 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMD-HookNet++: Evolution of AMD-HookNet with Hybrid CNN-Transformer Feature Enhancement for Glacier Calving Front Segmentation
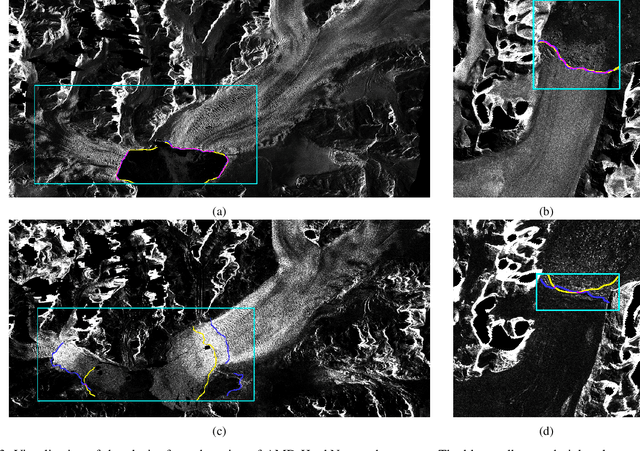
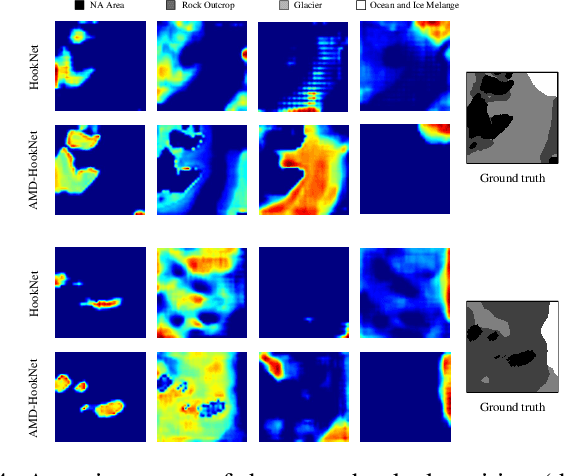
Dec 16, 2025The dynamics of glaciers and ice shelf fronts significantly impact the mass balance of ice sheets and coastal sea levels. To effectively monitor glacier conditions, it is crucial to consistently estimate positional shifts of glacier calving fronts. AMD-HookNet firstly introduces a pure two-branch convolutional neural network (CNN) for glacier segmentation. Yet, the local nature and translational invariance of convolution operations, while beneficial for capturing low-level details, restricts the model ability to maintain long-range dependencies. In this study, we propose AMD-HookNet++, a novel advanced hybrid CNN-Transformer feature enhancement method for segmenting glaciers and delineating calving fronts in synthetic aperture radar images. Our hybrid structure consists of two branches: a Transformer-based context branch to capture long-range dependencies, which provides global contextual information in a larger view, and a CNN-based target branch to preserve local details. To strengthen the representation of the connected hybrid features, we devise an enhanced spatial-channel attention module to foster interactions between the hybrid CNN-Transformer branches through dynamically adjusting the token relationships from both spatial and channel perspectives. Additionally, we develop a pixel-to-pixel contrastive deep supervision to optimize our hybrid model by integrating pixelwise metric learning into glacier segmentation. Through extensive experiments and comprehensive quantitative and qualitative analyses on the challenging glacier segmentation benchmark dataset CaFFe, we show that AMD-HookNet++ sets a new state of the art with an IoU of 78.2 and a HD95 of 1,318 m, while maintaining a competitive MDE of 367 m. More importantly, our hybrid model produces smoother delineations of calving fronts, resolving the issue of jagged edges typically seen in pure Transformer-based approaches.
STCMOT: Spatio-Temporal Cohesion Learning for UAV-Based Multiple Object Tracking
Sep 17, 2024



Multiple object tracking (MOT) in Unmanned Aerial Vehicle (UAV) videos is important for diverse applications in computer vision. Current MOT trackers rely on accurate object detection results and precise matching of target reidentification (ReID). These methods focus on optimizing target spatial attributes while overlooking temporal cues in modelling object relationships, especially for challenging tracking conditions such as object deformation and blurring, etc. To address the above-mentioned issues, we propose a novel Spatio-Temporal Cohesion Multiple Object Tracking framework (STCMOT), which utilizes historical embedding features to model the representation of ReID and detection features in a sequential order. Concretely, a temporal embedding boosting module is introduced to enhance the discriminability of individual embedding based on adjacent frame cooperation. While the trajectory embedding is then propagated by a temporal detection refinement module to mine salient target locations in the temporal field. Extensive experiments on the VisDrone2019 and UAVDT datasets demonstrate our STCMOT sets a new state-of-the-art performance in MOTA and IDF1 metrics. The source codes are released at https://github.com/ydhcg-BoBo/STCMOT.
Exploiting Image-Related Inductive Biases in Single-Branch Visual Tracking
Oct 30, 2023



