 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-Scan-Refine: From Human Visual Perception to Efficient Visual Token Pruning
Feb 05, 2026Vision-language models (VLMs) often generate massive visual tokens that greatly increase inference latency and memory footprint; while training-free token pruning offers a practical remedy, existing methods still struggle to balance local evidence and global context under aggressive compression. We propose Focus-Scan-Refine (FSR), a human-inspired, plug-and-play pruning framework that mimics how humans answer visual questions: focus on key evidence, then scan globally if needed, and refine the scanned context by aggregating relevant details. FSR first focuses on key evidence by combining visual importance with instruction relevance, avoiding the bias toward visually salient but query-irrelevant regions. It then scans for complementary context conditioned on the focused set, selecting tokens that are most different from the focused evidence. Finally, FSR refines the scanned context by aggregating nearby informative tokens into the scan anchors via similarity-based assignment and score-weighted merging, without increasing the token budget. Extensive experiments across multiple VLM backbones and vision-language benchmarks show that FSR consistently improves the accuracy-efficiency trade-off over existing state-of-the-art pruning methods. The source codes can be found at https://github.com/ILOT-code/FSR
Rethinking Autoregressive Models for Lossless Image Compression via Hierarchical Parallelism and Progressive Adaptation
Nov 14, 2025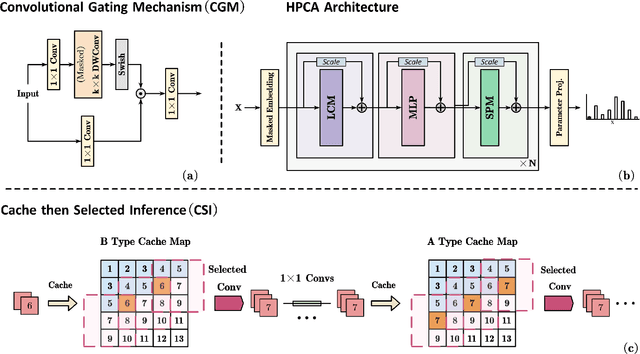
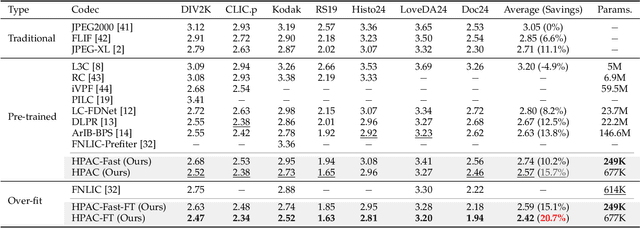
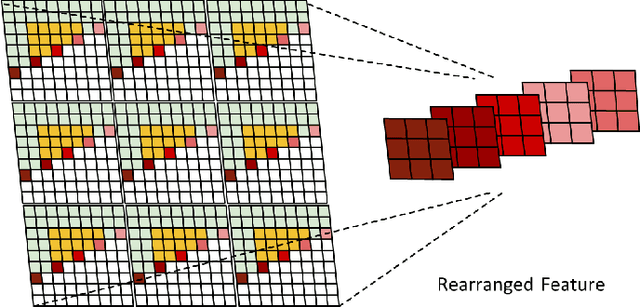
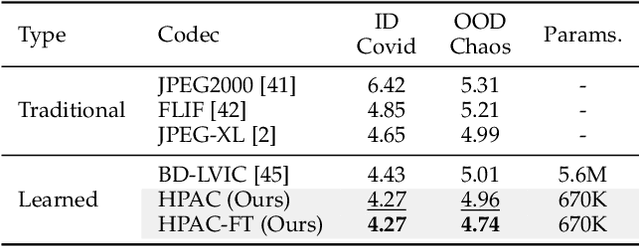
Autoregressive (AR) models, the theoretical performance benchmark for learned lossless image compression, are often dismissed as impractical due to prohibitive computational cost. This work re-thinks this paradigm, introducing a framework built on hierarchical parallelism and progressive adaptation that re-establishes pure autoregression as a top-performing and practical solution. Our approach is embodied in the Hierarchical Parallel Autoregressive ConvNet (HPAC), an ultra-lightweight pre-trained model using a hierarchical factorized structure and content-aware convolutional gating to efficiently capture spatial dependencies. We introduce two key optimizations for practicality: Cache-then-Select Inference (CSI), which accelerates coding by eliminating redundant computations, and Adaptive Focus Coding (AFC), which efficiently extends the framework to high bit-depth images. Building on this efficient foundation, our progressive adaptation strategy is realized by Spatially-Aware Rate-Guided Progressive Fine-tuning (SARP-FT). This instance-level strategy fine-tunes the model for each test image by optimizing low-rank adapters on progressively larger, spatially-continuous regions selected via estimated information density. Experiments on diverse datasets (natural, satellite, medical) validate that our method achieves new state-of-the-art compression. Notably, our approach sets a new benchmark in learned lossless compression, showing a carefully designed AR framework can offer significant gains over existing methods with a small parameter count and competitive coding speeds.
