 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaDi-WM: A Latent Diffusion-based World Model for Predictive Manipulation
May 13, 2025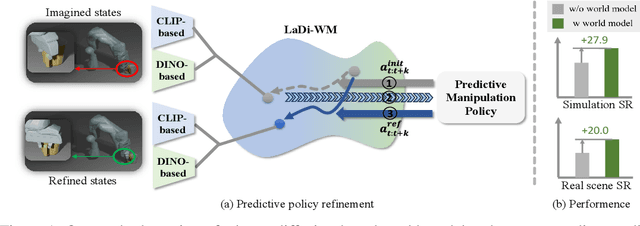
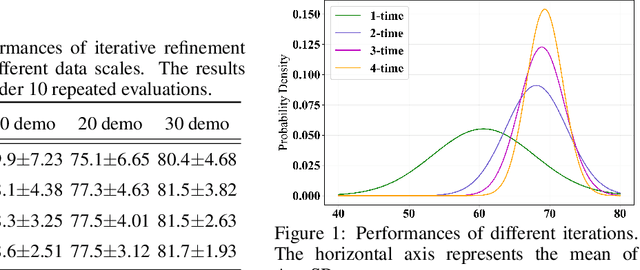

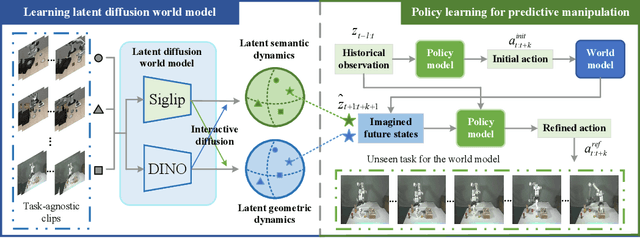
Predictive manipulation has recently gained considerable attention in the Embodied AI community due to its potential to improve robot policy performance by leveraging predicted states. However, generating accurate future visual states of robot-object interactions from world models remains a well-known challenge, particularly in achieving high-quality pixel-level representations. To this end, we propose LaDi-WM, a world model that predicts the latent space of future states using diffusion modeling. Specifically, LaDi-WM leverages the well-established latent space aligned with pre-trained Visual Foundation Models (VFMs), which comprises both geometric features (DINO-based) and semantic features (CLIP-based). We find that predicting the evolution of the latent space is easier to learn and more generalizable than directly predicting pixel-level images. Building on LaDi-WM, we design a diffusion policy that iteratively refines output actions by incorporating forecasted states, thereby generating more consistent and accurate results. Extensive experiments on both synthetic and real-world benchmarks demonstrate that LaDi-WM significantly enhances policy performance by 27.9\% on the LIBERO-LONG benchmark and 20\% on the real-world scenario. Furthermore, our world model and policies achieve impressive generalizability in real-world experiments.
Learning Part-aware 3D Representations by Fusing 2D Gaussians and Superquadrics
Aug 20, 2024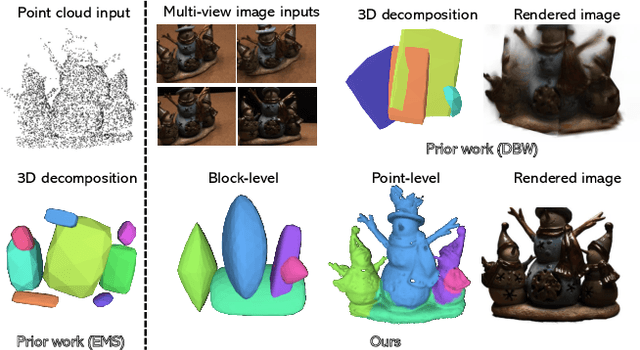

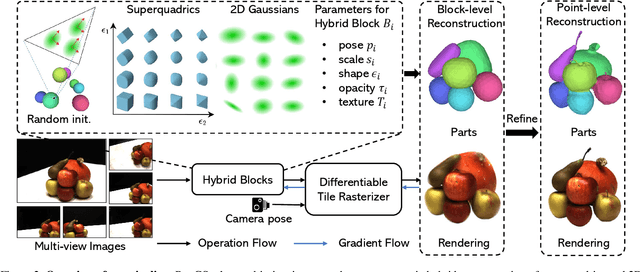
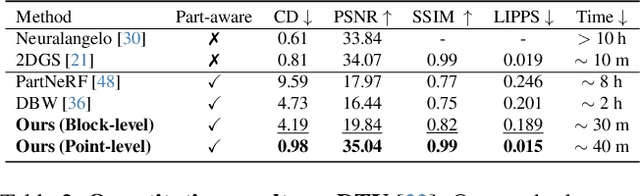
Low-level 3D representations, such as point clouds, meshes, NeRFs, and 3D Gaussians, are commonly used to represent 3D objects or scenes. However, humans usually perceive 3D objects or scenes at a higher level as a composition of parts or structures rather than points or voxels. Representing 3D as semantic parts can benefit further understanding and applications. We aim to solve part-aware 3D reconstruction, which parses objects or scenes into semantic parts. In this paper, we introduce a hybrid representation of superquadrics and 2D Gaussians, trying to dig 3D structural clues from multi-view image inputs. Accurate structured geometry reconstruction and high-quality rendering are achieved at the same time. We incorporate parametric superquadrics in mesh forms into 2D Gaussians by attaching Gaussian centers to faces in meshes. During the training, superquadrics parameters are iteratively optimized, and Gaussians are deformed accordingly, resulting in an efficient hybrid representation. On the one hand, this hybrid representation inherits the advantage of superquadrics to represent different shape primitives, supporting flexible part decomposition of scenes. On the other hand, 2D Gaussians are incorporated to model the complex texture and geometry details, ensuring high-quality rendering and geometry reconstruction. The reconstruction is fully unsupervised. We conduct extensive experiments on data from DTU and ShapeNet datasets, in which the method decomposes scenes into reasonable parts, outperforming existing state-of-the-art approaches.
