 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Good, the Bad, and the Ugly of Markov Boundary for Tabular Prediction
May 28, 2026Under standard graphical assumptions, the Markov boundary of a target variable is the smallest set of features that renders every other feature redundant. Once the boundary is observed, the target is conditionally independent of the rest of the table. This is a tempting object for tabular prediction, since it names exactly the columns a model should need. Yet modern regressors are still trained on the full feature set. We ask whether the Markov boundary is genuinely useful for prediction on SCM3K, a 3,450-task synthetic SCM benchmark with feature counts from 40 to 1000 and six SCM families, evaluated with six regressors. The answer is more nuanced than the theory suggests. Restricting a regressor to the oracle boundary often improves prediction substantially, and the improvement grows as the feature space becomes larger and sparser. But the natural pipeline of recovering the boundary with causal discovery and training on the recovered mask does not deliver. Existing estimators exhaust the compute budget before reaching the regime where the boundary helps most, and even where they run they rarely beat the full feature set. We trace this to three causes. Discovery optimizes structural recovery rather than prediction. False negatives and false positives carry sharply asymmetric predictive cost. The exact boundary is only one of many feature sets that beat all features. We then develop what these facts imply for prediction-aligned feature selection and for tabular models that learn to use causal structure.
CauSTream: Causal Spatio-Temporal Representation Learning for Streamflow Forecasting
Dec 18, 2025Streamflow forecasting is crucial for water resource management and risk mitigation. While deep learning models have achieved strong predictive performance, they often overlook underlying physical processes, limiting interpretability and generalization. Recent causal learning approaches address these issues by integrating domain knowledge, yet they typically rely on fixed causal graphs that fail to adapt to data. We propose CauStream, a unified framework for causal spatiotemporal streamflow forecasting. CauSTream jointly learns (i) a runoff causal graph among meteorological forcings and (ii) a routing graph capturing dynamic dependencies across stations. We further establish identifiability conditions for these causal structures under a nonparametric setting. We evaluate CauSTream on three major U.S. river basins across three forecasting horizons. The model consistently outperforms prior state-of-the-art methods, with performance gaps widening at longer forecast windows, indicating stronger generalization to unseen conditions. Beyond forecasting, CauSTream also learns causal graphs that capture relationships among hydrological factors and stations. The inferred structures align closely with established domain knowledge, offering interpretable insights into watershed dynamics. CauSTream offers a principled foundation for causal spatiotemporal modeling, with the potential to extend to a wide range of scientific and environmental applications.
Causality Guided Representation Learning for Cross-Style Hate Speech Detection
Oct 09, 2025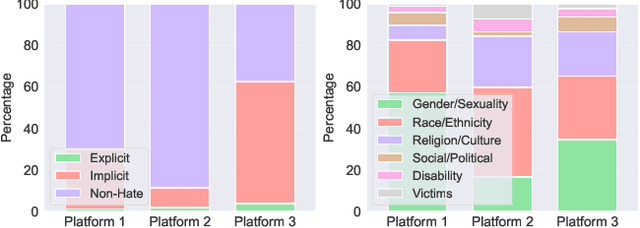
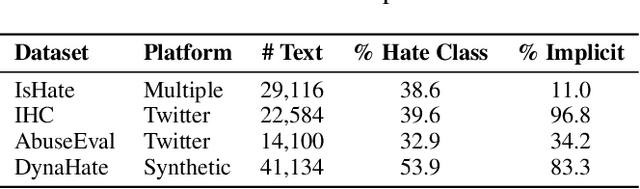
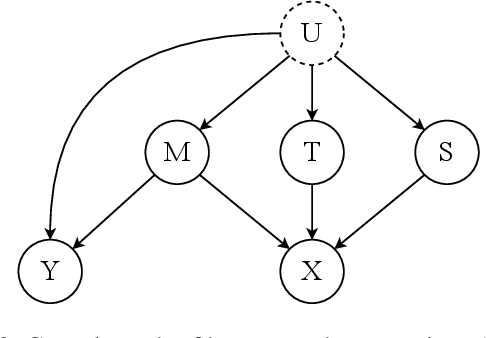
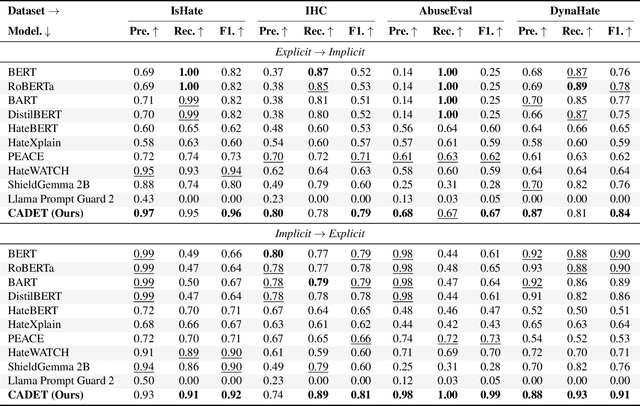