CALLIC: Content Adaptive Learning for Lossless Image Compression
Dec 23, 2024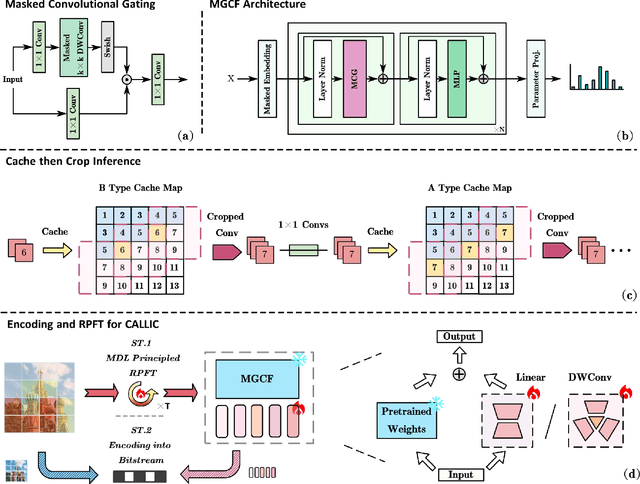
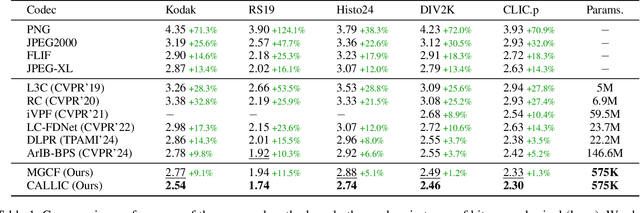
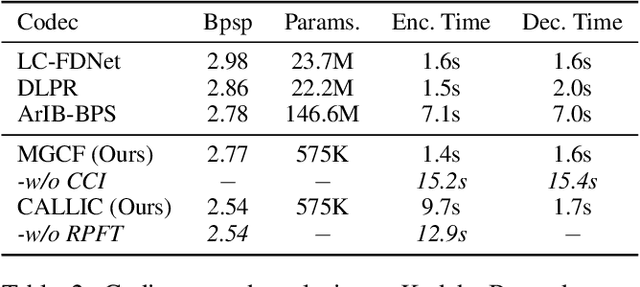
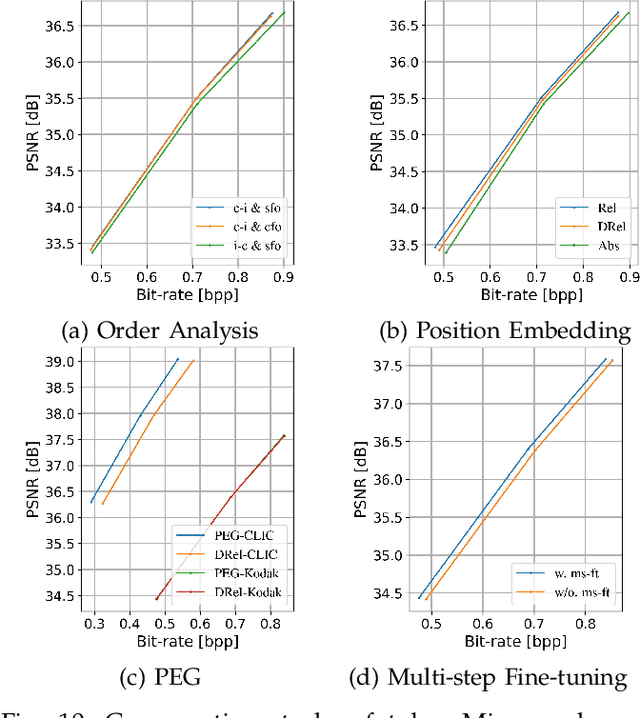
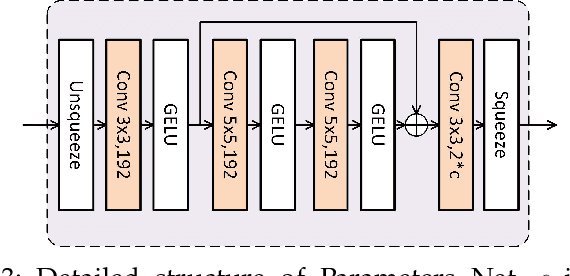
Learned lossless image compression has achieved significant advancements in recent years. However, existing methods often rely on training amortized generative models on massive datasets, resulting in sub-optimal probability distribution estimation for specific testing images during encoding process. To address this challenge, we explore the connection between the Minimum Description Length (MDL) principle and Parameter-Efficient Transfer Learning (PETL), leading to the development of a novel content-adaptive approach for learned lossless image compression, dubbed CALLIC. Specifically, we first propose a content-aware autoregressive self-attention mechanism by leveraging convolutional gating operations, termed Masked Gated ConvFormer (MGCF), and pretrain MGCF on training dataset. Cache then Crop Inference (CCI) is proposed to accelerate the coding process. During encoding, we decompose pre-trained layers, including depth-wise convolutions, using low-rank matrices and then adapt the incremental weights on testing image by Rate-guided Progressive Fine-Tuning (RPFT). RPFT fine-tunes with gradually increasing patches that are sorted in descending order by estimated entropy, optimizing learning process and reducing adaptation time. Extensive experiments across diverse datasets demonstrate that CALLIC sets a new state-of-the-art (SOTA) for learned lossless image compression.
Learning Lossless Compression for High Bit-Depth Volumetric Medical Image
Oct 23, 2024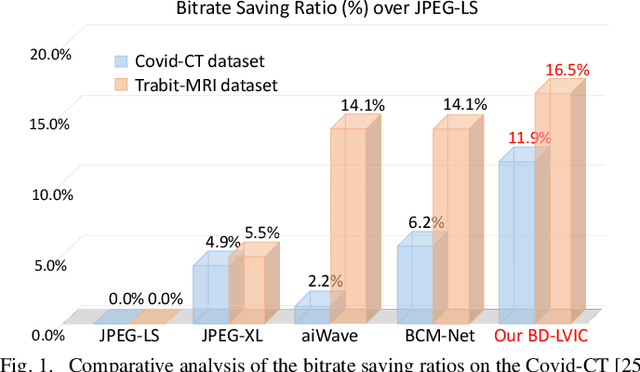