Despite achieving state-of-the-art performance in visual tracking, recent single-branch trackers tend to overlook the weak prior assumptions associated with the Vision Transformer (ViT) encoder and inference pipeline. Moreover, the effectiveness of discriminative trackers remains constrained due to the adoption of the dual-branch pipeline. To tackle the inferior effectiveness of the vanilla ViT, we propose an Adaptive ViT Model Prediction tracker (AViTMP) to bridge the gap between single-branch network and discriminative models. Specifically, in the proposed encoder AViT-Enc, we introduce an adaptor module and joint target state embedding to enrich the dense embedding paradigm based on ViT. Then, we combine AViT-Enc with a dense-fusion decoder and a discriminative target model to predict accurate location. Further, to mitigate the limitations of conventional inference practice, we present a novel inference pipeline called CycleTrack, which bolsters the tracking robustness in the presence of distractors via bidirectional cycle tracking verification. Lastly, we propose a dual-frame update inference strategy that adeptively handles significant challenges in long-term scenarios. In the experiments, we evaluate AViTMP on ten tracking benchmarks for a comprehensive assessment, including LaSOT, LaSOTExtSub, AVisT, etc. The experimental results unequivocally establish that AViTMP attains state-of-the-art performance, especially on long-time tracking and robustness.
AMD-HookNet for Glacier Front Segmentation
Feb 06, 2023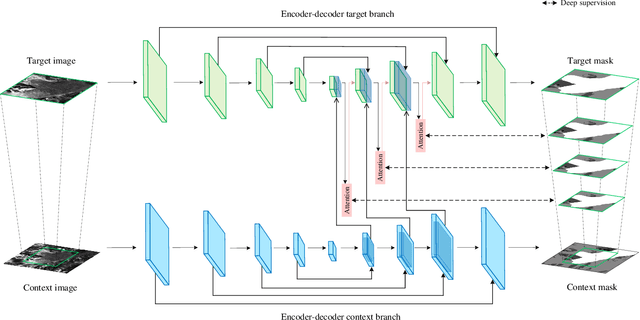

Knowledge on changes in glacier calving front positions is important for assessing the status of glaciers. Remote sensing imagery provides the ideal database for monitoring calving front positions, however, it is not feasible to perform this task manually for all calving glaciers globally due to time-constraints. Deep learning-based methods have shown great potential for glacier calving front delineation from optical and radar satellite imagery. The calving front is represented as a single thin line between the ocean and the glacier, which makes the task vulnerable to inaccurate predictions. The limited availability of annotated glacier imagery leads to a lack of data diversity (not all possible combinations of different weather conditions, terminus shapes, sensors, etc. are present in the data), which exacerbates the difficulty of accurate segmentation. In this paper, we propose Attention-Multi-hooking-Deep-supervision HookNet (AMD-HookNet), a novel glacier calving front segmentation framework for synthetic aperture radar (SAR) images. The proposed method aims to enhance the feature representation capability through multiple information interactions between low-resolution and high-resolution inputs based on a two-branch U-Net. The attention mechanism, integrated into the two branch U-Net, aims to interact between the corresponding coarse and fine-grained feature maps. This allows the network to automatically adjust feature relationships, resulting in accurate pixel-classification predictions. Extensive experiments and comparisons on the challenging glacier segmentation benchmark dataset CaFFe show that our AMD-HookNet achieves a mean distance error of 438 m to the ground truth outperforming the current state of the art by 42%, which validates its effectiveness.
Revisiting Color-Event based Tracking: A Unified Network, Dataset, and Metric
Nov 20, 2022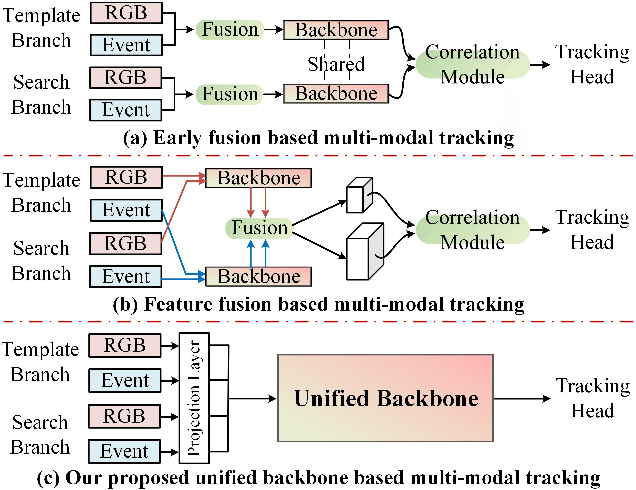