DISCO: Efficient Diffusion Solver for Large-Scale Combinatorial Optimization Problems
Jun 28, 2024Combinatorial Optimization (CO) problems are fundamentally crucial in numerous practical applications across diverse industries, characterized by entailing enormous solution space and demanding time-sensitive response. Despite significant advancements made by recent neural solvers, their limited expressiveness does not conform well to the multi-modal nature of CO landscapes. While some research has pivoted towards diffusion models, they require simulating a Markov chain with many steps to produce a sample, which is time-consuming and does not meet the efficiency requirement of real applications, especially at scale. We propose DISCO, an efficient DIffusion Solver for Combinatorial Optimization problems that excels in both solution quality and inference speed. DISCO's efficacy is two-pronged: Firstly, it achieves rapid denoising of solutions through an analytically solvable form, allowing for direct sampling from the solution space with very few reverse-time steps, thereby drastically reducing inference time. Secondly, DISCO enhances solution quality by restricting the sampling space to a more constrained, meaningful domain guided by solution residues, while still preserving the inherent multi-modality of the output probabilistic distributions. DISCO achieves state-of-the-art results on very large Traveling Salesman Problems with 10000 nodes and challenging Maximal Independent Set benchmarks, with its per-instance denoising time up to 44.8 times faster. Through further combining a divide-and-conquer strategy, DISCO can be generalized to solve arbitrary-scale problem instances off the shelf, even outperforming models trained specifically on corresponding scales.
Part-aware Shape Generation with Latent 3D Diffusion of Neural Voxel Fields
May 02, 2024This paper presents a novel latent 3D diffusion model for the generation of neural voxel fields, aiming to achieve accurate part-aware structures. Compared to existing methods, there are two key designs to ensure high-quality and accurate part-aware generation. On one hand, we introduce a latent 3D diffusion process for neural voxel fields, enabling generation at significantly higher resolutions that can accurately capture rich textural and geometric details. On the other hand, a part-aware shape decoder is introduced to integrate the part codes into the neural voxel fields, guiding the accurate part decomposition and producing high-quality rendering results. Through extensive experimentation and comparisons with state-of-the-art methods, we evaluate our approach across four different classes of data. The results demonstrate the superior generative capabilities of our proposed method in part-aware shape generation, outperforming existing state-of-the-art methods.
