signals and compared the results to the known DS AEs from a DS knowledge base (i.e., iDISK). Results: In both tasks, the BERT-based models outperformed traditional word embeddings. The best performing concept extraction model is the BioBERT model that can identify supplement, symptom, and body organ entities with F1-scores of 0.8646, 0.8497, and 0.7104, respectively. The best performing relation extraction model is the BERT model that can identify purpose and AE relations with F1-scores of 0.8335 and 0.7538, respectively. The end-to-end pipeline was able to extract DS indication and DS AEs with an F1-score of 0.7459 and 0,7414, respectively. Comparing to the iDISK, we could find both known and novel DS-AEs. Conclusion: We have demonstrated the feasibility of detecting DS AE signals from Twitter with a BioBERT-based deep learning pipeline.
Identifiability and consistency of network inference using the hub model and variants: a restricted class of Bernoulli mixture models
Apr 22, 2020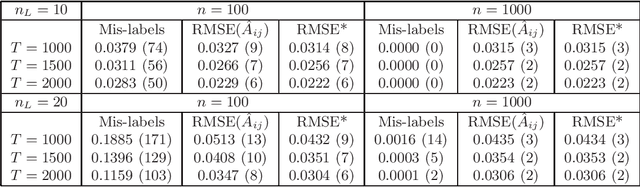
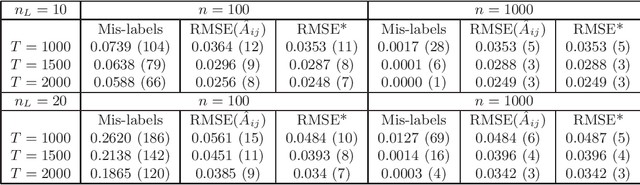
Statistical network analysis primarily focuses on inferring the parameters of an observed network. In many applications, especially in the social sciences, the observed data is the groups formed by individual subjects. In these applications, the network is itself a parameter of a statistical model. Zhao and Weko (2019) propose a model-based approach, called the hub model, to infer implicit networks from grouping behavior. The hub model assumes that each member of the group is brought together by a member of the group called the hub. The hub model belongs to the family of Bernoulli mixture models. Identifiability of parameters is a notoriously difficult problem for Bernoulli mixture models. This paper proves identifiability of the hub model parameters and estimation consistency under mild conditions. Furthermore, this paper generalizes the hub model by introducing a model component that allows hubless groups in which individual nodes spontaneously appear independent of any other individual. We refer to this additional component as the null component. The new model bridges the gap between the hub model and the degenerate case of the mixture model -- the Bernoulli product. Identifiability and consistency are also proved for the new model. Numerical studies are provided to demonstrate the theoretical results.