The proliferation of online hate speech poses a significant threat to the harmony of the web. While explicit hate is easily recognized through overt slurs, implicit hate speech is often conveyed through sarcasm, irony, stereotypes, or coded language -- making it harder to detect. Existing hate speech detection models, which predominantly rely on surface-level linguistic cues, fail to generalize effectively across diverse stylistic variations. Moreover, hate speech spread on different platforms often targets distinct groups and adopts unique styles, potentially inducing spurious correlations between them and labels, further challenging current detection approaches. Motivated by these observations, we hypothesize that the generation of hate speech can be modeled as a causal graph involving key factors: contextual environment, creator motivation, target, and style. Guided by this graph, we propose CADET, a causal representation learning framework that disentangles hate speech into interpretable latent factors and then controls confounders, thereby isolating genuine hate intent from superficial linguistic cues. Furthermore, CADET allows counterfactual reasoning by intervening on style within the latent space, naturally guiding the model to robustly identify hate speech in varying forms. CADET demonstrates superior performance in comprehensive experiments, highlighting the potential of causal priors in advancing generalizable hate speech detection.
Cross-Domain Conditional Diffusion Models for Time Series Imputation
Jun 14, 2025Cross-domain time series imputation is an underexplored data-centric research task that presents significant challenges, particularly when the target domain suffers from high missing rates and domain shifts in temporal dynamics. Existing time series imputation approaches primarily focus on the single-domain setting, which cannot effectively adapt to a new domain with domain shifts. Meanwhile, conventional domain adaptation techniques struggle with data incompleteness, as they typically assume the data from both source and target domains are fully observed to enable adaptation. For the problem of cross-domain time series imputation, missing values introduce high uncertainty that hinders distribution alignment, making existing adaptation strategies ineffective. Specifically, our proposed solution tackles this problem from three perspectives: (i) Data: We introduce a frequency-based time series interpolation strategy that integrates shared spectral components from both domains while retaining domain-specific temporal structures, constructing informative priors for imputation. (ii) Model: We design a diffusion-based imputation model that effectively learns domain-shared representations and captures domain-specific temporal dependencies with dedicated denoising networks. (iii) Algorithm: We further propose a cross-domain consistency alignment strategy that selectively regularizes output-level domain discrepancies, enabling effective knowledge transfer while preserving domain-specific characteristics. Extensive experiments on three real-world datasets demonstrate the superiority of our proposed approach. Our code implementation is available here.
Introducing CausalBench: A Flexible Benchmark Framework for Causal Analysis and Machine Learning
Sep 12, 2024


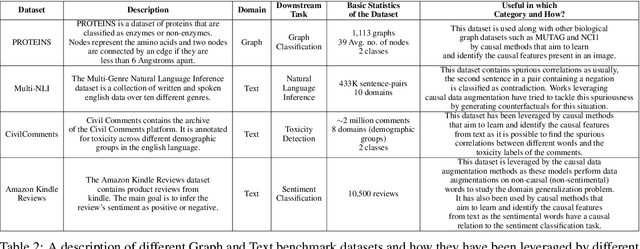
While witnessing the exceptional success of machine learning (ML) technologies in many applications, users are starting to notice a critical shortcoming of ML: correlation is a poor substitute for causation. The conventional way to discover causal relationships is to use randomized controlled experiments (RCT); in many situations, however, these are impractical or sometimes unethical. Causal learning from observational data offers a promising alternative. While being relatively recent, causal learning aims to go far beyond conventional machine learning, yet several major challenges remain. Unfortunately, advances are hampered due to the lack of unified benchmark datasets, algorithms, metrics, and evaluation service interfaces for causal learning. In this paper, we introduce {\em CausalBench}, a transparent, fair, and easy-to-use evaluation platform, aiming to (a) enable the advancement of research in causal learning by facilitating scientific collaboration in novel algorithms, datasets, and metrics and (b) promote scientific objectivity, reproducibility, fairness, and awareness of bias in causal learning research. CausalBench provides services for benchmarking data, algorithms, models, and metrics, impacting the needs of a broad of scientific and engineering disciplines.