Exploring the Distinctiveness and Fidelity of the Descriptions Generated by Large Vision-Language Models
Apr 26, 2024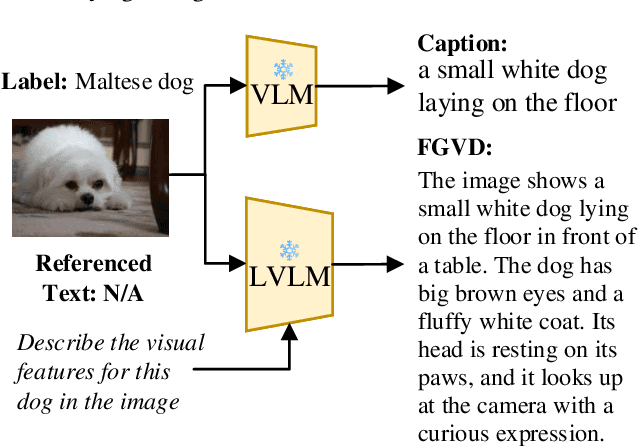
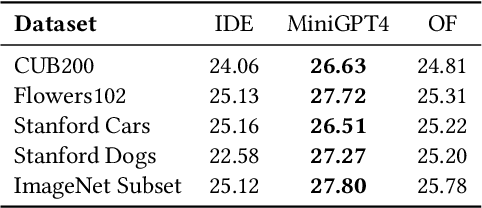
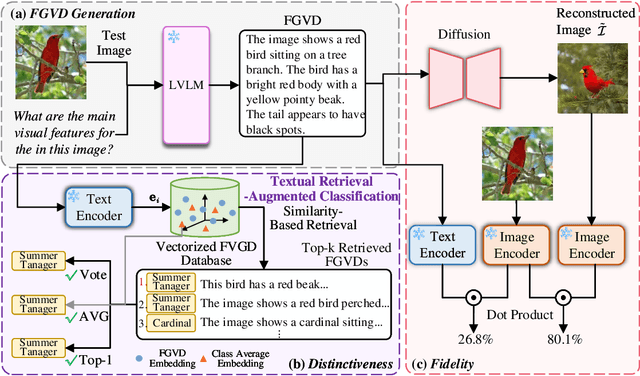
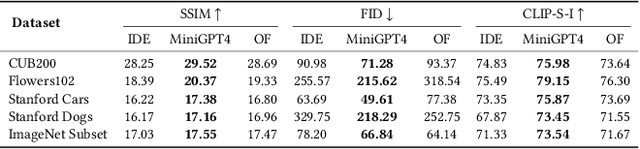
Large Vision-Language Models (LVLMs) are gaining traction for their remarkable ability to process and integrate visual and textual data. Despite their popularity, the capacity of LVLMs to generate precise, fine-grained textual descriptions has not been fully explored. This study addresses this gap by focusing on \textit{distinctiveness} and \textit{fidelity}, assessing how models like Open-Flamingo, IDEFICS, and MiniGPT-4 can distinguish between similar objects and accurately describe visual features. We proposed the Textual Retrieval-Augmented Classification (TRAC) framework, which, by leveraging its generative capabilities, allows us to delve deeper into analyzing fine-grained visual description generation. This research provides valuable insights into the generation quality of LVLMs, enhancing the understanding of multimodal language models. Notably, MiniGPT-4 stands out for its better ability to generate fine-grained descriptions, outperforming the other two models in this aspect. The code is provided at \url{https://anonymous.4open.science/r/Explore_FGVDs-E277}.
DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
