 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Long-Term Dependencies for Generating Dynamic Scene Graphs
Paper and Code
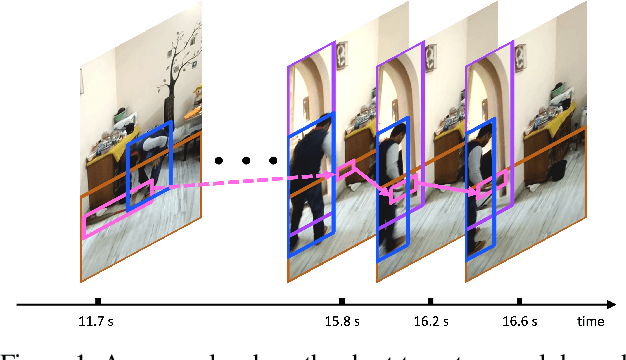
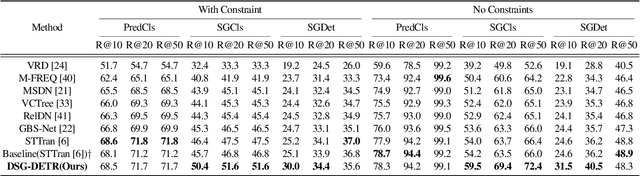
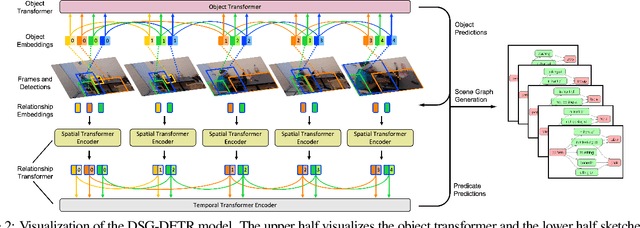
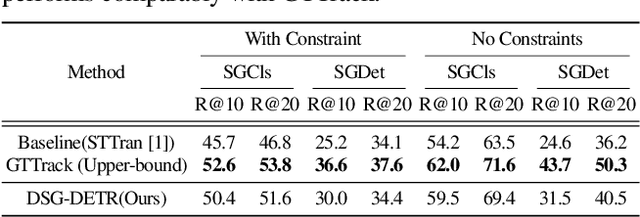
Structured video representation in the form of dynamic scene graphs is an effective tool for several video understanding tasks. Compared to the task of scene graph generation from images, dynamic scene graph generation is more challenging due to the temporal dynamics of the scene and the inherent temporal fluctuations of predictions. We show that capturing long-term dependencies is the key to effective generation of dynamic scene graphs. We present the detect-track-recognize paradigm by constructing consistent long-term object tracklets from a video, followed by transformers to capture the dynamics of objects and visual relations. Experimental results demonstrate that our Dynamic Scene Graph Detection Transformer (DSG-DETR) outperforms state-of-the-art methods by a significant margin on the benchmark dataset Action Genome. We also perform ablation studies and validate the effectiveness of each component of the proposed approach.