 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Image-Related Inductive Biases in Single-Branch Visual Tracking
Oct 30, 2023



Despite achieving state-of-the-art performance in visual tracking, recent single-branch trackers tend to overlook the weak prior assumptions associated with the Vision Transformer (ViT) encoder and inference pipeline. Moreover, the effectiveness of discriminative trackers remains constrained due to the adoption of the dual-branch pipeline. To tackle the inferior effectiveness of the vanilla ViT, we propose an Adaptive ViT Model Prediction tracker (AViTMP) to bridge the gap between single-branch network and discriminative models. Specifically, in the proposed encoder AViT-Enc, we introduce an adaptor module and joint target state embedding to enrich the dense embedding paradigm based on ViT. Then, we combine AViT-Enc with a dense-fusion decoder and a discriminative target model to predict accurate location. Further, to mitigate the limitations of conventional inference practice, we present a novel inference pipeline called CycleTrack, which bolsters the tracking robustness in the presence of distractors via bidirectional cycle tracking verification. Lastly, we propose a dual-frame update inference strategy that adeptively handles significant challenges in long-term scenarios. In the experiments, we evaluate AViTMP on ten tracking benchmarks for a comprehensive assessment, including LaSOT, LaSOTExtSub, AVisT, etc. The experimental results unequivocally establish that AViTMP attains state-of-the-art performance, especially on long-time tracking and robustness.
Learning Spatial-Frequency Transformer for Visual Object Tracking
Aug 18, 2022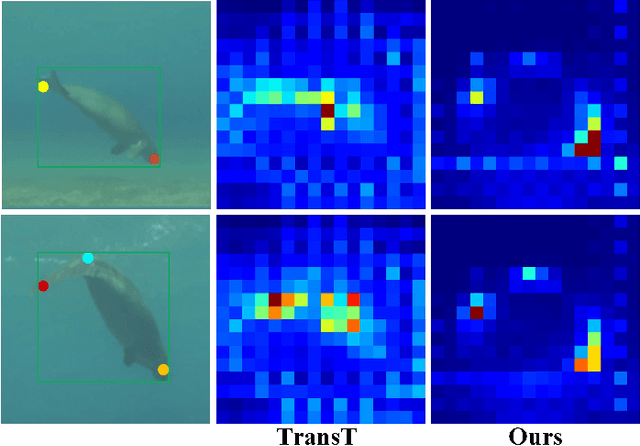
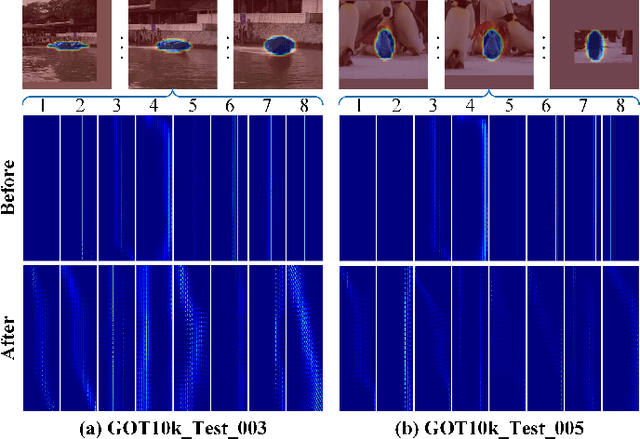

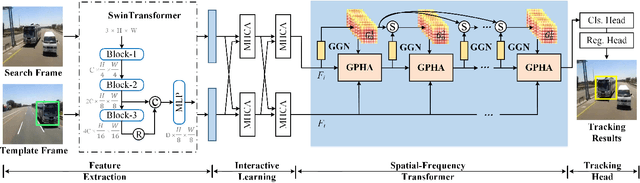
Recent trackers adopt the Transformer to combine or replace the widely used ResNet as their new backbone network. Although their trackers work well in regular scenarios, however, they simply flatten the 2D features into a sequence to better match the Transformer. We believe these operations ignore the spatial prior of the target object which may lead to sub-optimal results only. In addition, many works demonstrate that self-attention is actually a low-pass filter, which is independent of input features or key/queries. That is to say, it may suppress the high-frequency component of the input features and preserve or even amplify the low-frequency information. To handle these issues, in this paper, we propose a unified Spatial-Frequency Transformer that models the Gaussian spatial Prior and High-frequency emphasis Attention (GPHA) simultaneously. To be specific, Gaussian spatial prior is generated using dual Multi-Layer Perceptrons (MLPs) and injected into the similarity matrix produced by multiplying Query and Key features in self-attention. The output will be fed into a Softmax layer and then decomposed into two components, i.e., the direct signal and high-frequency signal. The low- and high-pass branches are rescaled and combined to achieve all-pass, therefore, the high-frequency features will be protected well in stacked self-attention layers. We further integrate the Spatial-Frequency Transformer into the Siamese tracking framework and propose a novel tracking algorithm, termed SFTransT. The cross-scale fusion based SwinTransformer is adopted as the backbone, and also a multi-head cross-attention module is used to boost the interaction between search and template features. The output will be fed into the tracking head for target localization. Extensive experiments on both short-term and long-term tracking benchmarks all demonstrate the effectiveness of our proposed framework.