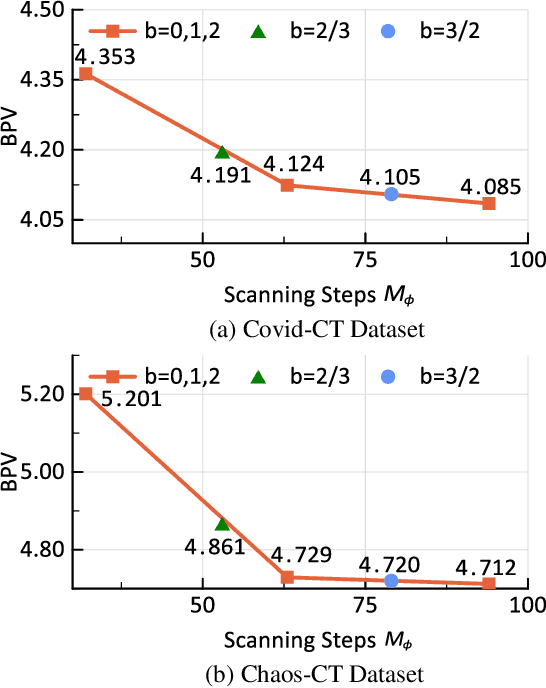
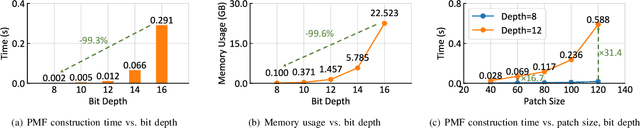
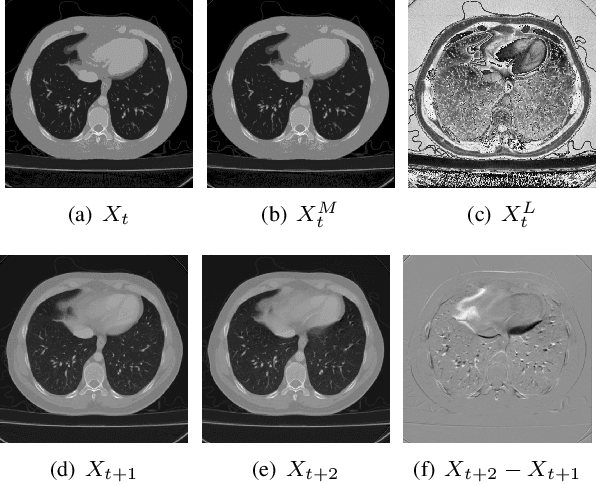
Recent advances in learning-based methods have markedly enhanced the capabilities of image compression. However, these methods struggle with high bit-depth volumetric medical images, facing issues such as degraded performance, increased memory demand, and reduced processing speed. To address these challenges, this paper presents the Bit-Division based Lossless Volumetric Image Compression (BD-LVIC) framework, which is tailored for high bit-depth medical volume compression. The BD-LVIC framework skillfully divides the high bit-depth volume into two lower bit-depth segments: the Most Significant Bit-Volume (MSBV) and the Least Significant Bit-Volume (LSBV). The MSBV concentrates on the most significant bits of the volumetric medical image, capturing vital structural details in a compact manner. This reduction in complexity greatly improves compression efficiency using traditional codecs. Conversely, the LSBV deals with the least significant bits, which encapsulate intricate texture details. To compress this detailed information effectively, we introduce an effective learning-based compression model equipped with a Transformer-Based Feature Alignment Module, which exploits both intra-slice and inter-slice redundancies to accurately align features. Subsequently, a Parallel Autoregressive Coding Module merges these features to precisely estimate the probability distribution of the least significant bit-planes. Our extensive testing demonstrates that the BD-LVIC framework not only sets new performance benchmarks across various datasets but also maintains a competitive coding speed, highlighting its significant potential and practical utility in the realm of volumetric medical image compression.
