 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiaisonAgent: An Multi-Agent Framework for Autonomous Risk Investigation and Governance
Feb 27, 2026The rapid evolution of sophisticated cyberattacks has strained modern Security Operations Centers (SOC), which traditionally rely on rule-based or signature-driven detection systems. These legacy frameworks often generate high volumes of technical alerts that lack organizational context, leading to analyst fatigue and delayed incident responses. This paper presents LiaisonAgent, an autonomous multi-agent system designed to bridge the gap between technical risk detection and business-level risk governance. Built upon the QWQ-32B large reasoning model, LiaisonAgent integrates specialized sub-agents, including human-computer interaction agents, comprehensive judgment agents, and automated disposal agents-to execute end-to-end investigation workflows. The system leverages a hybrid planning architecture that combines deterministic workflows for compliance with autonomous reasoning based on the ReAct paradigm to handle ambiguous operational scenarios. Experimental evaluations across diverse security contexts, such as large-scale data exfiltration and unauthorized account borrowing, achieve an end-to-end tool-calling success rate of 97.8% and a risk judgment accuracy of 95%. Furthermore, the system exhibits significant resilience against out-of-distribution noise and adversarial prompt injections, while achieving a 92.7% reduction in manual investigation overhead.
STCMOT: Spatio-Temporal Cohesion Learning for UAV-Based Multiple Object Tracking
Sep 17, 2024



Multiple object tracking (MOT) in Unmanned Aerial Vehicle (UAV) videos is important for diverse applications in computer vision. Current MOT trackers rely on accurate object detection results and precise matching of target reidentification (ReID). These methods focus on optimizing target spatial attributes while overlooking temporal cues in modelling object relationships, especially for challenging tracking conditions such as object deformation and blurring, etc. To address the above-mentioned issues, we propose a novel Spatio-Temporal Cohesion Multiple Object Tracking framework (STCMOT), which utilizes historical embedding features to model the representation of ReID and detection features in a sequential order. Concretely, a temporal embedding boosting module is introduced to enhance the discriminability of individual embedding based on adjacent frame cooperation. While the trajectory embedding is then propagated by a temporal detection refinement module to mine salient target locations in the temporal field. Extensive experiments on the VisDrone2019 and UAVDT datasets demonstrate our STCMOT sets a new state-of-the-art performance in MOTA and IDF1 metrics. The source codes are released at https://github.com/ydhcg-BoBo/STCMOT.
LocInv: Localization-aware Inversion for Text-Guided Image Editing
