 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactMotion: Generating Reactive Listener Motions from Speaker Utterance
Mar 16, 2026In this paper, we introduce a new task, Reactive Listener Motion Generation from Speaker Utterance, which aims to generate naturalistic listener body motions that appropriately respond to a speaker's utterance. However, modeling such nonverbal listener behaviors remains underexplored and challenging due to the inherently non-deterministic nature of human reactions. To facilitate this task, we present ReactMotionNet, a large-scale dataset that pairs speaker utterances with multiple candidate listener motions annotated with varying degrees of appropriateness. This dataset design explicitly captures the one-to-many nature of listener behavior and provides supervision beyond a single ground-truth motion. Building on this dataset design, we develop preference-oriented evaluation protocols tailored to evaluate reactive appropriateness, where conventional motion metrics focusing on input-motion alignment ignore. We further propose ReactMotion, a unified generative framework that jointly models text, audio, emotion, and motion, and is trained with preference-based objectives to encourage both appropriate and diverse listener responses. Extensive experiments show that ReactMotion outperforms retrieval baselines and cascaded LLM-based pipelines, generating more natural, diverse, and appropriate listener motions.
MG-MotionLLM: A Unified Framework for Motion Comprehension and Generation across Multiple Granularities
Apr 03, 2025Recent motion-aware large language models have demonstrated promising potential in unifying motion comprehension and generation. However, existing approaches primarily focus on coarse-grained motion-text modeling, where text describes the overall semantics of an entire motion sequence in just a few words. This limits their ability to handle fine-grained motion-relevant tasks, such as understanding and controlling the movements of specific body parts. To overcome this limitation, we pioneer MG-MotionLLM, a unified motion-language model for multi-granular motion comprehension and generation. We further introduce a comprehensive multi-granularity training scheme by incorporating a set of novel auxiliary tasks, such as localizing temporal boundaries of motion segments via detailed text as well as motion detailed captioning, to facilitate mutual reinforcement for motion-text modeling across various levels of granularity. Extensive experiments show that our MG-MotionLLM achieves superior performance on classical text-to-motion and motion-to-text tasks, and exhibits potential in novel fine-grained motion comprehension and editing tasks. Project page: CVI-SZU/MG-MotionLLM
OMG: Occlusion-friendly Personalized Multi-concept Generation in Diffusion Models
Mar 16, 2024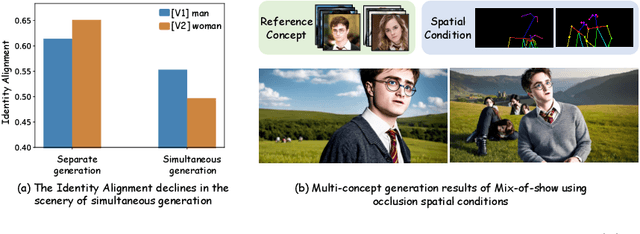
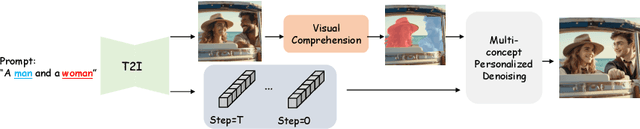
Personalization is an important topic in text-to-image generation, especially the challenging multi-concept personalization. Current multi-concept methods are struggling with identity preservation, occlusion, and the harmony between foreground and background. In this work, we propose OMG, an occlusion-friendly personalized generation framework designed to seamlessly integrate multiple concepts within a single image. We propose a novel two-stage sampling solution. The first stage takes charge of layout generation and visual comprehension information collection for handling occlusions. The second one utilizes the acquired visual comprehension information and the designed noise blending to integrate multiple concepts while considering occlusions. We also observe that the initiation denoising timestep for noise blending is the key to identity preservation and layout. Moreover, our method can be combined with various single-concept models, such as LoRA and InstantID without additional tuning. Especially, LoRA models on civitai.com can be exploited directly. Extensive experiments demonstrate that OMG exhibits superior performance in multi-concept personalization.
Frequency-driven Imperceptible Adversarial Attack on Semantic Similarity
Mar 24, 2022
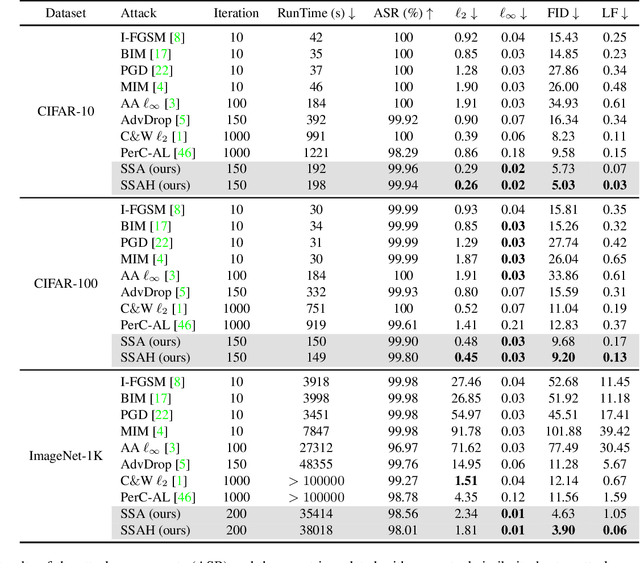
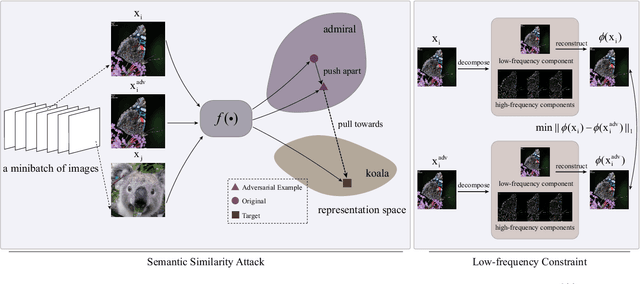

Current adversarial attack research reveals the vulnerability of learning-based classifiers against carefully crafted perturbations. However, most existing attack methods have inherent limitations in cross-dataset generalization as they rely on a classification layer with a closed set of categories. Furthermore, the perturbations generated by these methods may appear in regions easily perceptible to the human visual system (HVS). To circumvent the former problem, we propose a novel algorithm that attacks semantic similarity on feature representations. In this way, we are able to fool classifiers without limiting attacks to a specific dataset. For imperceptibility, we introduce the low-frequency constraint to limit perturbations within high-frequency components, ensuring perceptual similarity between adversarial examples and originals. Extensive experiments on three datasets (CIFAR-10, CIFAR-100, and ImageNet-1K) and three public online platforms indicate that our attack can yield misleading and transferable adversarial examples across architectures and datasets. Additionally, visualization results and quantitative performance (in terms of four different metrics) show that the proposed algorithm generates more imperceptible perturbations than the state-of-the-art methods. Code is made available at.