GroupedMixer: An Entropy Model with Group-wise Token-Mixers for Learned Image Compression
May 02, 2024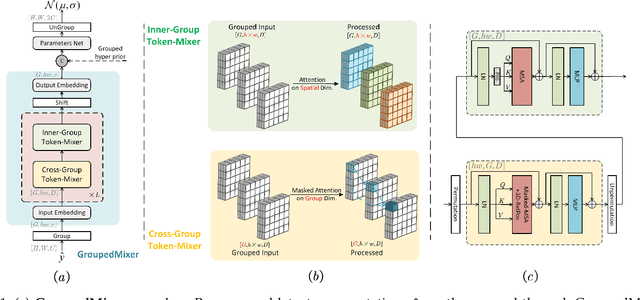
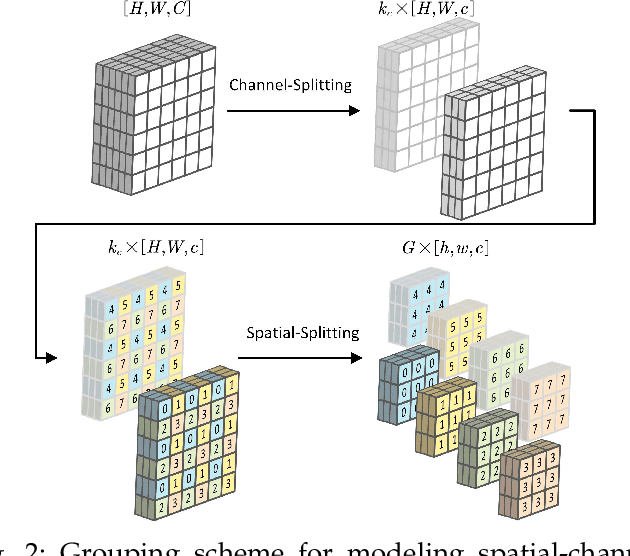
Transformer-based entropy models have gained prominence in recent years due to their superior ability to capture long-range dependencies in probability distribution estimation compared to convolution-based methods. However, previous transformer-based entropy models suffer from a sluggish coding process due to pixel-wise autoregression or duplicated computation during inference. In this paper, we propose a novel transformer-based entropy model called GroupedMixer, which enjoys both faster coding speed and better compression performance than previous transformer-based methods. Specifically, our approach builds upon group-wise autoregression by first partitioning the latent variables into groups along spatial-channel dimensions, and then entropy coding the groups with the proposed transformer-based entropy model. The global causal self-attention is decomposed into more efficient group-wise interactions, implemented using inner-group and cross-group token-mixers. The inner-group token-mixer incorporates contextual elements within a group while the cross-group token-mixer interacts with previously decoded groups. Alternate arrangement of two token-mixers enables global contextual reference. To further expedite the network inference, we introduce context cache optimization to GroupedMixer, which caches attention activation values in cross-group token-mixers and avoids complex and duplicated computation. Experimental results demonstrate that the proposed GroupedMixer yields the state-of-the-art rate-distortion performance with fast compression speed.
