 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupedMixer: An Entropy Model with Group-wise Token-Mixers for Learned Image Compression
Paper and Code
May 02, 2024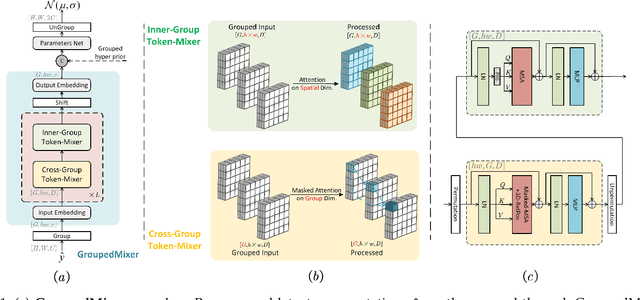
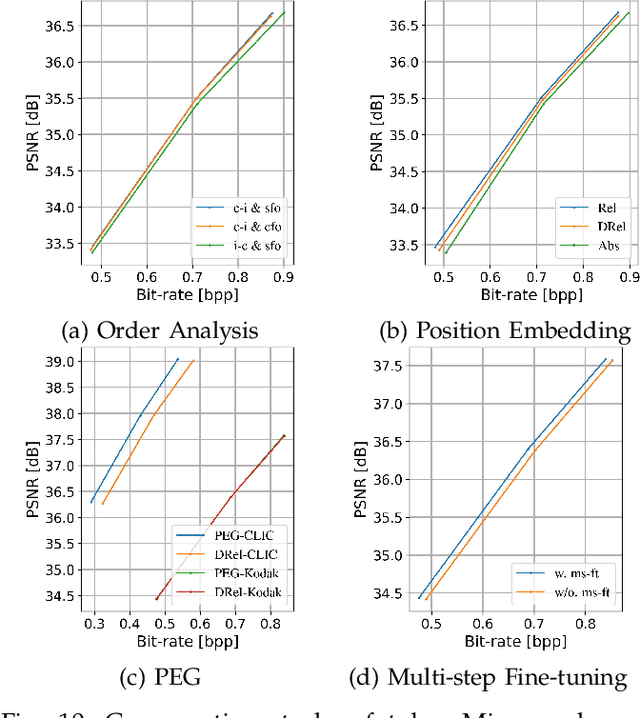
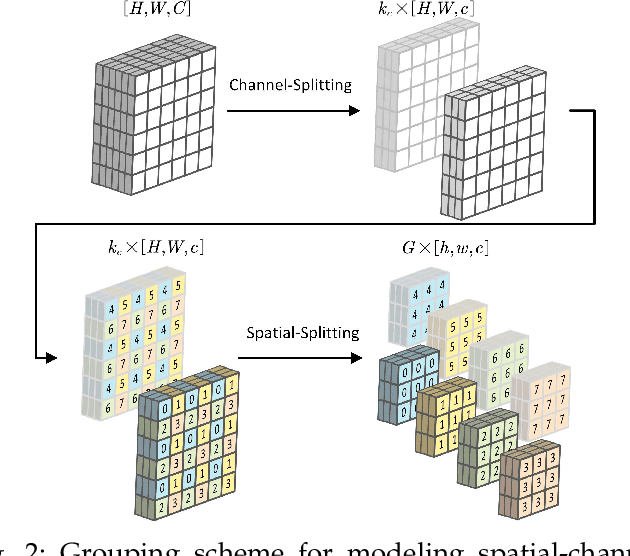
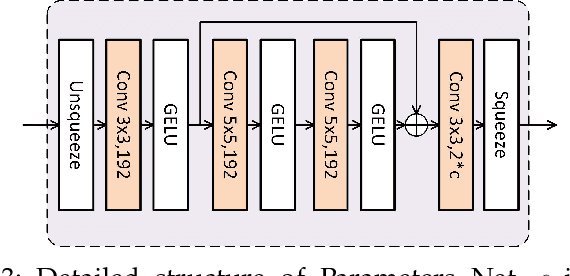
Transformer-based entropy models have gained prominence in recent years due to their superior ability to capture long-range dependencies in probability distribution estimation compared to convolution-based methods. However, previous transformer-based entropy models suffer from a sluggish coding process due to pixel-wise autoregression or duplicated computation during inference. In this paper, we propose a novel transformer-based entropy model called GroupedMixer, which enjoys both faster coding speed and better compression performance than previous transformer-based methods. Specifically, our approach builds upon group-wise autoregression by first partitioning the latent variables into groups along spatial-channel dimensions, and then entropy coding the groups with the proposed transformer-based entropy model. The global causal self-attention is decomposed into more efficient group-wise interactions, implemented using inner-group and cross-group token-mixers. The inner-group token-mixer incorporates contextual elements within a group while the cross-group token-mixer interacts with previously decoded groups. Alternate arrangement of two token-mixers enables global contextual reference. To further expedite the network inference, we introduce context cache optimization to GroupedMixer, which caches attention activation values in cross-group token-mixers and avoids complex and duplicated computation. Experimental results demonstrate that the proposed GroupedMixer yields the state-of-the-art rate-distortion performance with fast compression speed.