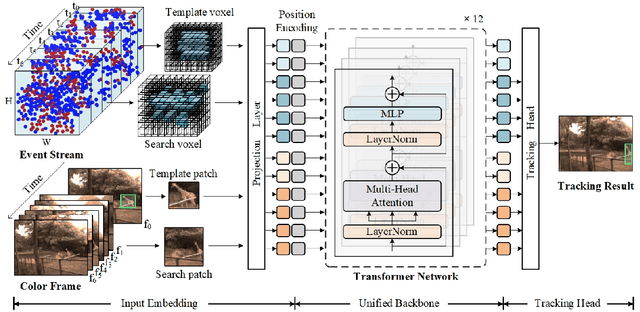

Combining the Color and Event cameras (also called Dynamic Vision Sensors, DVS) for robust object tracking is a newly emerging research topic in recent years. Existing color-event tracking framework usually contains multiple scattered modules which may lead to low efficiency and high computational complexity, including feature extraction, fusion, matching, interactive learning, etc. In this paper, we propose a single-stage backbone network for Color-Event Unified Tracking (CEUTrack), which achieves the above functions simultaneously. Given the event points and RGB frames, we first transform the points into voxels and crop the template and search regions for both modalities, respectively. Then, these regions are projected into tokens and parallelly fed into the unified Transformer backbone network. The output features will be fed into a tracking head for target object localization. Our proposed CEUTrack is simple, effective, and efficient, which achieves over 75 FPS and new SOTA performance. To better validate the effectiveness of our model and address the data deficiency of this task, we also propose a generic and large-scale benchmark dataset for color-event tracking, termed COESOT, which contains 90 categories and 1354 video sequences. Additionally, a new evaluation metric named BOC is proposed in our evaluation toolkit to evaluate the prominence with respect to the baseline methods. We hope the newly proposed method, dataset, and evaluation metric provide a better platform for color-event-based tracking. The dataset, toolkit, and source code will be released on: \url{https://github.com/Event-AHU/COESOT}.
Learning Spatial-Frequency Transformer for Visual Object Tracking
Aug 18, 2022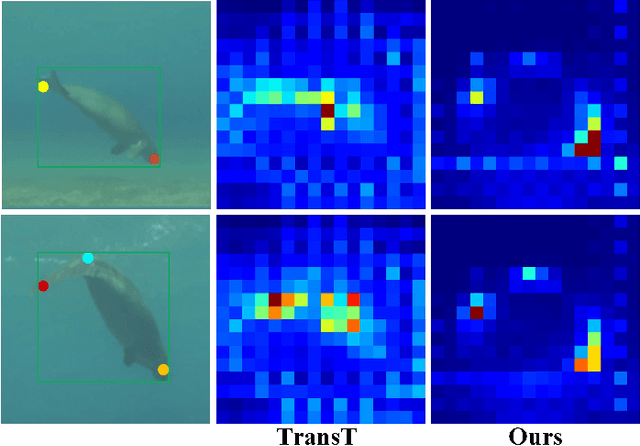
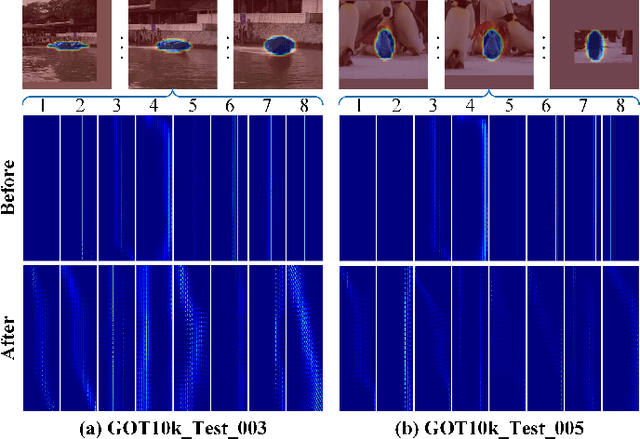

