 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Light Pollution Removal in Night Cityscape Photographs
Apr 10, 2026Nighttime photography is severely degraded by light pollution induced by pervasive artificial lighting in urban environments. After long-range scattering and spatial diffusion, unwanted artificial light overwhelms natural night luminance, generates skyglow that washes out the view of stars and celestial objects and produces halos and glow artifacts around light sources. Unlike nighttime dehazing, which aims to improve detail legibility through thick air, the objective of light pollution removal is to restore the pristine night appearance by neutralizing the radiative footprint of ground lighting. In this paper we introduce a physically-based degradation model that adds to the previous ones for nighttime dehazing two critical aspects; (i) anisotropic spread of directional light sources, and (ii) skyglow caused by invisible surface lights behind skylines. In addition, we construct a training strategy that leverages large generative model and synthetic-real coupling to compensate for the scarcity of paired real data and enhance generalization. Extensive experiments demonstrate that the proposed formulation and learning framework substantially reduce light pollution artifacts and better recover authentic night imagery than prior nighttime restoration methods.
Class-invariant Test-Time Augmentation for Domain Generalization
Sep 17, 2025Deep models often suffer significant performance degradation under distribution shifts. Domain generalization (DG) seeks to mitigate this challenge by enabling models to generalize to unseen domains. Most prior approaches rely on multi-domain training or computationally intensive test-time adaptation. In contrast, we propose a complementary strategy: lightweight test-time augmentation. Specifically, we develop a novel Class-Invariant Test-Time Augmentation (CI-TTA) technique. The idea is to generate multiple variants of each input image through elastic and grid deformations that nevertheless belong to the same class as the original input. Their predictions are aggregated through a confidence-guided filtering scheme that remove unreliable outputs, ensuring the final decision relies on consistent and trustworthy cues. Extensive Experiments on PACS and Office-Home datasets demonstrate consistent gains across different DG algorithms and backbones, highlighting the effectiveness and generality of our approach.
3DGS Compression with Sparsity-guided Hierarchical Transform Coding
May 28, 20253D Gaussian Splatting (3DGS) has gained popularity for its fast and high-quality rendering, but it has a very large memory footprint incurring high transmission and storage overhead. Recently, some neural compression methods, such as Scaffold-GS, were proposed for 3DGS but they did not adopt the approach of end-to-end optimized analysis-synthesis transforms which has been proven highly effective in neural signal compression. Without an appropriate analysis transform, signal correlations cannot be removed by sparse representation. Without such transforms the only way to remove signal redundancies is through entropy coding driven by a complex and expensive context modeling, which results in slower speed and suboptimal rate-distortion (R-D) performance. To overcome this weakness, we propose Sparsity-guided Hierarchical Transform Coding (SHTC), the first end-to-end optimized transform coding framework for 3DGS compression. SHTC jointly optimizes the 3DGS, transforms and a lightweight context model. This joint optimization enables the transform to produce representations that approach the best R-D performance possible. The SHTC framework consists of a base layer using KLT for data decorrelation, and a sparsity-coded enhancement layer that compresses the KLT residuals to refine the representation. The enhancement encoder learns a linear transform to project high-dimensional inputs into a low-dimensional space, while the decoder unfolds the Iterative Shrinkage-Thresholding Algorithm (ISTA) to reconstruct the residuals. All components are designed to be interpretable, allowing the incorporation of signal priors and fewer parameters than black-box transforms. This novel design significantly improves R-D performance with minimal additional parameters and computational overhead.
Learning Optimal Lattice Vector Quantizers for End-to-end Neural Image Compression
Nov 25, 2024It is customary to deploy uniform scalar quantization in the end-to-end optimized Neural image compression methods, instead of more powerful vector quantization, due to the high complexity of the latter. Lattice vector quantization (LVQ), on the other hand, presents a compelling alternative, which can exploit inter-feature dependencies more effectively while keeping computational efficiency almost the same as scalar quantization. However, traditional LVQ structures are designed/optimized for uniform source distributions, hence nonadaptive and suboptimal for real source distributions of latent code space for Neural image compression tasks. In this paper, we propose a novel learning method to overcome this weakness by designing the rate-distortion optimal lattice vector quantization (OLVQ) codebooks with respect to the sample statistics of the latent features to be compressed. By being able to better fit the LVQ structures to any given latent sample distribution, the proposed OLVQ method improves the rate-distortion performances of the existing quantization schemes in neural image compression significantly, while retaining the amenability of uniform scalar quantization.
Fast Point Cloud Geometry Compression with Context-based Residual Coding and INR-based Refinement
Aug 06, 2024
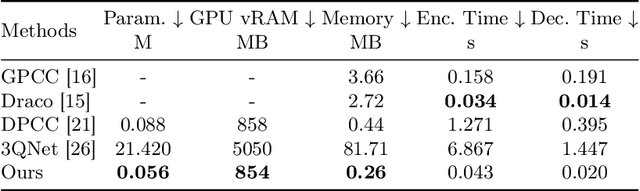


Compressing a set of unordered points is far more challenging than compressing images/videos of regular sample grids, because of the difficulties in characterizing neighboring relations in an irregular layout of points. Many researchers resort to voxelization to introduce regularity, but this approach suffers from quantization loss. In this research, we use the KNN method to determine the neighborhoods of raw surface points. This gives us a means to determine the spatial context in which the latent features of 3D points are compressed by arithmetic coding. As such, the conditional probability model is adaptive to local geometry, leading to significant rate reduction. Additionally, we propose a dual-layer architecture where a non-learning base layer reconstructs the main structures of the point cloud at low complexity, while a learned refinement layer focuses on preserving fine details. This design leads to reductions in model complexity and coding latency by two orders of magnitude compared to SOTA methods. Moreover, we incorporate an implicit neural representation (INR) into the refinement layer, allowing the decoder to sample points on the underlying surface at arbitrary densities. This work is the first to effectively exploit content-aware local contexts for compressing irregular raw point clouds, achieving high rate-distortion performance, low complexity, and the ability to function as an arbitrary-scale upsampling network simultaneously.