May 02, 2024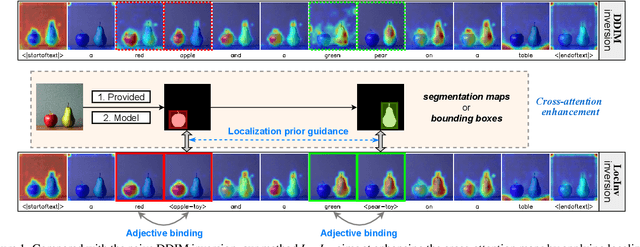
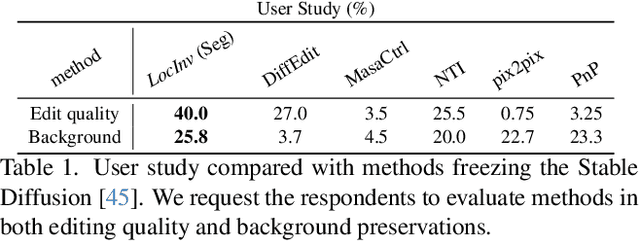
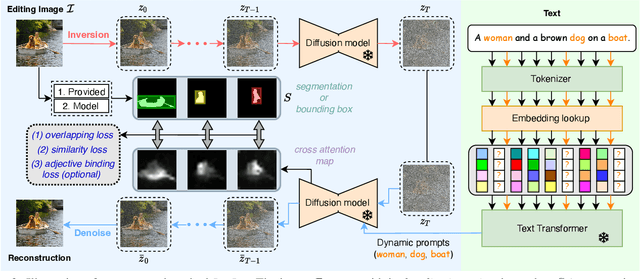
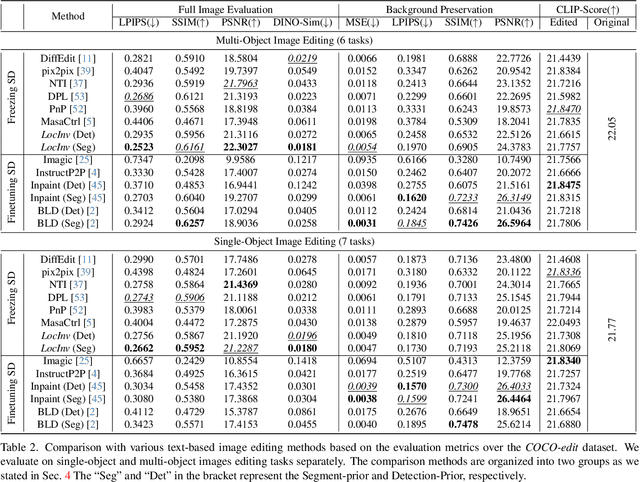
Large-scale Text-to-Image (T2I) diffusion models demonstrate significant generation capabilities based on textual prompts. Based on the T2I diffusion models, text-guided image editing research aims to empower users to manipulate generated images by altering the text prompts. However, existing image editing techniques are prone to editing over unintentional regions that are beyond the intended target area, primarily due to inaccuracies in cross-attention maps. To address this problem, we propose Localization-aware Inversion (LocInv), which exploits segmentation maps or bounding boxes as extra localization priors to refine the cross-attention maps in the denoising phases of the diffusion process. Through the dynamic updating of tokens corresponding to noun words in the textual input, we are compelling the cross-attention maps to closely align with the correct noun and adjective words in the text prompt. Based on this technique, we achieve fine-grained image editing over particular objects while preventing undesired changes to other regions. Our method LocInv, based on the publicly available Stable Diffusion, is extensively evaluated on a subset of the COCO dataset, and consistently obtains superior results both quantitatively and qualitatively.The code will be released at https://github.com/wangkai930418/DPL
Long-term Frame-Event Visual Tracking: Benchmark Dataset and Baseline
Mar 09, 2024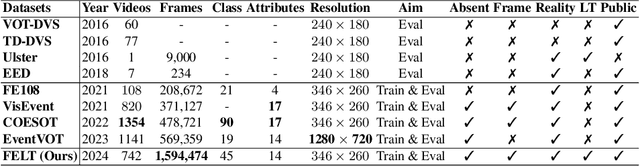
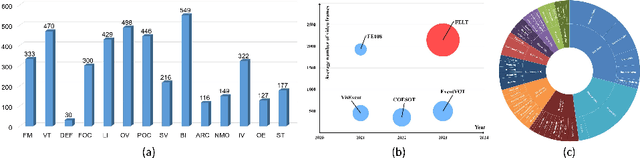
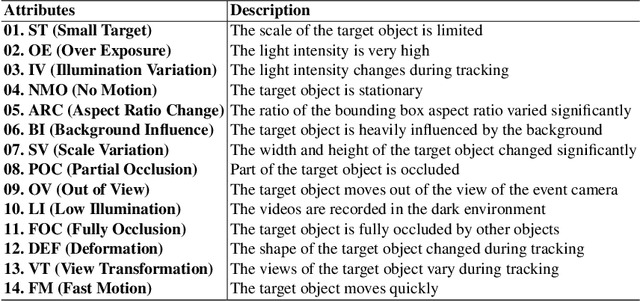

Current event-/frame-event based trackers undergo evaluation on short-term tracking datasets, however, the tracking of real-world scenarios involves long-term tracking, and the performance of existing tracking algorithms in these scenarios remains unclear. In this paper, we first propose a new long-term and large-scale frame-event single object tracking dataset, termed FELT. It contains 742 videos and 1,594,474 RGB frames and event stream pairs and has become the largest frame-event tracking dataset to date. We re-train and evaluate 15 baseline trackers on our dataset for future works to compare. More importantly, we find that the RGB frames and event streams are naturally incomplete due to the influence of challenging factors and spatially sparse event flow. In response to this, we propose a novel associative memory Transformer network as a unified backbone by introducing modern Hopfield layers into multi-head self-attention blocks to fuse both RGB and event data. Extensive experiments on both FELT and RGB-T tracking dataset LasHeR fully validated the effectiveness of our model. The dataset and source code can be found at \url{https://github.com/Event-AHU/FELT_SOT_Benchmark}.
