 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Combating Frequency Simplicity-biased Learning for Domain Generalization
Oct 21, 2024Domain generalization methods aim to learn transferable knowledge from source domains that can generalize well to unseen target domains. Recent studies show that neural networks frequently suffer from a simplicity-biased learning behavior which leads to over-reliance on specific frequency sets, namely as frequency shortcuts, instead of semantic information, resulting in poor generalization performance. Despite previous data augmentation techniques successfully enhancing generalization performances, they intend to apply more frequency shortcuts, thereby causing hallucinations of generalization improvement. In this paper, we aim to prevent such learning behavior of applying frequency shortcuts from a data-driven perspective. Given the theoretical justification of models' biased learning behavior on different spatial frequency components, which is based on the dataset frequency properties, we argue that the learning behavior on various frequency components could be manipulated by changing the dataset statistical structure in the Fourier domain. Intuitively, as frequency shortcuts are hidden in the dominant and highly dependent frequencies of dataset structure, dynamically perturbating the over-reliance frequency components could prevent the application of frequency shortcuts. To this end, we propose two effective data augmentation modules designed to collaboratively and adaptively adjust the frequency characteristic of the dataset, aiming to dynamically influence the learning behavior of the model and ultimately serving as a strategy to mitigate shortcut learning. Code is available at AdvFrequency (https://github.com/C0notSilly/AdvFrequency).
Realistic and Efficient Face Swapping: A Unified Approach with Diffusion Models
Sep 11, 2024Despite promising progress in face swapping task, realistic swapped images remain elusive, often marred by artifacts, particularly in scenarios involving high pose variation, color differences, and occlusion. To address these issues, we propose a novel approach that better harnesses diffusion models for face-swapping by making following core contributions. (a) We propose to re-frame the face-swapping task as a self-supervised, train-time inpainting problem, enhancing the identity transfer while blending with the target image. (b) We introduce a multi-step Denoising Diffusion Implicit Model (DDIM) sampling during training, reinforcing identity and perceptual similarities. (c) Third, we introduce CLIP feature disentanglement to extract pose, expression, and lighting information from the target image, improving fidelity. (d) Further, we introduce a mask shuffling technique during inpainting training, which allows us to create a so-called universal model for swapping, with an additional feature of head swapping. Ours can swap hair and even accessories, beyond traditional face swapping. Unlike prior works reliant on multiple off-the-shelf models, ours is a relatively unified approach and so it is resilient to errors in other off-the-shelf models. Extensive experiments on FFHQ and CelebA datasets validate the efficacy and robustness of our approach, showcasing high-fidelity, realistic face-swapping with minimal inference time. Our code is available at https://github.com/Sanoojan/REFace.
Boosting Adversarial Transferability across Model Genus by Deformation-Constrained Warping
Feb 06, 2024Adversarial examples generated by a surrogate model typically exhibit limited transferability to unknown target systems. To address this problem, many transferability enhancement approaches (e.g., input transformation and model augmentation) have been proposed. However, they show poor performances in attacking systems having different model genera from the surrogate model. In this paper, we propose a novel and generic attacking strategy, called Deformation-Constrained Warping Attack (DeCoWA), that can be effectively applied to cross model genus attack. Specifically, DeCoWA firstly augments input examples via an elastic deformation, namely Deformation-Constrained Warping (DeCoW), to obtain rich local details of the augmented input. To avoid severe distortion of global semantics led by random deformation, DeCoW further constrains the strength and direction of the warping transformation by a novel adaptive control strategy. Extensive experiments demonstrate that the transferable examples crafted by our DeCoWA on CNN surrogates can significantly hinder the performance of Transformers (and vice versa) on various tasks, including image classification, video action recognition, and audio recognition. Code is made available at https://github.com/LinQinLiang/DeCoWA.
