 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling to Distill: Knowledge Transfer from Open-World Data
Jul 31, 2023Data-Free Knowledge Distillation (DFKD) is a novel task that aims to train high-performance student models using only the teacher network without original training data. Despite encouraging results, existing DFKD methods rely heavily on generation modules with high computational costs. Meanwhile, they ignore the fact that the generated and original data exist domain shifts due to the lack of supervision information. Moreover, knowledge is transferred through each example, ignoring the implicit relationship among multiple examples. To this end, we propose a novel Open-world Data Sampling Distillation (ODSD) method without a redundant generation process. First, we try to sample open-world data close to the original data's distribution by an adaptive sampling module. Then, we introduce a low-noise representation to alleviate the domain shifts and build a structured relationship of multiple data examples to exploit data knowledge. Extensive experiments on CIFAR-10, CIFAR-100, NYUv2, and ImageNet show that our ODSD method achieves state-of-the-art performance. Especially, we improve 1.50\%-9.59\% accuracy on the ImageNet dataset compared with the existing results.
Explicit and Implicit Knowledge Distillation via Unlabeled Data
Feb 23, 2023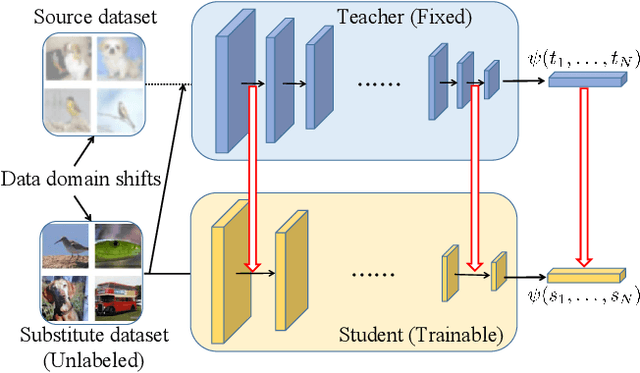
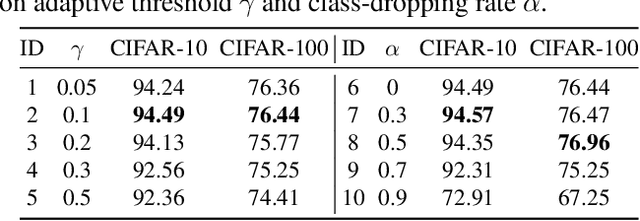
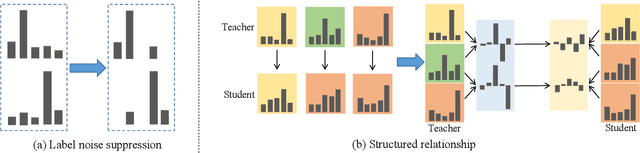
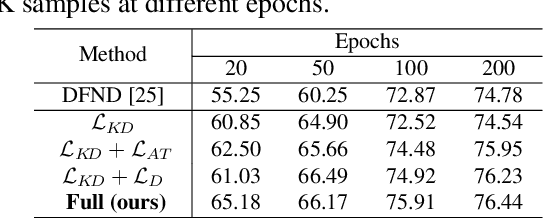
Data-free knowledge distillation is a challenging model lightweight task for scenarios in which the original dataset is not available. Previous methods require a lot of extra computational costs to update one or more generators and their naive imitate-learning lead to lower distillation efficiency. Based on these observations, we first propose an efficient unlabeled sample selection method to replace high computational generators and focus on improving the training efficiency of the selected samples. Then, a class-dropping mechanism is designed to suppress the label noise caused by the data domain shifts. Finally, we propose a distillation method that incorporates explicit features and implicit structured relations to improve the effect of distillation. Experimental results show that our method can quickly converge and obtain higher accuracy than other state-of-the-art methods.