Exploiting Image-Related Inductive Biases in Single-Branch Visual Tracking
Oct 30, 2023



Despite achieving state-of-the-art performance in visual tracking, recent single-branch trackers tend to overlook the weak prior assumptions associated with the Vision Transformer (ViT) encoder and inference pipeline. Moreover, the effectiveness of discriminative trackers remains constrained due to the adoption of the dual-branch pipeline. To tackle the inferior effectiveness of the vanilla ViT, we propose an Adaptive ViT Model Prediction tracker (AViTMP) to bridge the gap between single-branch network and discriminative models. Specifically, in the proposed encoder AViT-Enc, we introduce an adaptor module and joint target state embedding to enrich the dense embedding paradigm based on ViT. Then, we combine AViT-Enc with a dense-fusion decoder and a discriminative target model to predict accurate location. Further, to mitigate the limitations of conventional inference practice, we present a novel inference pipeline called CycleTrack, which bolsters the tracking robustness in the presence of distractors via bidirectional cycle tracking verification. Lastly, we propose a dual-frame update inference strategy that adeptively handles significant challenges in long-term scenarios. In the experiments, we evaluate AViTMP on ten tracking benchmarks for a comprehensive assessment, including LaSOT, LaSOTExtSub, AVisT, etc. The experimental results unequivocally establish that AViTMP attains state-of-the-art performance, especially on long-time tracking and robustness.
IterInv: Iterative Inversion for Pixel-Level T2I Models
Oct 30, 2023


Large-scale text-to-image diffusion models have been a ground-breaking development in generating convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are relying on DDIM inversion as a common practice based on the Latent Diffusion Models (LDM). However, the large pretrained T2I models working on the latent space as LDM suffer from losing details due to the first compression stage with an autoencoder mechanism. Instead, another mainstream T2I pipeline working on the pixel level, such as Imagen and DeepFloyd-IF, avoids this problem. They are commonly composed of several stages, normally with a text-to-image stage followed by several super-resolution stages. In this case, the DDIM inversion is unable to find the initial noise to generate the original image given that the super-resolution diffusion models are not compatible with the DDIM technique. According to our experimental findings, iteratively concatenating the noisy image as the condition is the root of this problem. Based on this observation, we develop an iterative inversion (IterInv) technique for this stream of T2I models and verify IterInv with the open-source DeepFloyd-IF model. By combining our method IterInv with a popular image editing method, we prove the application prospects of IterInv. The code will be released at \url{https://github.com/Tchuanm/IterInv.git}.