Semantic Ensemble Loss and Latent Refinement for High-Fidelity Neural Image Compression
Jan 25, 2024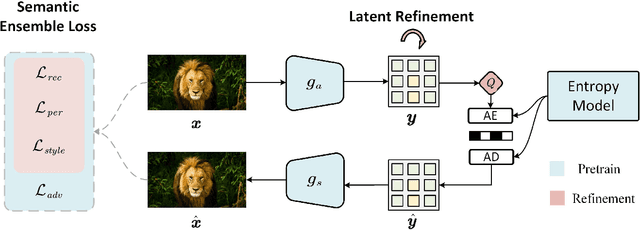

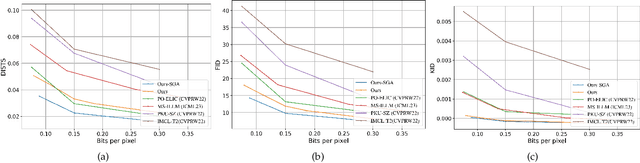

Recent advancements in neural compression have surpassed traditional codecs in PSNR and MS-SSIM measurements. However, at low bit-rates, these methods can introduce visually displeasing artifacts, such as blurring, color shifting, and texture loss, thereby compromising perceptual quality of images. To address these issues, this study presents an enhanced neural compression method designed for optimal visual fidelity. We have trained our model with a sophisticated semantic ensemble loss, integrating Charbonnier loss, perceptual loss, style loss, and a non-binary adversarial loss, to enhance the perceptual quality of image reconstructions. Additionally, we have implemented a latent refinement process to generate content-aware latent codes. These codes adhere to bit-rate constraints, balance the trade-off between distortion and fidelity, and prioritize bit allocation to regions of greater importance. Our empirical findings demonstrate that this approach significantly improves the statistical fidelity of neural image compression. On CLIC2024 validation set, our approach achieves a 62% bitrate saving compared to MS-ILLM under FID metric.
AdaptIR: Parameter Efficient Multi-task Adaptation for Pre-trained Image Restoration Models
Dec 12, 2023Pre-training has shown promising results on various image restoration tasks, which is usually followed by full fine-tuning for each specific downstream task (e.g., image denoising). However, such full fine-tuning usually suffers from the problems of heavy computational cost in practice, due to the massive parameters of pre-trained restoration models, thus limiting its real-world applications. Recently, Parameter Efficient Transfer Learning (PETL) offers an efficient alternative solution to full fine-tuning, yet still faces great challenges for pre-trained image restoration models, due to the diversity of different degradations. To address these issues, we propose AdaptIR, a novel parameter efficient transfer learning method for adapting pre-trained restoration models. Specifically, the proposed method consists of a multi-branch inception structure to orthogonally capture local spatial, global spatial, and channel interactions. In this way, it allows powerful representations under a very low parameter budget. Extensive experiments demonstrate that the proposed method can achieve comparable or even better performance than full fine-tuning, while only using 0.6% parameters. Code is available at https://github.com/csguoh/AdaptIR.
Incorporating Transformer Designs into Convolutions for Lightweight Image Super-Resolution
Mar 25, 2023In recent years, the use of large convolutional kernels has become popular in designing convolutional neural networks due to their ability to capture long-range dependencies and provide large receptive fields. However, the increase in kernel size also leads to a quadratic growth in the number of parameters, resulting in heavy computation and memory requirements. To address this challenge, we propose a neighborhood attention (NA) module that upgrades the standard convolution with a self-attention mechanism. The NA module efficiently extracts long-range dependencies in a sliding window pattern, thereby achieving similar performance to large convolutional kernels but with fewer parameters. Building upon the NA module, we propose a lightweight single image super-resolution (SISR) network named TCSR. Additionally, we introduce an enhanced feed-forward network (EFFN) in TCSR to improve the SISR performance. EFFN employs a parameter-free spatial-shift operation for efficient feature aggregation. Our extensive experiments and ablation studies demonstrate that TCSR outperforms existing lightweight SISR methods and achieves state-of-the-art performance. Our codes are available at \url{https://github.com/Aitical/TCSR}.