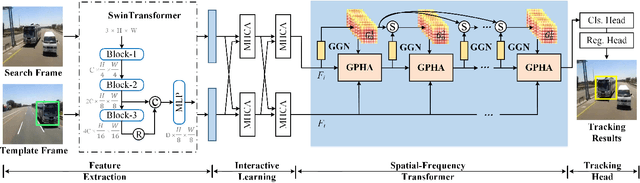
Recent trackers adopt the Transformer to combine or replace the widely used ResNet as their new backbone network. Although their trackers work well in regular scenarios, however, they simply flatten the 2D features into a sequence to better match the Transformer. We believe these operations ignore the spatial prior of the target object which may lead to sub-optimal results only. In addition, many works demonstrate that self-attention is actually a low-pass filter, which is independent of input features or key/queries. That is to say, it may suppress the high-frequency component of the input features and preserve or even amplify the low-frequency information. To handle these issues, in this paper, we propose a unified Spatial-Frequency Transformer that models the Gaussian spatial Prior and High-frequency emphasis Attention (GPHA) simultaneously. To be specific, Gaussian spatial prior is generated using dual Multi-Layer Perceptrons (MLPs) and injected into the similarity matrix produced by multiplying Query and Key features in self-attention. The output will be fed into a Softmax layer and then decomposed into two components, i.e., the direct signal and high-frequency signal. The low- and high-pass branches are rescaled and combined to achieve all-pass, therefore, the high-frequency features will be protected well in stacked self-attention layers. We further integrate the Spatial-Frequency Transformer into the Siamese tracking framework and propose a novel tracking algorithm, termed SFTransT. The cross-scale fusion based SwinTransformer is adopted as the backbone, and also a multi-head cross-attention module is used to boost the interaction between search and template features. The output will be fed into the tracking head for target localization. Extensive experiments on both short-term and long-term tracking benchmarks all demonstrate the effectiveness of our proposed framework.
SubGraph Networks based Entity Alignment for Cross-lingual Knowledge Graph
May 07, 2022

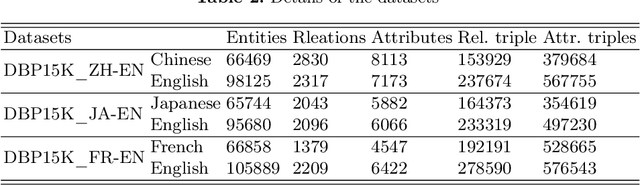

Entity alignment is the task of finding entities representing the same real-world object in two knowledge graphs(KGs). Cross-lingual knowledge graph entity alignment aims to discover the cross-lingual links in the multi-language KGs, which is of great significance to the NLP applications and multi-language KGs fusion. In the task of aligning cross-language knowledge graphs, the structures of the two graphs are very similar, and the equivalent entities often have the same subgraph structure characteristics. The traditional GCN method neglects to obtain structural features through representative parts of the original graph and the use of adjacency matrix is not enough to effectively represent the structural features of the graph. In this paper, we introduce the subgraph network (SGN) method into the GCN-based cross-lingual KG entity alignment method. In the method, we extracted the first-order subgraphs of the KGs to expand the structural features of the original graph to enhance the representation ability of the entity embedding and improve the alignment accuracy. Experiments show that the proposed method outperforms the state-of-the-art GCN-based method.
SPSTracker: Sub-Peak Suppression of Response Map for Robust Object Tracking
Jan 24, 2020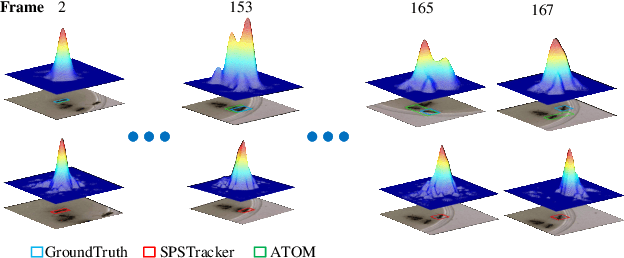

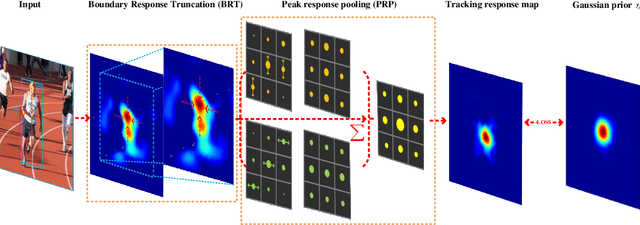

I'm sorry, Table2,3(VOT2016,2018) do not match figure6,7(VOT2016,2018).More experiments need to be added. However, this replacement version may take a lot of time, because a lot of experiments need to be done again, and now because of the Chinese Spring Festival and the 2019 novel coronavirus (2019-nCoV) can't do experiments, in order to ensure the rigor of the paper, I applied to withdraw the manuscript, and then resubmit it after the replacement version.