 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraEP: Unleash MoE Training and Inference on Rack-Scale Nodes with Near-Optimal Load Balancing
Jun 02, 2026Large-scale expert parallelism (EP) is becoming pivotal for training and serving frontier MoE models, but it also amplifies device-level expert load imbalance into compute stragglers, token all-to-all bottlenecks, and activation-memory spikes. Existing balancers redistribute experts periodically based on historical load, which becomes unreliable for production deployments with non-stationary load patterns. We present UltraEP, the first exact-load, real-time balancer for large-EP MoE training and serving prefill on rack-scale nodes (RSNs). Built upon the extended scale-up connectivity of RSNs, UltraEP rebalances every microbatch and layer on critical paths, which requires nontrivial co-design of plan solving and expert replication communication to minimize exposed overhead. To this end, UltraEP eagerly reacts to post-gating load with efficient quota-driven planning, and executes the resulting irregular expert-state transfers with RSN-native persistent tile streaming and relay-based fan-out mitigation. Averaged across MoE models from 106B to 671B parameters in training and prefill, UltraEP achieves 94.3% of the force-balanced ideal throughput, delivering 1.49$\times$ improvement over non-balancing, while reducing the final inter-rank imbalance from 1.30$-$4.01 to 1.01$-$1.04. Additionally, we validate UltraEP's scalability and robustness in production MoE training with 2560 GPUs.
BigMac: Breaking the Pareto Frontier of Compute and Memory in Multimodal LLM Training
May 25, 2026Training multimodal large language models (MLLMs) is challenged by both model and data heterogeneity. Existing systems redesign the training pipeline to address these challenges, but remain bound by a Pareto frontier between compute and memory efficiency, improving one only at the expense of the other. We present BigMac, a new training pipeline for multimodal LLMs. The core idea of BigMac is to elegantly nest the encoder and generator computation into the original LLM pipeline, forming a dependency-safe nested pipeline structure. With this design, BigMac reduces the activation memory complexity of the encoder and generator to O(1) while keeping the activation memory complexity of the LLM unchanged. At the same time, it achieves the same computational efficiency as the idealized setting with unlimited memory. As a result, BigMac breaks the Pareto frontier between computational efficiency and memory usage, enabling simultaneous optimization of both computation and memory in MLLM training. We evaluate BigMac on multiple MLLMs and training workloads. Experimental results show that BigMac achieves a 1.08$\times$-1.9$\times$ training speedup over baseline systems while maintaining stable memory usage as batch size increases.
SlimPipe: Memory-Thrifty and Efficient Pipeline Parallelism for Long-Context LLM Training
Apr 20, 2025Pipeline Parallelism (PP) serves as a crucial technique for training Large Language Models (LLMs), owing to its capability to alleviate memory pressure from model states with relatively low communication overhead. However, in long-context scenarios, existing pipeline parallelism methods fail to address the substantial activation memory pressure, primarily due to the peak memory consumption resulting from the accumulation of activations across multiple microbatches. Moreover, these approaches inevitably introduce considerable pipeline bubbles, further hindering efficiency. To tackle these challenges, we propose SlimPipe, a novel approach to fine-grained pipeline parallelism that employs uniform sequence slicing coupled with one-forward-one-backward (1F1B) schedule. It reduces the accumulated activations from several microbatches to just one, which is split into several slices. Although the slices are evenly partitioned, the computation cost is not equal across slices due to causal attention. We develop a sophisticated workload redistribution technique to address this load imbalance. SlimPipe achieves (1) near-zero memory overhead and (2) minimal pipeline bubbles simultaneously. The effectiveness of SlimPipe has been proven by thorough testing with diverse model architectures, context window sizes, and SlimPipe-specific configurations. For example, on the Llama 70B model, compared to state-of-the-art methods, SlimPipe significantly boosts the Model FLOPs Utilization (MFU) to up to $1.57\times$ for a context length of 512K. More notably, for a context length of 2048K, it maintains over 45% utilization on 256 NVIDIA Hopper 80GB GPUs, while other approaches either suffer significant performance drops or fail entirely due to memory constraints.
HIT-SCIR at MMNLU-22: Consistency Regularization for Multilingual Spoken Language Understanding
Jan 05, 2023Multilingual spoken language understanding (SLU) consists of two sub-tasks, namely intent detection and slot filling. To improve the performance of these two sub-tasks, we propose to use consistency regularization based on a hybrid data augmentation strategy. The consistency regularization enforces the predicted distributions for an example and its semantically equivalent augmentation to be consistent. We conduct experiments on the MASSIVE dataset under both full-dataset and zero-shot settings. Experimental results demonstrate that our proposed method improves the performance on both intent detection and slot filling tasks. Our system\footnote{The code will be available at \url{https://github.com/bozheng-hit/MMNLU-22-HIT-SCIR}.} ranked 1st in the MMNLU-22 competition under the full-dataset setting.
Co-GAT: A Co-Interactive Graph Attention Network for Joint Dialog Act Recognition and Sentiment Classification
Dec 24, 2020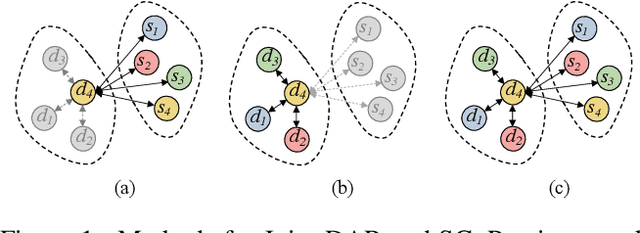
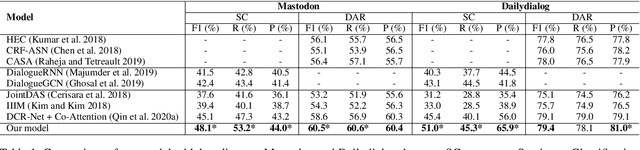

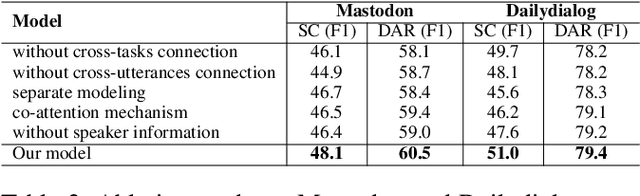
In a dialog system, dialog act recognition and sentiment classification are two correlative tasks to capture speakers intentions, where dialog act and sentiment can indicate the explicit and the implicit intentions separately. The dialog context information (contextual information) and the mutual interaction information are two key factors that contribute to the two related tasks. Unfortunately, none of the existing approaches consider the two important sources of information simultaneously. In this paper, we propose a Co-Interactive Graph Attention Network (Co-GAT) to jointly perform the two tasks. The core module is a proposed co-interactive graph interaction layer where a cross-utterances connection and a cross-tasks connection are constructed and iteratively updated with each other, achieving to consider the two types of information simultaneously. Experimental results on two public datasets show that our model successfully captures the two sources of information and achieve the state-of-the-art performance. In addition, we find that the contributions from the contextual and mutual interaction information do not fully overlap with contextualized word representations (BERT, Roberta, XLNet).