Event Stream-based Visual Object Tracking: A High-Resolution Benchmark Dataset and A Novel Baseline
Sep 26, 2023



Tracking using bio-inspired event cameras has drawn more and more attention in recent years. Existing works either utilize aligned RGB and event data for accurate tracking or directly learn an event-based tracker. The first category needs more cost for inference and the second one may be easily influenced by noisy events or sparse spatial resolution. In this paper, we propose a novel hierarchical knowledge distillation framework that can fully utilize multi-modal / multi-view information during training to facilitate knowledge transfer, enabling us to achieve high-speed and low-latency visual tracking during testing by using only event signals. Specifically, a teacher Transformer-based multi-modal tracking framework is first trained by feeding the RGB frame and event stream simultaneously. Then, we design a new hierarchical knowledge distillation strategy which includes pairwise similarity, feature representation, and response maps-based knowledge distillation to guide the learning of the student Transformer network. Moreover, since existing event-based tracking datasets are all low-resolution ($346 \times 260$), we propose the first large-scale high-resolution ($1280 \times 720$) dataset named EventVOT. It contains 1141 videos and covers a wide range of categories such as pedestrians, vehicles, UAVs, ping pongs, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, COESOT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. The dataset, evaluation toolkit, and source code are available on \url{https://github.com/Event-AHU/EventVOT_Benchmark}
Revisiting Color-Event based Tracking: A Unified Network, Dataset, and Metric
Nov 20, 2022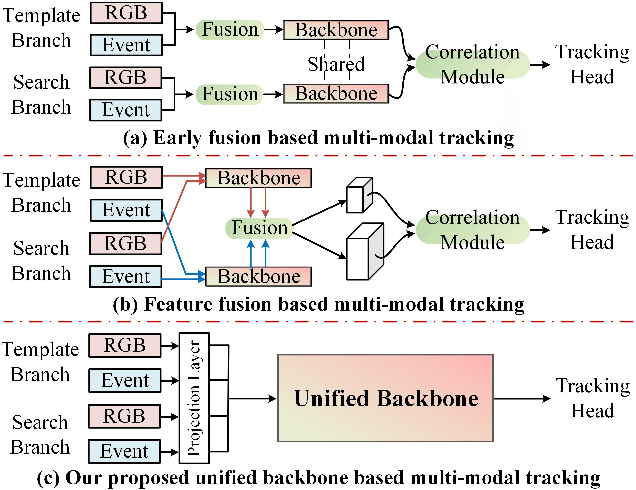

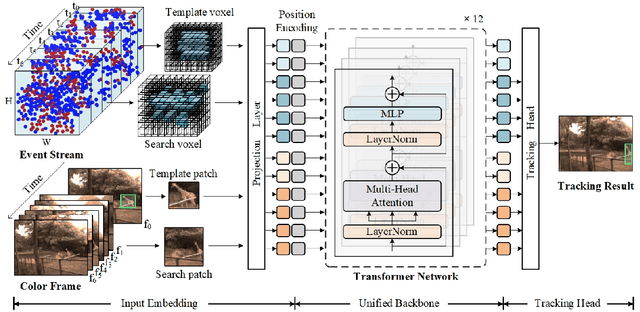

Combining the Color and Event cameras (also called Dynamic Vision Sensors, DVS) for robust object tracking is a newly emerging research topic in recent years. Existing color-event tracking framework usually contains multiple scattered modules which may lead to low efficiency and high computational complexity, including feature extraction, fusion, matching, interactive learning, etc. In this paper, we propose a single-stage backbone network for Color-Event Unified Tracking (CEUTrack), which achieves the above functions simultaneously. Given the event points and RGB frames, we first transform the points into voxels and crop the template and search regions for both modalities, respectively. Then, these regions are projected into tokens and parallelly fed into the unified Transformer backbone network. The output features will be fed into a tracking head for target object localization. Our proposed CEUTrack is simple, effective, and efficient, which achieves over 75 FPS and new SOTA performance. To better validate the effectiveness of our model and address the data deficiency of this task, we also propose a generic and large-scale benchmark dataset for color-event tracking, termed COESOT, which contains 90 categories and 1354 video sequences. Additionally, a new evaluation metric named BOC is proposed in our evaluation toolkit to evaluate the prominence with respect to the baseline methods. We hope the newly proposed method, dataset, and evaluation metric provide a better platform for color-event-based tracking. The dataset, toolkit, and source code will be released on: \url{https://github.com/Event-AHU/COESOT}.