Domain Generalization -- A Causal Perspective
Sep 30, 2022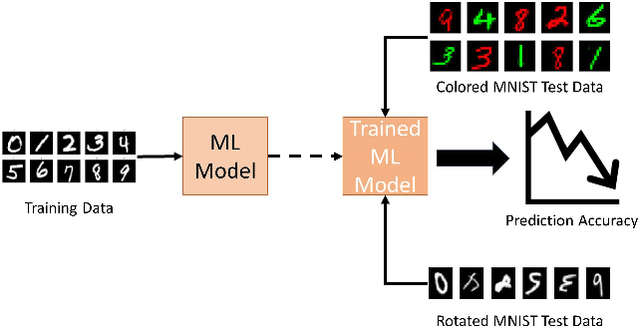
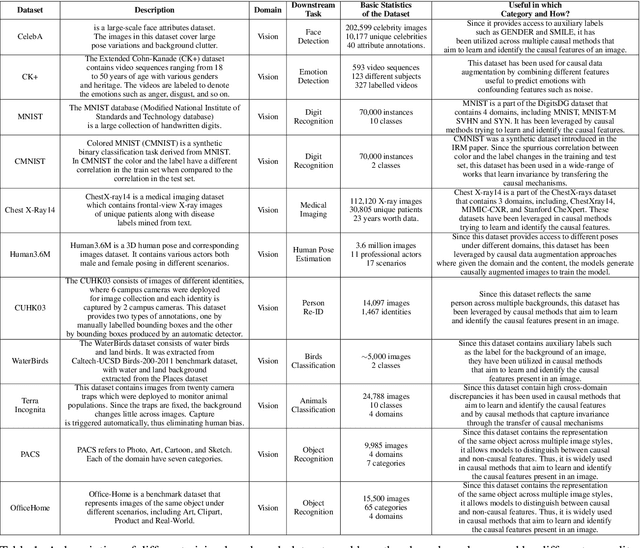
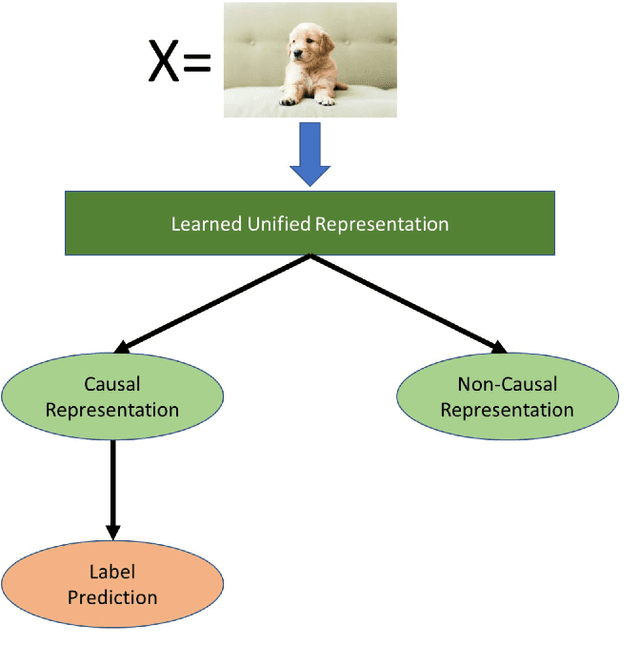
Machine learning models have gained widespread success, from healthcare to personalized recommendations. One of the preliminary assumptions of these models is the independent and identical distribution. Therefore, the train and test data are sampled from the same observation per this assumption. However, this assumption seldom holds in the real world due to distribution shifts. Since the models rely heavily on this assumption, they exhibit poor generalization capabilities. Over the recent years, dedicated efforts have been made to improve the generalization capabilities of these models. The primary idea behind these methods is to identify stable features or mechanisms that remain invariant across the different distributions. Many generalization approaches employ causal theories to describe invariance since causality and invariance are inextricably intertwined. However, current surveys deal with the causality-aware domain generalization methods on a very high-level. Furthermore, none of the existing surveys categorize the causal domain generalization methods based on the problem and causal theories these methods leverage. To this end, we present a comprehensive survey on causal domain generalization models from the aspects of the problem and causal theories. Furthermore, this survey includes in-depth insights into publicly accessible datasets and benchmarks for domain generalization in various domains. Finally, we conclude the survey with insights and discussions on future research directions. Finally, we conclude the survey with insights and discussions on future research directions.
