 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Transferability of Visual-Language Pre-training Models through Collaborative Multimodal Interaction
Mar 16, 2024Despite the substantial advancements in Vision-Language Pre-training (VLP) models, their susceptibility to adversarial attacks poses a significant challenge. Existing work rarely studies the transferability of attacks on VLP models, resulting in a substantial performance gap from white-box attacks. We observe that prior work overlooks the interaction mechanisms between modalities, which plays a crucial role in understanding the intricacies of VLP models. In response, we propose a novel attack, called Collaborative Multimodal Interaction Attack (CMI-Attack), leveraging modality interaction through embedding guidance and interaction enhancement. Specifically, attacking text at the embedding level while preserving semantics, as well as utilizing interaction image gradients to enhance constraints on perturbations of texts and images. Significantly, in the image-text retrieval task on Flickr30K dataset, CMI-Attack raises the transfer success rates from ALBEF to TCL, $\text{CLIP}_{\text{ViT}}$ and $\text{CLIP}_{\text{CNN}}$ by 8.11%-16.75% over state-of-the-art methods. Moreover, CMI-Attack also demonstrates superior performance in cross-task generalization scenarios. Our work addresses the underexplored realm of transfer attacks on VLP models, shedding light on the importance of modality interaction for enhanced adversarial robustness.
Efficient Decision-based Black-box Patch Attacks on Video Recognition
Mar 21, 2023



Although Deep Neural Networks (DNNs) have demonstrated excellent performance, they are vulnerable to adversarial patches that introduce perceptible and localized perturbations to the input. Generating adversarial patches on images has received much attention, while adversarial patches on videos have not been well investigated. Further, decision-based attacks, where attackers only access the predicted hard labels by querying threat models, have not been well explored on video models either, even if they are practical in real-world video recognition scenes. The absence of such studies leads to a huge gap in the robustness assessment for video models. To bridge this gap, this work first explores decision-based patch attacks on video models. We analyze that the huge parameter space brought by videos and the minimal information returned by decision-based models both greatly increase the attack difficulty and query burden. To achieve a query-efficient attack, we propose a spatial-temporal differential evolution (STDE) framework. First, STDE introduces target videos as patch textures and only adds patches on keyframes that are adaptively selected by temporal difference. Second, STDE takes minimizing the patch area as the optimization objective and adopts spatialtemporal mutation and crossover to search for the global optimum without falling into the local optimum. Experiments show STDE has demonstrated state-of-the-art performance in terms of threat, efficiency and imperceptibility. Hence, STDE has the potential to be a powerful tool for evaluating the robustness of video recognition models.
Boosting the Transferability of Adversarial Attacks with Global Momentum Initialization
Nov 21, 2022Deep neural networks are vulnerable to adversarial examples, which attach human invisible perturbations to benign inputs. Simultaneously, adversarial examples exhibit transferability under different models, which makes practical black-box attacks feasible. However, existing methods are still incapable of achieving desired transfer attack performance. In this work, from the perspective of gradient optimization and consistency, we analyze and discover the gradient elimination phenomenon as well as the local momentum optimum dilemma. To tackle these issues, we propose Global Momentum Initialization (GI) to suppress gradient elimination and help search for the global optimum. Specifically, we perform gradient pre-convergence before the attack and carry out a global search during the pre-convergence stage. Our method can be easily combined with almost all existing transfer methods, and we improve the success rate of transfer attacks significantly by an average of 6.4% under various advanced defense mechanisms compared to state-of-the-art methods. Eventually, we achieve an attack success rate of 95.4%, fully illustrating the insecurity of existing defense mechanisms.
Efficient universal shuffle attack for visual object tracking
Mar 14, 2022
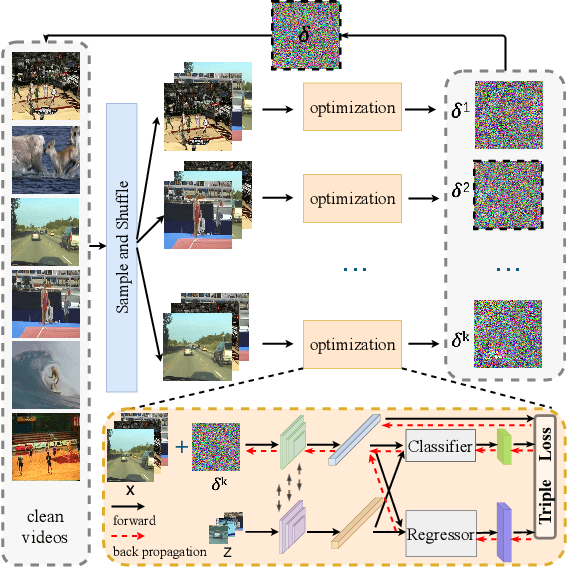
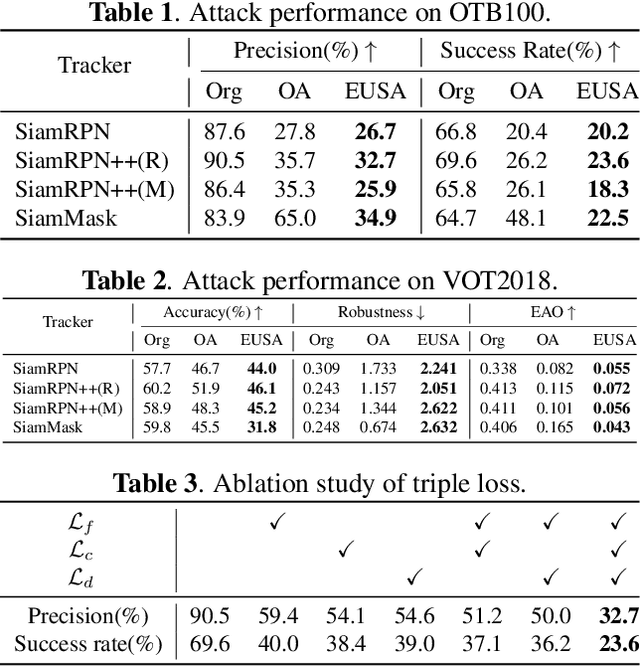
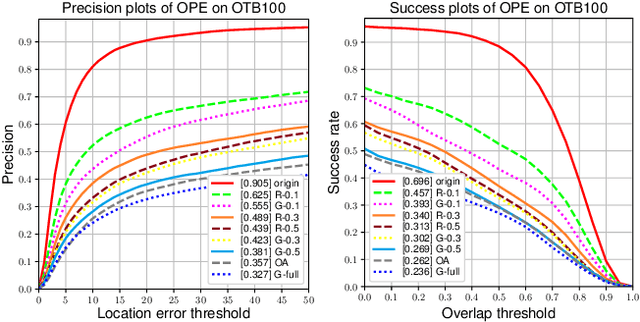
Recently, adversarial attacks have been applied in visual object tracking to deceive deep trackers by injecting imperceptible perturbations into video frames. However, previous work only generates the video-specific perturbations, which restricts its application scenarios. In addition, existing attacks are difficult to implement in reality due to the real-time of tracking and the re-initialization mechanism. To address these issues, we propose an offline universal adversarial attack called Efficient Universal Shuffle Attack. It takes only one perturbation to cause the tracker malfunction on all videos. To improve the computational efficiency and attack performance, we propose a greedy gradient strategy and a triple loss to efficiently capture and attack model-specific feature representations through the gradients. Experimental results show that EUSA can significantly reduce the performance of state-of-the-art trackers on OTB2015 and VOT2018.