 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Video Restoration and Enhancement Using Pre-Trained Image Diffusion Model
Paper and Code
Jul 02, 2024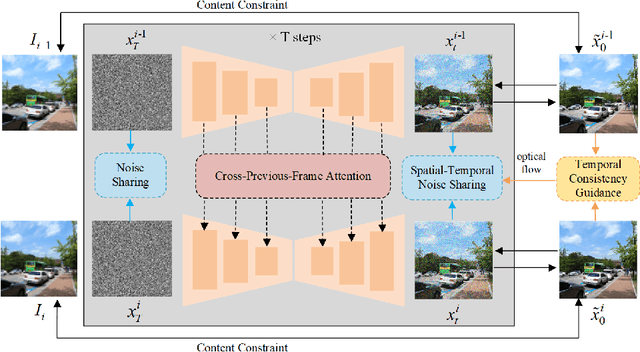
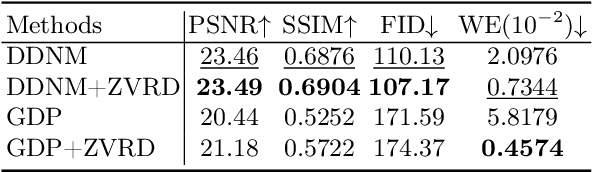
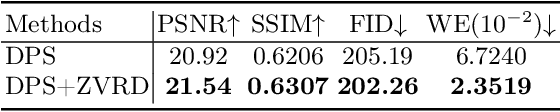

Diffusion-based zero-shot image restoration and enhancement models have achieved great success in various image restoration and enhancement tasks without training. However, directly applying them to video restoration and enhancement results in severe temporal flickering artifacts. In this paper, we propose the first framework for zero-shot video restoration and enhancement based on a pre-trained image diffusion model. By replacing the self-attention layer with the proposed cross-previous-frame attention layer, the pre-trained image diffusion model can take advantage of the temporal correlation between neighboring frames. We further propose temporal consistency guidance, spatial-temporal noise sharing, and an early stopping sampling strategy for better temporally consistent sampling. Our method is a plug-and-play module that can be inserted into any diffusion-based zero-shot image restoration or enhancement methods to further improve their performance. Experimental results demonstrate the superiority of our proposed method in producing temporally consistent videos with better fidelity.