 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling
Paper and Code
Aug 16, 2024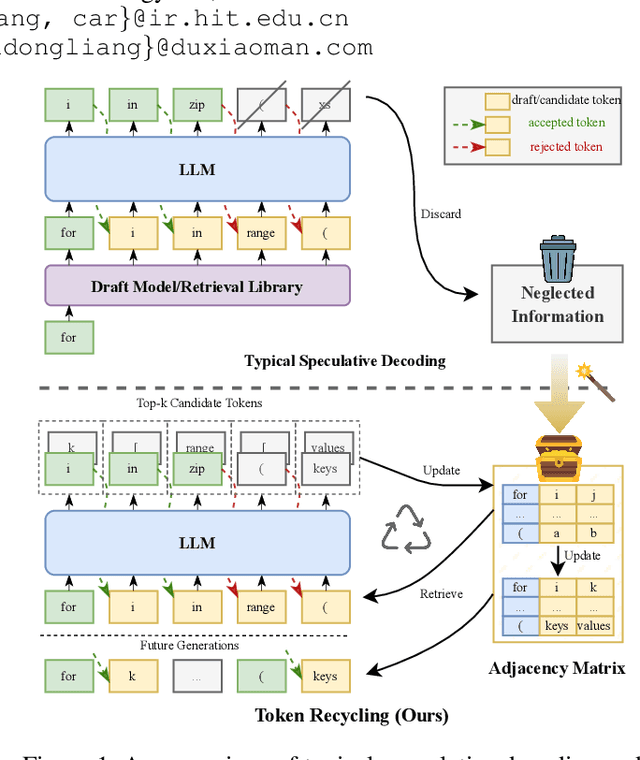

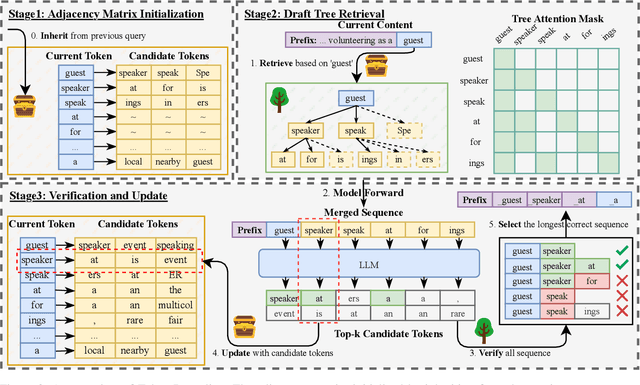
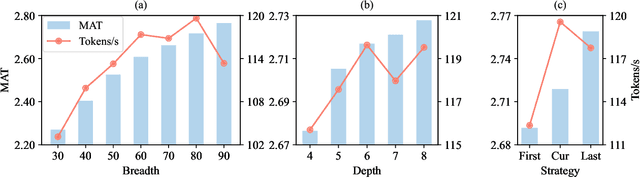
The rapid growth in the parameters of large language models (LLMs) has made inference latency a fundamental bottleneck, limiting broader application of LLMs. Speculative decoding represents a lossless approach to accelerate inference through a guess-and-verify paradigm, leveraging the parallel capabilities of modern hardware. Some speculative decoding methods rely on additional structures to guess draft tokens, such as small models or parameter-efficient architectures, which need extra training before use. Alternatively, retrieval-based train-free techniques build libraries from pre-existing corpora or by n-gram generation. However, they face challenges like large storage requirements, time-consuming retrieval, and limited adaptability. Observing that candidate tokens generated during the decoding process are likely to reoccur in future sequences, we propose Token Recycling. This approach stores candidate tokens in an adjacency matrix and employs a breadth-first search (BFS)-like algorithm on the matrix to construct a draft tree. The tree is then validated through tree attention. New candidate tokens from the decoding process are then used to update the matrix. Token Recycling requires \textless2MB of additional storage and achieves approximately 2x speedup across all sizes of LLMs. It significantly outperforms existing train-free methods by 30\% and even a training method by 25\%. It can be directly applied to any existing LLMs and tasks without the need for adaptation.