Learning Spatial-Frequency Transformer for Visual Object Tracking
Aug 18, 2022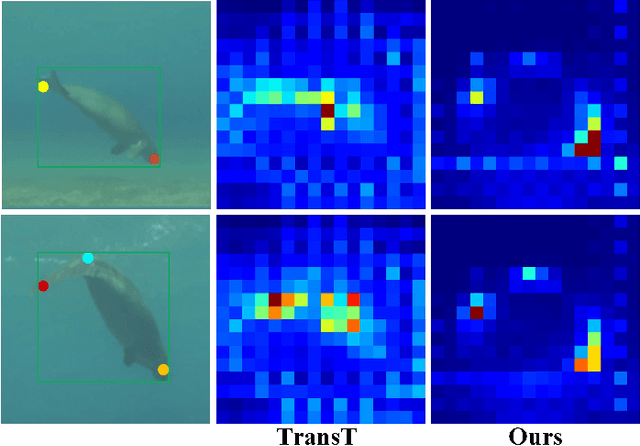
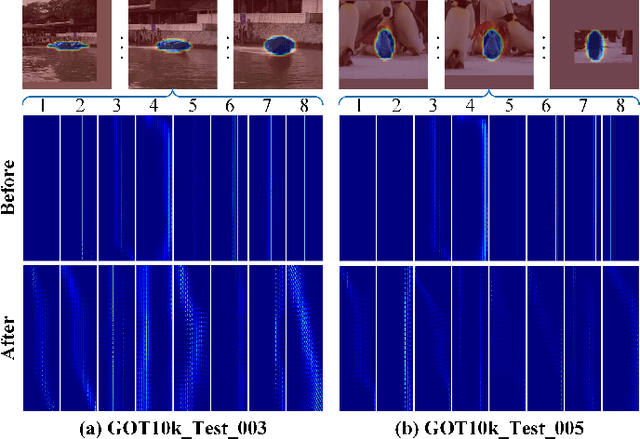

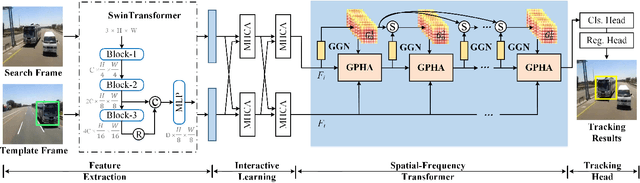
Recent trackers adopt the Transformer to combine or replace the widely used ResNet as their new backbone network. Although their trackers work well in regular scenarios, however, they simply flatten the 2D features into a sequence to better match the Transformer. We believe these operations ignore the spatial prior of the target object which may lead to sub-optimal results only. In addition, many works demonstrate that self-attention is actually a low-pass filter, which is independent of input features or key/queries. That is to say, it may suppress the high-frequency component of the input features and preserve or even amplify the low-frequency information. To handle these issues, in this paper, we propose a unified Spatial-Frequency Transformer that models the Gaussian spatial Prior and High-frequency emphasis Attention (GPHA) simultaneously. To be specific, Gaussian spatial prior is generated using dual Multi-Layer Perceptrons (MLPs) and injected into the similarity matrix produced by multiplying Query and Key features in self-attention. The output will be fed into a Softmax layer and then decomposed into two components, i.e., the direct signal and high-frequency signal. The low- and high-pass branches are rescaled and combined to achieve all-pass, therefore, the high-frequency features will be protected well in stacked self-attention layers. We further integrate the Spatial-Frequency Transformer into the Siamese tracking framework and propose a novel tracking algorithm, termed SFTransT. The cross-scale fusion based SwinTransformer is adopted as the backbone, and also a multi-head cross-attention module is used to boost the interaction between search and template features. The output will be fed into the tracking head for target localization. Extensive experiments on both short-term and long-term tracking benchmarks all demonstrate the effectiveness of our proposed framework.