Mar 04, 2024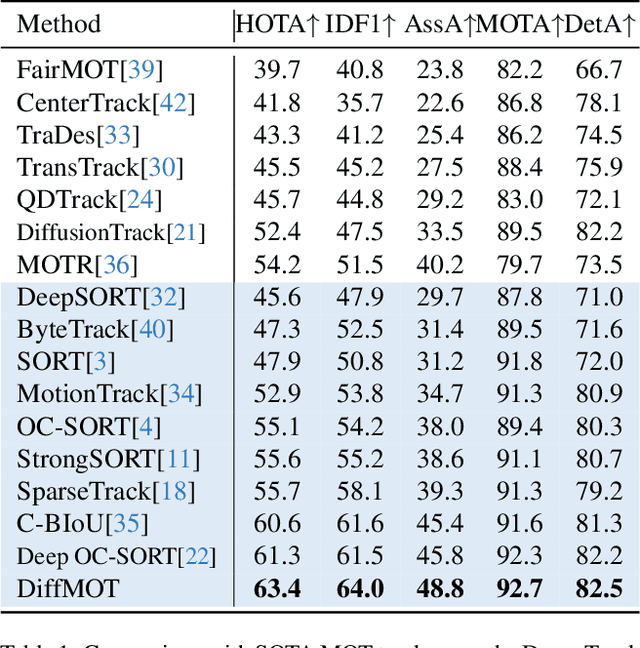
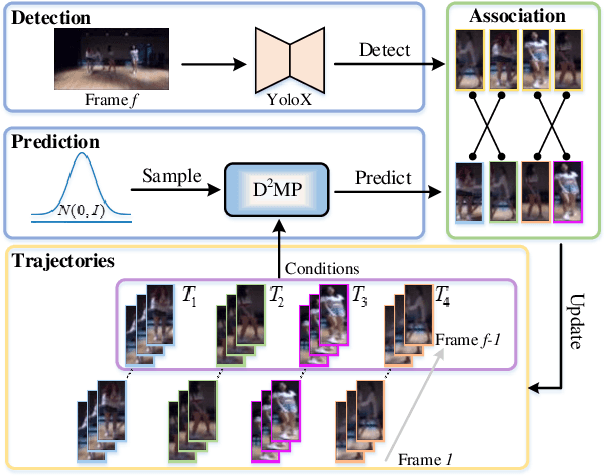
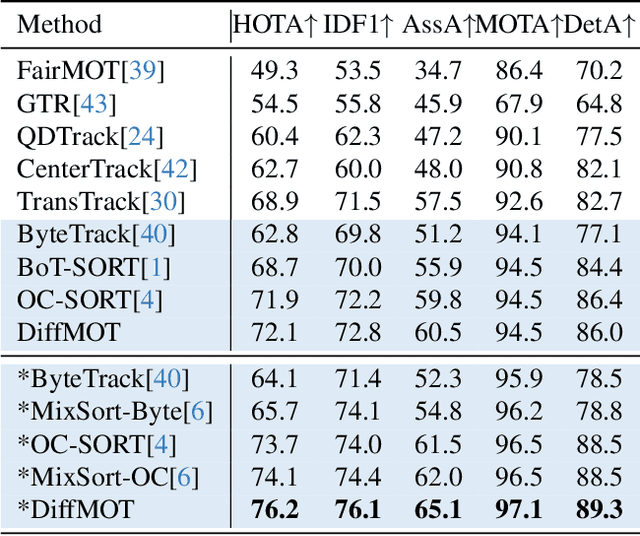
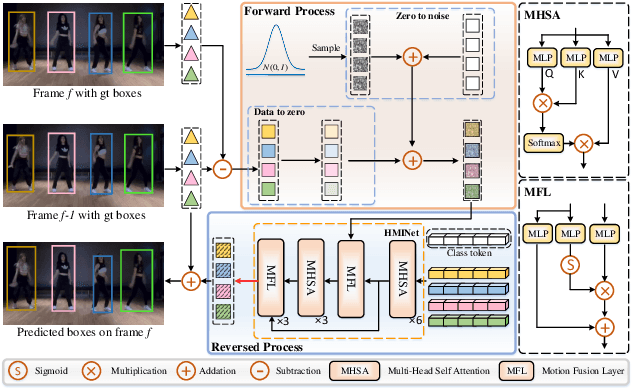
In Multiple Object Tracking, objects often exhibit non-linear motion of acceleration and deceleration, with irregular direction changes. Tacking-by-detection (TBD) with Kalman Filter motion prediction works well in pedestrian-dominant scenarios but falls short in complex situations when multiple objects perform non-linear and diverse motion simultaneously. To tackle the complex non-linear motion, we propose a real-time diffusion-based MOT approach named DiffMOT. Specifically, for the motion predictor component, we propose a novel Decoupled Diffusion-based Motion Predictor (D MP). It models the entire distribution of various motion presented by the data as a whole. It also predicts an individual object's motion conditioning on an individual's historical motion information. Furthermore, it optimizes the diffusion process with much less sampling steps. As a MOT tracker, the DiffMOT is real-time at 22.7FPS, and also outperforms the state-of-the-art on DanceTrack and SportsMOT datasets with 63.4 and 76.2 in HOTA metrics, respectively. To the best of our knowledge, DiffMOT is the first to introduce a diffusion probabilistic model into the MOT to tackle non-linear motion prediction.
