 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Model-Agnostic Data Subsampling for Recommendation Systems
May 25, 2023Data subsampling is widely used to speed up the training of large-scale recommendation systems. Most subsampling methods are model-based and often require a pre-trained pilot model to measure data importance via e.g. sample hardness. However, when the pilot model is misspecified, model-based subsampling methods deteriorate. Since model misspecification is persistent in real recommendation systems, we instead propose model-agnostic data subsampling methods by only exploring input data structure represented by graphs. Specifically, we study the topology of the user-item graph to estimate the importance of each user-item interaction (an edge in the user-item graph) via graph conductance, followed by a propagation step on the network to smooth out the estimated importance value. Since our proposed method is model-agnostic, we can marry the merits of both model-agnostic and model-based subsampling methods. Empirically, we show that combing the two consistently improves over any single method on the used datasets. Experimental results on KuaiRec and MIND datasets demonstrate that our proposed methods achieve superior results compared to baseline approaches.
Label Inference Attack against Split Learning under Regression Setting
Jan 18, 2023



As a crucial building block in vertical Federated Learning (vFL), Split Learning (SL) has demonstrated its practice in the two-party model training collaboration, where one party holds the features of data samples and another party holds the corresponding labels. Such method is claimed to be private considering the shared information is only the embedding vectors and gradients instead of private raw data and labels. However, some recent works have shown that the private labels could be leaked by the gradients. These existing attack only works under the classification setting where the private labels are discrete. In this work, we step further to study the leakage in the scenario of the regression model, where the private labels are continuous numbers (instead of discrete labels in classification). This makes previous attacks harder to infer the continuous labels due to the unbounded output range. To address the limitation, we propose a novel learning-based attack that integrates gradient information and extra learning regularization objectives in aspects of model training properties, which can infer the labels under regression settings effectively. The comprehensive experiments on various datasets and models have demonstrated the effectiveness of our proposed attack. We hope our work can pave the way for future analyses that make the vFL framework more secure.
DGRec: Graph Neural Network for Recommendation with Diversified Embedding Generation
Nov 27, 2022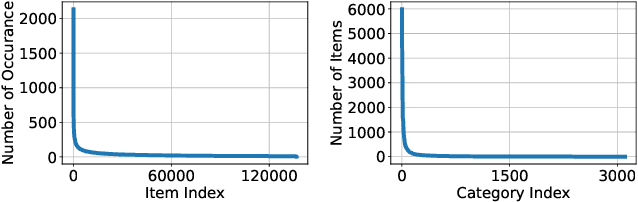


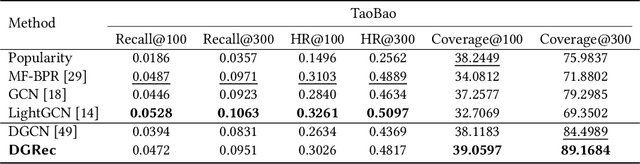
Graph Neural Network (GNN) based recommender systems have been attracting more and more attention in recent years due to their excellent performance in accuracy. Representing user-item interactions as a bipartite graph, a GNN model generates user and item representations by aggregating embeddings of their neighbors. However, such an aggregation procedure often accumulates information purely based on the graph structure, overlooking the redundancy of the aggregated neighbors and resulting in poor diversity of the recommended list. In this paper, we propose diversifying GNN-based recommender systems by directly improving the embedding generation procedure. Particularly, we utilize the following three modules: submodular neighbor selection to find a subset of diverse neighbors to aggregate for each GNN node, layer attention to assign attention weights for each layer, and loss reweighting to focus on the learning of items belonging to long-tail categories. Blending the three modules into GNN, we present DGRec(Diversified GNN-based Recommender System) for diversified recommendation. Experiments on real-world datasets demonstrate that the proposed method can achieve the best diversity while keeping the accuracy comparable to state-of-the-art GNN-based recommender systems.
Person Re-Identification by Discriminative Selection in Video Ranking
Jan 23, 2016



Current person re-identification (ReID) methods typically rely on single-frame imagery features, whilst ignoring space-time information from image sequences often available in the practical surveillance scenarios. Single-frame (single-shot) based visual appearance matching is inherently limited for person ReID in public spaces due to the challenging visual ambiguity and uncertainty arising from non-overlapping camera views where viewing condition changes can cause significant people appearance variations. In this work, we present a novel model to automatically select the most discriminative video fragments from noisy/incomplete image sequences of people from which reliable space-time and appearance features can be computed, whilst simultaneously learning a video ranking function for person ReID. Using the PRID$2011$, iLIDS-VID, and HDA+ image sequence datasets, we extensively conducted comparative evaluations to demonstrate the advantages of the proposed model over contemporary gait recognition, holistic image sequence matching and state-of-the-art single-/multi-shot ReID methods.