Tsformer: Time series Transformer for tourism demand forecasting
Jul 22, 2021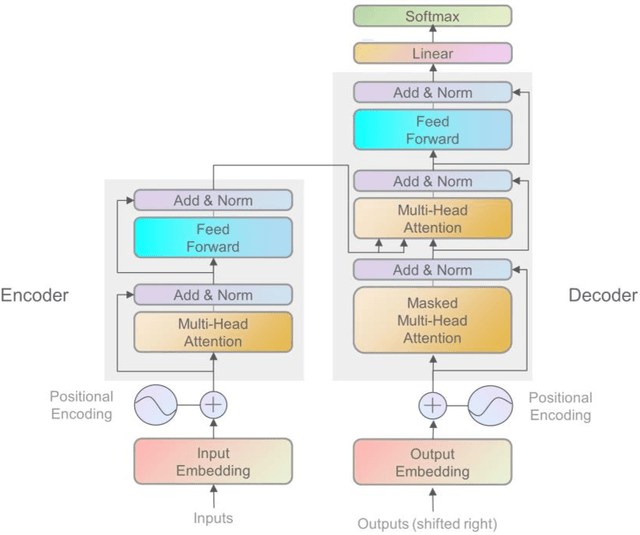
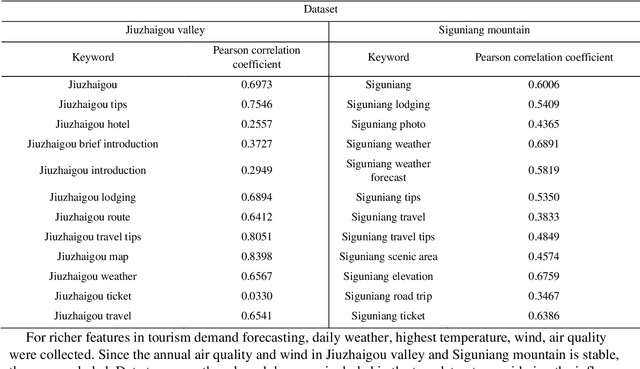
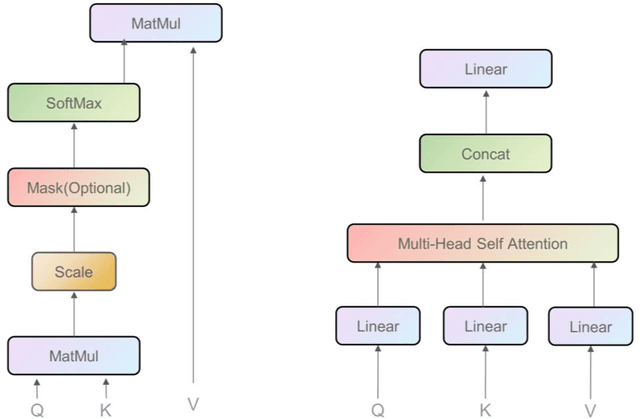

AI-based methods have been widely applied to tourism demand forecasting. However, current AI-based methods are short of the ability to process long-term dependency, and most of them lack interpretability. The Transformer used initially for machine translation shows an incredible ability to long-term dependency processing. Based on the Transformer, we proposed a time series Transformer (Tsformer) with Encoder-Decoder architecture for tourism demand forecasting. The proposed Tsformer encodes long-term dependency with encoder, captures short-term dependency with decoder, and simplifies the attention interactions under the premise of highlighting dominant attention through a series of attention masking mechanisms. These improvements make the multi-head attention mechanism process the input sequence according to the time relationship, contributing to better interpretability. What's more, the context processing ability of the Encoder-Decoder architecture allows adopting the calendar of days to be forecasted to enhance the forecasting performance. Experiments conducted on the Jiuzhaigou valley and Siguniang mountain tourism demand datasets with other nine baseline methods indicate that the proposed Tsformer outperformed all baseline models in the short-term and long-term tourism demand forecasting tasks. Moreover, ablation studies demonstrate that the adoption of the calendar of days to be forecasted contributes to the forecasting performance of the proposed Tsformer. For better interpretability, the attention weight matrix visualization is performed. It indicates that the Tsformer concentrates on seasonal features and days close to days to be forecast in short-term forecasting.