DiffusionEdge: Diffusion Probabilistic Model for Crisp Edge Detection
Jan 09, 2024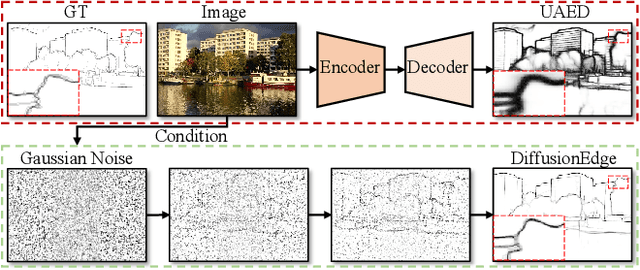

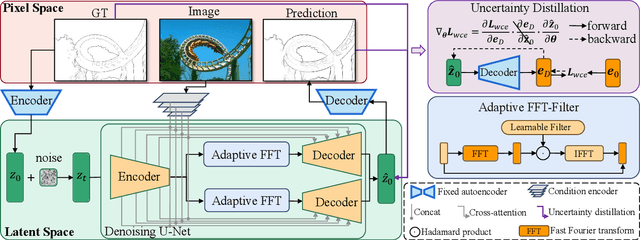
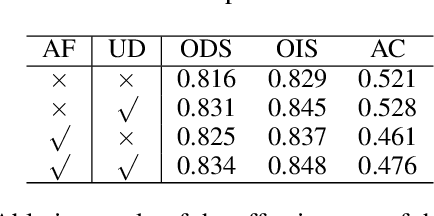
Limited by the encoder-decoder architecture, learning-based edge detectors usually have difficulty predicting edge maps that satisfy both correctness and crispness. With the recent success of the diffusion probabilistic model (DPM), we found it is especially suitable for accurate and crisp edge detection since the denoising process is directly applied to the original image size. Therefore, we propose the first diffusion model for the task of general edge detection, which we call DiffusionEdge. To avoid expensive computational resources while retaining the final performance, we apply DPM in the latent space and enable the classic cross-entropy loss which is uncertainty-aware in pixel level to directly optimize the parameters in latent space in a distillation manner. We also adopt a decoupled architecture to speed up the denoising process and propose a corresponding adaptive Fourier filter to adjust the latent features of specific frequencies. With all the technical designs, DiffusionEdge can be stably trained with limited resources, predicting crisp and accurate edge maps with much fewer augmentation strategies. Extensive experiments on four edge detection benchmarks demonstrate the superiority of DiffusionEdge both in correctness and crispness. On the NYUDv2 dataset, compared to the second best, we increase the ODS, OIS (without post-processing) and AC by 30.2%, 28.1% and 65.1%, respectively. Code: https://github.com/GuHuangAI/DiffusionEdge.
Manipulating the Label Space for In-Context Classification
Dec 06, 2023



After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
DeepFracture: A Generative Approach for Predicting Brittle Fractures
Oct 20, 2023In the realm of brittle fracture animation, generating realistic destruction animations with physics simulation techniques can be computationally expensive. Although methods using Voronoi diagrams or pre-fractured patterns work for real-time applications, they often lack realism in portraying brittle fractures. This paper introduces a novel learning-based approach for seamlessly merging realistic brittle fracture animations with rigid-body simulations. Our method utilizes BEM brittle fracture simulations to create fractured patterns and collision conditions for a given shape, which serve as training data for the learning process. To effectively integrate collision conditions and fractured shapes into a deep learning framework, we introduce the concept of latent impulse representation and geometrically-segmented signed distance function (GS-SDF). The latent impulse representation serves as input, capturing information about impact forces on the shape's surface. Simultaneously, a GS-SDF is used as the output representation of the fractured shape. To address the challenge of optimizing multiple fractured pattern targets with a single latent code, we propose an eight-dimensional latent space based on a normal distribution code within our latent impulse representation design. This adaptation effectively transforms our neural network into a generative one. Our experimental results demonstrate that our approach can generate significantly more detailed brittle fractures compared to existing techniques, all while maintaining commendable computational efficiency during run-time.
Decoupled Diffusion Models with Explicit Transition Probability
Jun 23, 2023



Recent diffusion probabilistic models (DPMs) have shown remarkable abilities of generated content, however, they often suffer from complex forward processes, resulting in inefficient solutions for the reversed process and prolonged sampling times. In this paper, we aim to address the aforementioned challenges by focusing on the diffusion process itself that we propose to decouple the intricate diffusion process into two comparatively simpler process to improve the generative efficacy and speed. In particular, we present a novel diffusion paradigm named DDM (\textbf{D}ecoupled \textbf{D}iffusion \textbf{M}odels) based on the It\^{o} diffusion process, in which the image distribution is approximated by an explicit transition probability while the noise path is controlled by the standard Wiener process. We find that decoupling the diffusion process reduces the learning difficulty and the explicit transition probability improves the generative speed significantly. We prove a new training objective for DPM, which enables the model to learn to predict the noise and image components separately. Moreover, given the novel forward diffusion equation, we derive the reverse denoising formula of DDM that naturally supports fewer steps of generation without ordinary differential equation (ODE) based accelerators. Our experiments demonstrate that DDM outperforms previous DPMs by a large margin in fewer function evaluations setting and gets comparable performances in long function evaluations setting. We also show that our framework can be applied to image-conditioned generation and high-resolution image synthesis, and that it can generate high-quality images with only 10 function evaluations.