 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynFER: Towards Boosting Facial Expression Recognition with Synthetic Data
Paper and Code
Oct 13, 2024


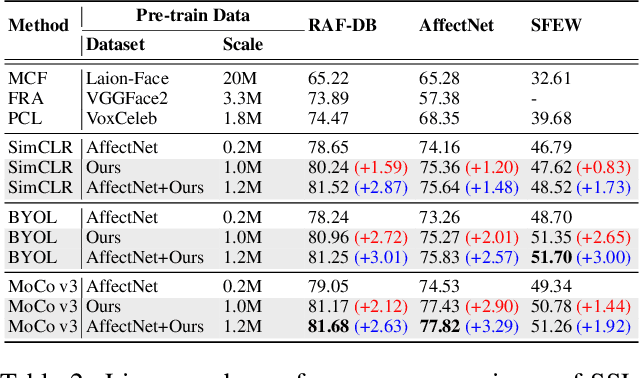
Facial expression datasets remain limited in scale due to privacy concerns, the subjectivity of annotations, and the labor-intensive nature of data collection. This limitation poses a significant challenge for developing modern deep learning-based facial expression analysis models, particularly foundation models, that rely on large-scale data for optimal performance. To tackle the overarching and complex challenge, we introduce SynFER (Synthesis of Facial Expressions with Refined Control), a novel framework for synthesizing facial expression image data based on high-level textual descriptions as well as more fine-grained and precise control through facial action units. To ensure the quality and reliability of the synthetic data, we propose a semantic guidance technique to steer the generation process and a pseudo-label generator to help rectify the facial expression labels for the synthetic images. To demonstrate the generation fidelity and the effectiveness of the synthetic data from SynFER, we conduct extensive experiments on representation learning using both synthetic data and real-world data. Experiment results validate the efficacy of the proposed approach and the synthetic data. Notably, our approach achieves a 67.23% classification accuracy on AffectNet when training solely with synthetic data equivalent to the AffectNet training set size, which increases to 69.84% when scaling up to five times the original size. Our code will be made publicly available.