 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit and Implicit Knowledge Distillation via Unlabeled Data
Feb 23, 2023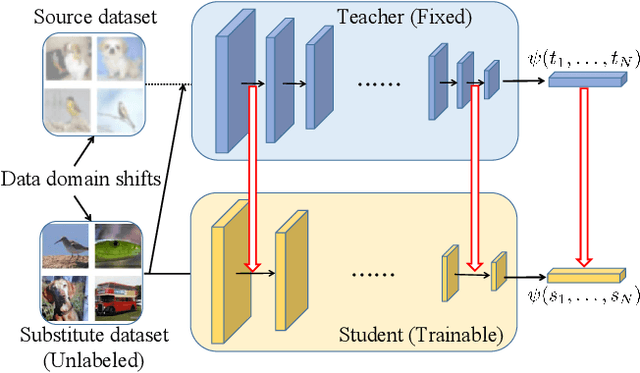
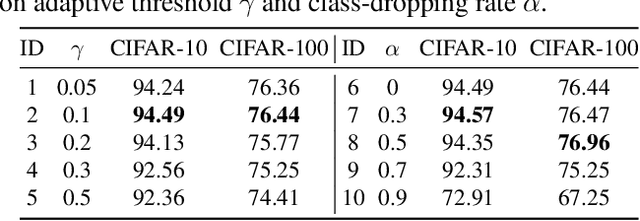
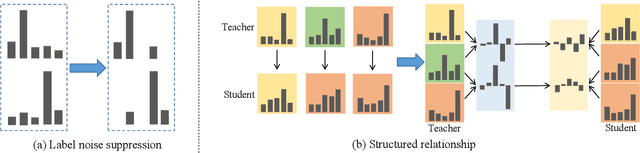
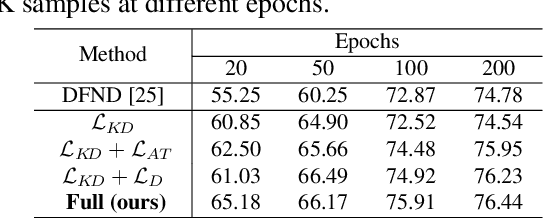
Data-free knowledge distillation is a challenging model lightweight task for scenarios in which the original dataset is not available. Previous methods require a lot of extra computational costs to update one or more generators and their naive imitate-learning lead to lower distillation efficiency. Based on these observations, we first propose an efficient unlabeled sample selection method to replace high computational generators and focus on improving the training efficiency of the selected samples. Then, a class-dropping mechanism is designed to suppress the label noise caused by the data domain shifts. Finally, we propose a distillation method that incorporates explicit features and implicit structured relations to improve the effect of distillation. Experimental results show that our method can quickly converge and obtain higher accuracy than other state-of-the-art methods.