Scale-free Photo-realistic Adversarial Pattern Attack
Aug 12, 2022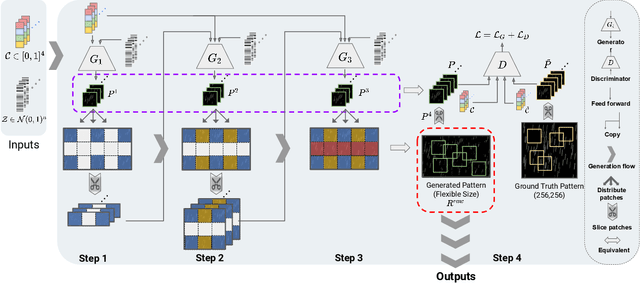
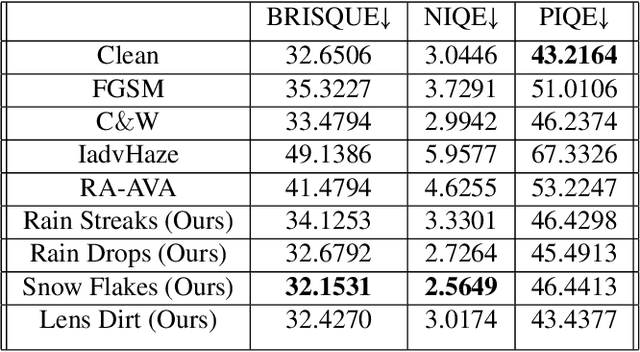
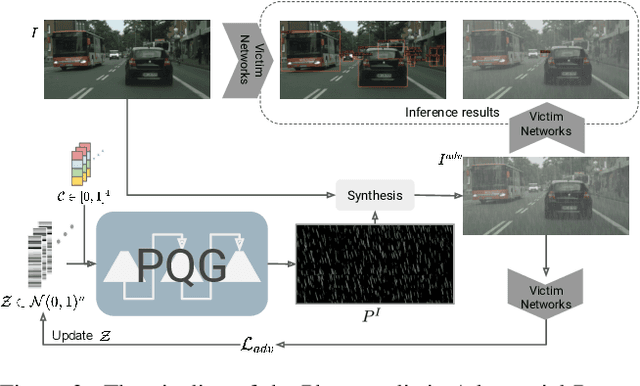
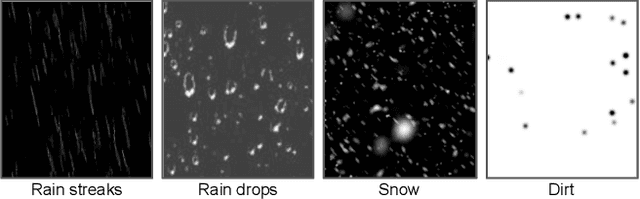
Traditional pixel-wise image attack algorithms suffer from poor robustness to defense algorithms, i.e., the attack strength degrades dramatically when defense algorithms are applied. Although Generative Adversarial Networks (GAN) can partially address this problem by synthesizing a more semantically meaningful texture pattern, the main limitation is that existing generators can only generate images of a specific scale. In this paper, we propose a scale-free generation-based attack algorithm that synthesizes semantically meaningful adversarial patterns globally to images with arbitrary scales. Our generative attack approach consistently outperforms the state-of-the-art methods on a wide range of attack settings, i.e. the proposed approach largely degraded the performance of various image classification, object detection, and instance segmentation algorithms under different advanced defense methods.
Frequency-driven Imperceptible Adversarial Attack on Semantic Similarity
Mar 24, 2022
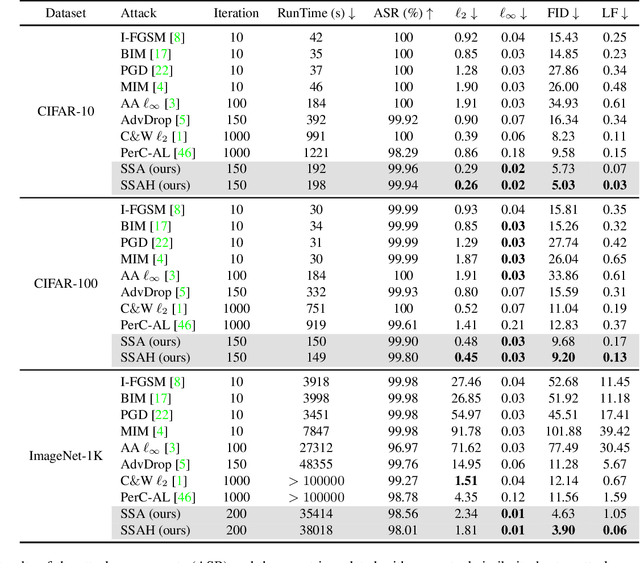
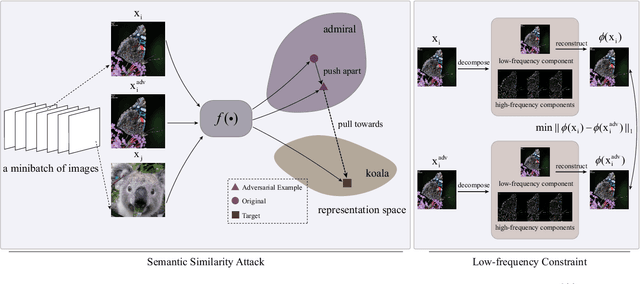

Current adversarial attack research reveals the vulnerability of learning-based classifiers against carefully crafted perturbations. However, most existing attack methods have inherent limitations in cross-dataset generalization as they rely on a classification layer with a closed set of categories. Furthermore, the perturbations generated by these methods may appear in regions easily perceptible to the human visual system (HVS). To circumvent the former problem, we propose a novel algorithm that attacks semantic similarity on feature representations. In this way, we are able to fool classifiers without limiting attacks to a specific dataset. For imperceptibility, we introduce the low-frequency constraint to limit perturbations within high-frequency components, ensuring perceptual similarity between adversarial examples and originals. Extensive experiments on three datasets (CIFAR-10, CIFAR-100, and ImageNet-1K) and three public online platforms indicate that our attack can yield misleading and transferable adversarial examples across architectures and datasets. Additionally, visualization results and quantitative performance (in terms of four different metrics) show that the proposed algorithm generates more imperceptible perturbations than the state-of-the-art methods. Code is made available at.