 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Pretraining of Medical Time Series and Notes
Paper and Code
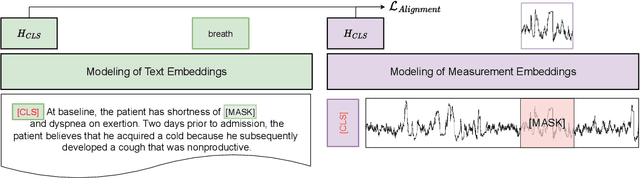



Within the intensive care unit (ICU), a wealth of patient data, including clinical measurements and clinical notes, is readily available. This data is a valuable resource for comprehending patient health and informing medical decisions, but it also contains many challenges in analysis. Deep learning models show promise in extracting meaningful patterns, but they require extensive labeled data, a challenge in critical care. To address this, we propose a novel approach employing self-supervised pretraining, focusing on the alignment of clinical measurements and notes. Our approach combines contrastive and masked token prediction tasks during pretraining. Semi-supervised experiments on the MIMIC-III dataset demonstrate the effectiveness of our self-supervised pretraining. In downstream tasks, including in-hospital mortality prediction and phenotyping, our pretrained model outperforms baselines in settings where only a fraction of the data is labeled, emphasizing its ability to enhance ICU data analysis. Notably, our method excels in situations where very few labels are available, as evidenced by an increase in the AUC-ROC for in-hospital mortality by 0.17 and in AUC-PR for phenotyping by 0.1 when only 1% of labels are accessible. This work advances self-supervised learning in the healthcare domain, optimizing clinical insights from abundant yet challenging ICU data.