 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Cooperation Knowledge Distillation for Novel Class Discovery
Jul 02, 2024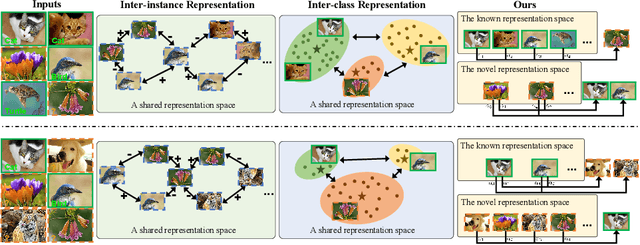

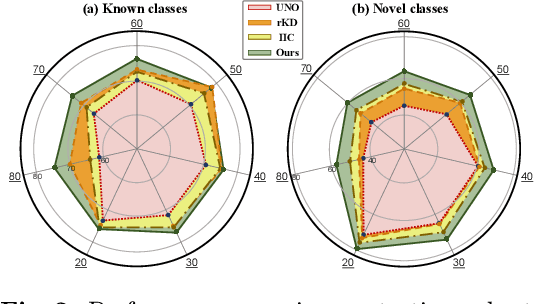
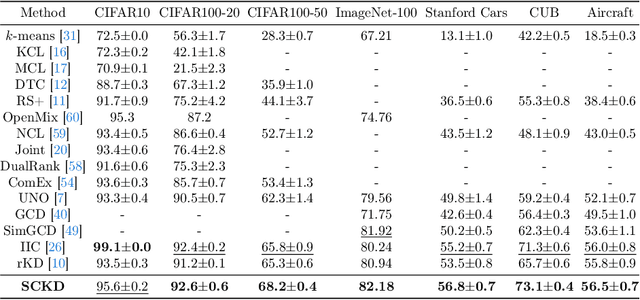
Novel Class Discovery (NCD) aims to discover unknown and novel classes in an unlabeled set by leveraging knowledge already learned about known classes. Existing works focus on instance-level or class-level knowledge representation and build a shared representation space to achieve performance improvements. However, a long-neglected issue is the potential imbalanced number of samples from known and novel classes, pushing the model towards dominant classes. Therefore, these methods suffer from a challenging trade-off between reviewing known classes and discovering novel classes. Based on this observation, we propose a Self-Cooperation Knowledge Distillation (SCKD) method to utilize each training sample (whether known or novel, labeled or unlabeled) for both review and discovery. Specifically, the model's feature representations of known and novel classes are used to construct two disjoint representation spaces. Through spatial mutual information, we design a self-cooperation learning to encourage model learning from the two feature representation spaces from itself. Extensive experiments on six datasets demonstrate that our method can achieve significant performance improvements, achieving state-of-the-art performance.
Hierarchical Visual Policy Learning for Long-Horizon Robot Manipulation in Densely Cluttered Scenes
Dec 05, 2023In this work, we focus on addressing the long-horizon manipulation tasks in densely cluttered scenes. Such tasks require policies to effectively manage severe occlusions among objects and continually produce actions based on visual observations. We propose a vision-based Hierarchical policy for Cluttered-scene Long-horizon Manipulation (HCLM). It employs a high-level policy and three options to select and instantiate three parameterized action primitives: push, pick, and place. We first train the pick and place options by behavior cloning (BC). Subsequently, we use hierarchical reinforcement learning (HRL) to train the high-level policy and push option. During HRL, we propose a Spatially Extended Q-update (SEQ) to augment the updates for the push option and a Two-Stage Update Scheme (TSUS) to alleviate the non-stationary transition problem in updating the high-level policy. We demonstrate that HCLM significantly outperforms baseline methods in terms of success rate and efficiency in diverse tasks. We also highlight our method's ability to generalize to more cluttered environments with more additional blocks.
Sampling to Distill: Knowledge Transfer from Open-World Data
Jul 31, 2023Data-Free Knowledge Distillation (DFKD) is a novel task that aims to train high-performance student models using only the teacher network without original training data. Despite encouraging results, existing DFKD methods rely heavily on generation modules with high computational costs. Meanwhile, they ignore the fact that the generated and original data exist domain shifts due to the lack of supervision information. Moreover, knowledge is transferred through each example, ignoring the implicit relationship among multiple examples. To this end, we propose a novel Open-world Data Sampling Distillation (ODSD) method without a redundant generation process. First, we try to sample open-world data close to the original data's distribution by an adaptive sampling module. Then, we introduce a low-noise representation to alleviate the domain shifts and build a structured relationship of multiple data examples to exploit data knowledge. Extensive experiments on CIFAR-10, CIFAR-100, NYUv2, and ImageNet show that our ODSD method achieves state-of-the-art performance. Especially, we improve 1.50\%-9.59\% accuracy on the ImageNet dataset compared with the existing results.
Explicit and Implicit Knowledge Distillation via Unlabeled Data
Feb 23, 2023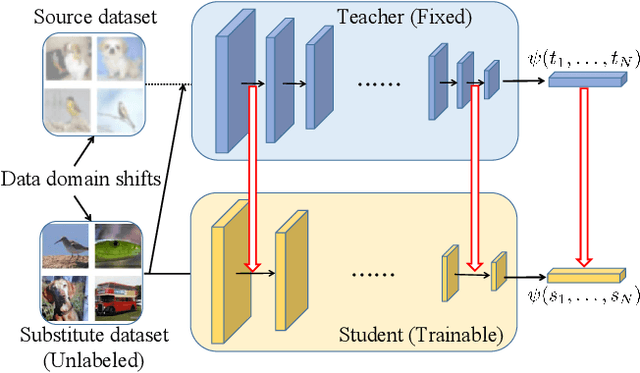
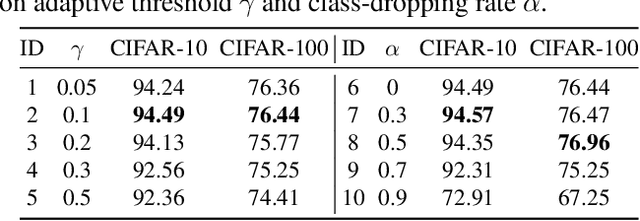
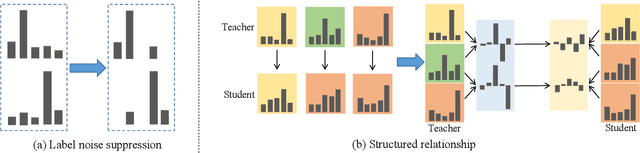
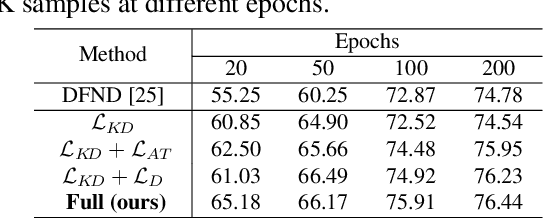
Data-free knowledge distillation is a challenging model lightweight task for scenarios in which the original dataset is not available. Previous methods require a lot of extra computational costs to update one or more generators and their naive imitate-learning lead to lower distillation efficiency. Based on these observations, we first propose an efficient unlabeled sample selection method to replace high computational generators and focus on improving the training efficiency of the selected samples. Then, a class-dropping mechanism is designed to suppress the label noise caused by the data domain shifts. Finally, we propose a distillation method that incorporates explicit features and implicit structured relations to improve the effect of distillation. Experimental results show that our method can quickly converge and obtain higher accuracy than other state-of-the-art methods.