Causal Disentanglement with Network Information for Debiased Recommendations
Apr 14, 2022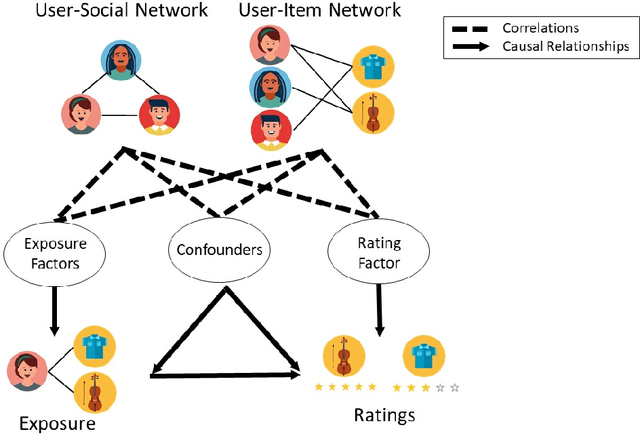

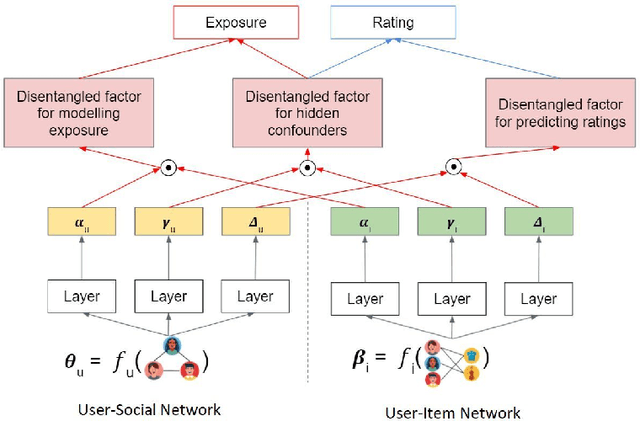

Recommender systems aim to recommend new items to users by learning user and item representations. In practice, these representations are highly entangled as they consist of information about multiple factors, including user's interests, item attributes along with confounding factors such as user conformity, and item popularity. Considering these entangled representations for inferring user preference may lead to biased recommendations (e.g., when the recommender model recommends popular items even if they do not align with the user's interests). Recent research proposes to debias by modeling a recommender system from a causal perspective. The exposure and the ratings are analogous to the treatment and the outcome in the causal inference framework, respectively. The critical challenge in this setting is accounting for the hidden confounders. These confounders are unobserved, making it hard to measure them. On the other hand, since these confounders affect both the exposure and the ratings, it is essential to account for them in generating debiased recommendations. To better approximate hidden confounders, we propose to leverage network information (i.e., user-social and user-item networks), which are shown to influence how users discover and interact with an item. Aside from the user conformity, aspects of confounding such as item popularity present in the network information is also captured in our method with the aid of \textit{causal disentanglement} which unravels the learned representations into independent factors that are responsible for (a) modeling the exposure of an item to the user, (b) predicting the ratings, and (c) controlling the hidden confounders. Experiments on real-world datasets validate the effectiveness of the proposed model for debiasing recommender systems.