 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayMVSNet++: Learning Ray-based 1D Implicit Fields for Accurate Multi-View Stereo
Paper and Code
Jul 16, 2023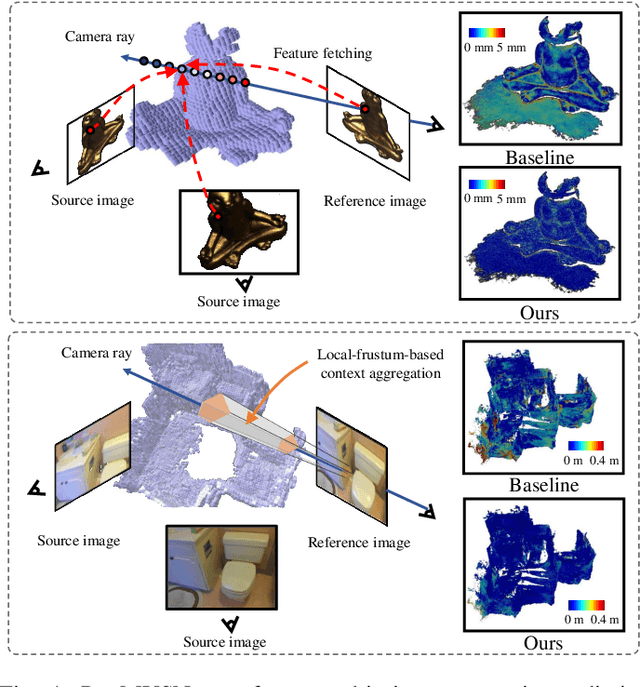
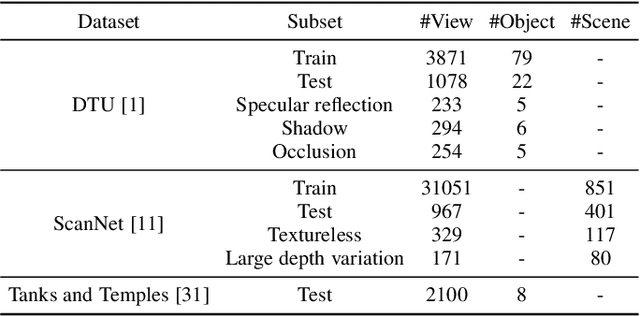
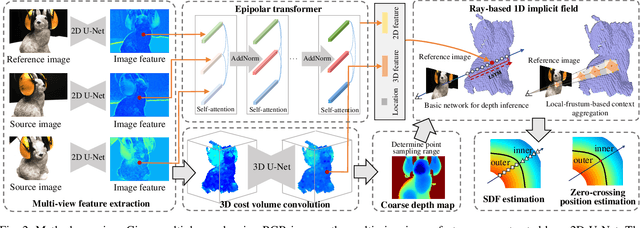
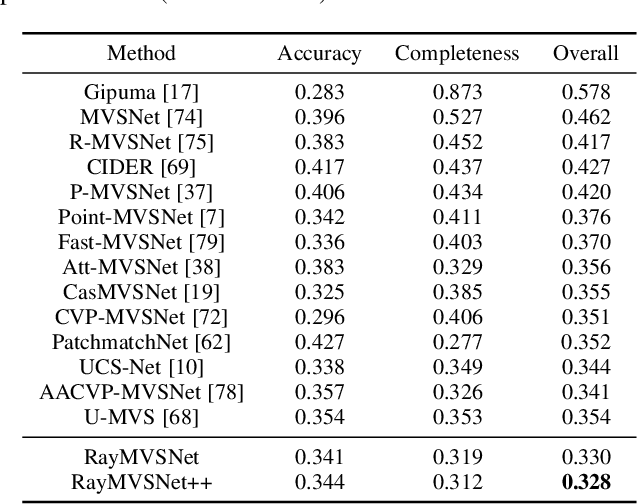
Learning-based multi-view stereo (MVS) has by far centered around 3D convolution on cost volumes. Due to the high computation and memory consumption of 3D CNN, the resolution of output depth is often considerably limited. Different from most existing works dedicated to adaptive refinement of cost volumes, we opt to directly optimize the depth value along each camera ray, mimicking the range finding of a laser scanner. This reduces the MVS problem to ray-based depth optimization which is much more light-weight than full cost volume optimization. In particular, we propose RayMVSNet which learns sequential prediction of a 1D implicit field along each camera ray with the zero-crossing point indicating scene depth. This sequential modeling, conducted based on transformer features, essentially learns the epipolar line search in traditional multi-view stereo. We devise a multi-task learning for better optimization convergence and depth accuracy. We found the monotonicity property of the SDFs along each ray greatly benefits the depth estimation. Our method ranks top on both the DTU and the Tanks & Temples datasets over all previous learning-based methods, achieving an overall reconstruction score of 0.33mm on DTU and an F-score of 59.48% on Tanks & Temples. It is able to produce high-quality depth estimation and point cloud reconstruction in challenging scenarios such as objects/scenes with non-textured surface, severe occlusion, and highly varying depth range. Further, we propose RayMVSNet++ to enhance contextual feature aggregation for each ray through designing an attentional gating unit to select semantically relevant neighboring rays within the local frustum around that ray. RayMVSNet++ achieves state-of-the-art performance on the ScanNet dataset. In particular, it attains an AbsRel of 0.058m and produces accurate results on the two subsets of textureless regions and large depth variation.