Multi-Camera Collaborative Depth Prediction via Consistent Structure Estimation
Oct 05, 2022


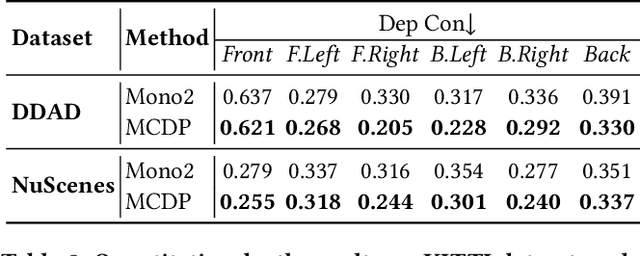
Depth map estimation from images is an important task in robotic systems. Existing methods can be categorized into two groups including multi-view stereo and monocular depth estimation. The former requires cameras to have large overlapping areas and sufficient baseline between cameras, while the latter that processes each image independently can hardly guarantee the structure consistency between cameras. In this paper, we propose a novel multi-camera collaborative depth prediction method that does not require large overlapping areas while maintaining structure consistency between cameras. Specifically, we formulate the depth estimation as a weighted combination of depth basis, in which the weights are updated iteratively by a refinement network driven by the proposed consistency loss. During the iterative update, the results of depth estimation are compared across cameras and the information of overlapping areas is propagated to the whole depth maps with the help of basis formulation. Experimental results on DDAD and NuScenes datasets demonstrate the superior performance of our method.
Deep Lossy Plus Residual Coding for Lossless and Near-lossless Image Compression
Sep 11, 2022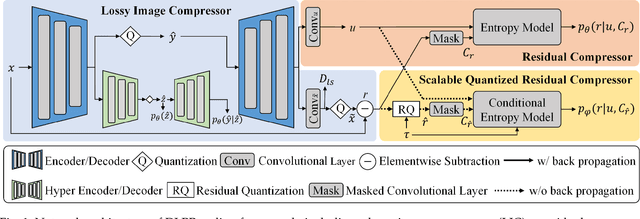

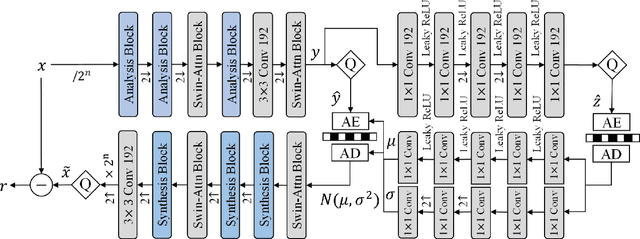
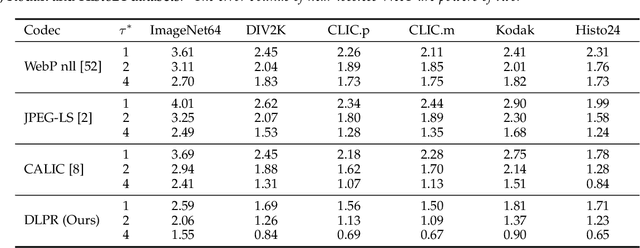
Lossless and near-lossless image compression is of paramount importance to professional users in many technical fields, such as medicine, remote sensing, precision engineering and scientific research. But despite rapidly growing research interests in learning-based image compression, no published method offers both lossless and near-lossless modes. In this paper, we propose a unified and powerful deep lossy plus residual (DLPR) coding framework for both lossless and near-lossless image compression. In the lossless mode, the DLPR coding system first performs lossy compression and then lossless coding of residuals. We solve the joint lossy and residual compression problem in the approach of VAEs, and add autoregressive context modeling of the residuals to enhance lossless compression performance. In the near-lossless mode, we quantize the original residuals to satisfy a given $\ell_\infty$ error bound, and propose a scalable near-lossless compression scheme that works for variable $\ell_\infty$ bounds instead of training multiple networks. To expedite the DLPR coding, we increase the degree of algorithm parallelization by a novel design of coding context, and accelerate the entropy coding with adaptive residual interval. Experimental results demonstrate that the DLPR coding system achieves both the state-of-the-art lossless and near-lossless image compression performance with competitive coding speed.