 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Multimodal Fact-Checking and Explanation Generation: A Challenging Dataset and Models
Paper and Code
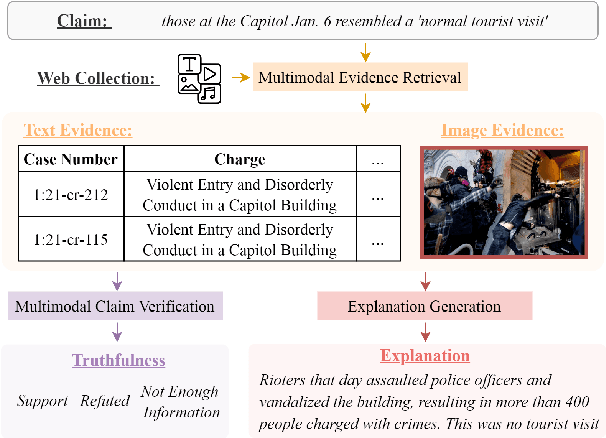
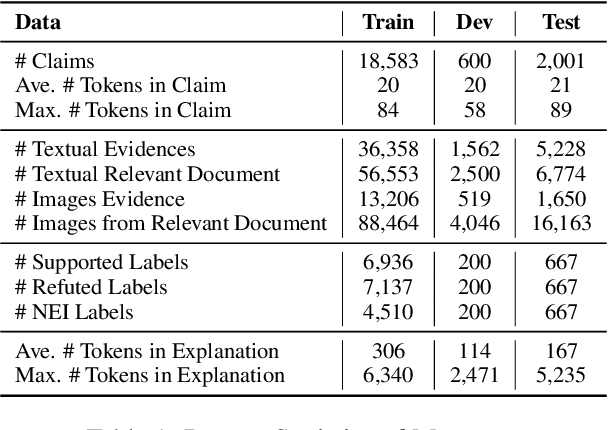
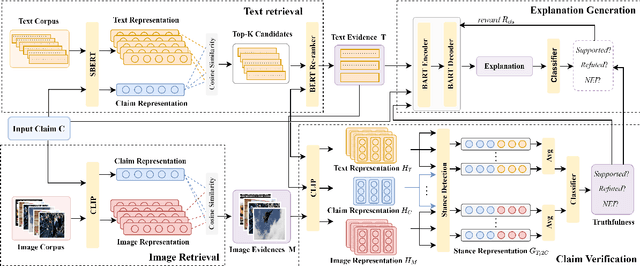
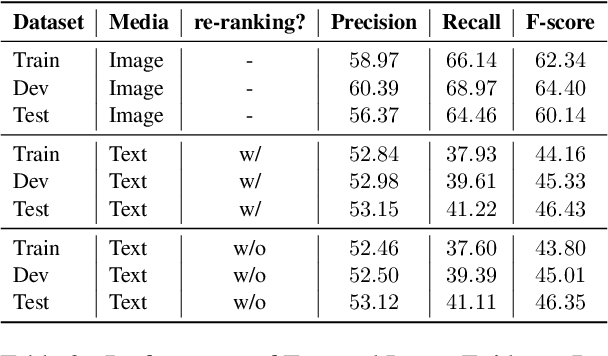
We propose the end-to-end multimodal fact-checking and explanation generation, where the input is a claim and a large collection of web sources, including articles, images, videos, and tweets, and the goal is to assess the truthfulness of the claim by retrieving relevant evidence and predicting a truthfulness label (i.e., support, refute and not enough information), and generate a rationalization statement to explain the reasoning and ruling process. To support this research, we construct Mocheg, a large-scale dataset that consists of 21,184 claims where each claim is assigned with a truthfulness label and ruling statement, with 58,523 evidence in the form of text and images. To establish baseline performances on Mocheg, we experiment with several state-of-the-art neural architectures on the three pipelined subtasks: multimodal evidence retrieval, claim verification, and explanation generation, and demonstrate the current state-of-the-art performance of end-to-end multimodal fact-checking is still far from satisfying. To the best of our knowledge, we are the first to build the benchmark dataset and solutions for end-to-end multimodal fact-checking and justification.