FLLIC: Functionally Lossless Image Compression
Jan 24, 2024Recently, DNN models for lossless image coding have surpassed their traditional counterparts in compression performance, reducing the bit rate by about ten percent for natural color images. But even with these advances, mathematically lossless image compression (MLLIC) ratios for natural images still fall short of the bandwidth and cost-effectiveness requirements of most practical imaging and vision systems at present and beyond. To break the bottleneck of MLLIC in compression performance, we question the necessity of MLLIC, as almost all digital sensors inherently introduce acquisition noises, making mathematically lossless compression counterproductive. Therefore, in contrast to MLLIC, we propose a new paradigm of joint denoising and compression called functionally lossless image compression (FLLIC), which performs lossless compression of optimally denoised images (the optimality may be task-specific). Although not literally lossless with respect to the noisy input, FLLIC aims to achieve the best possible reconstruction of the latent noise-free original image. Extensive experiments show that FLLIC achieves state-of-the-art performance in joint denoising and compression of noisy images and does so at a lower computational cost.
Learning Noise-Resistant Image Representation by Aligning Clean and Noisy Domains
Jul 03, 2023Recent supervised and unsupervised image representation learning algorithms have achieved quantum leaps. However, these techniques do not account for representation resilience against noise in their design paradigms. Consequently, these effective methods suffer failure when confronted with noise outside the training distribution, such as complicated real-world noise that is usually opaque to model training. To address this issue, dual domains are optimized to separately model a canonical space for noisy representations, namely the Noise-Robust (NR) domain, and a twinned canonical clean space, namely the Noise-Free (NF) domain, by maximizing the interaction information between the representations. Given the dual canonical domains, we design a target-guided implicit neural mapping function to accurately translate the NR representations to the NF domain, yielding noise-resistant representations by eliminating noise regencies. The proposed method is a scalable module that can be readily integrated into existing learning systems to improve their robustness against noise. Comprehensive trials of various tasks using both synthetic and real-world noisy data demonstrate that the proposed Target-Guided Dual-Domain Translation (TDDT) method is able to achieve remarkable performance and robustness in the face of complex noisy images.
Dual-layer Image Compression via Adaptive Downsampling and Spatially Varying Upconversion
Feb 13, 2023Ultra high resolution (UHR) images are almost always downsampled to fit small displays of mobile end devices and upsampled to its original resolution when exhibited on very high-resolution displays. This observation motivates us on jointly optimizing operation pairs of downsampling and upsampling that are spatially adaptive to image contents for maximal rate-distortion performance. In this paper, we propose an adaptive downsampled dual-layer (ADDL) image compression system. In the ADDL compression system, an image is reduced in resolution by learned content-adaptive downsampling kernels and compressed to form a coded base layer. For decompression the base layer is decoded and upconverted to the original resolution using a deep upsampling neural network, aided by the prior knowledge of the learned adaptive downsampling kernels. We restrict the downsampling kernels to the form of Gabor filters in order to reduce the complexity of filter optimization and also reduce the amount of side information needed by the decoder for adaptive upsampling. Extensive experiments demonstrate that the proposed ADDL compression approach of jointly optimized, spatially adaptive downsampling and upconversion outperforms the state of the art image compression methods.
Deep Lossy Plus Residual Coding for Lossless and Near-lossless Image Compression
Sep 11, 2022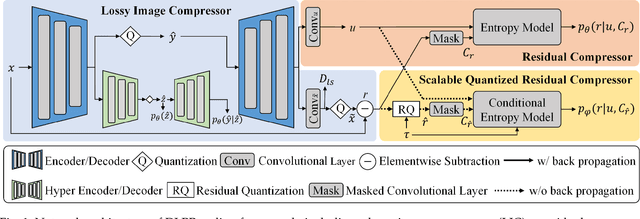

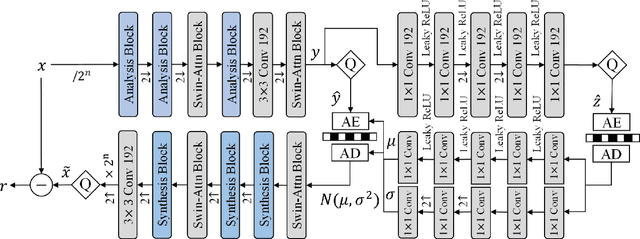
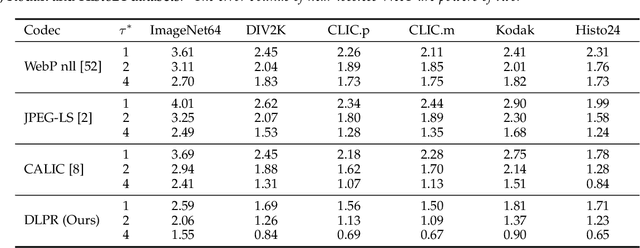
Lossless and near-lossless image compression is of paramount importance to professional users in many technical fields, such as medicine, remote sensing, precision engineering and scientific research. But despite rapidly growing research interests in learning-based image compression, no published method offers both lossless and near-lossless modes. In this paper, we propose a unified and powerful deep lossy plus residual (DLPR) coding framework for both lossless and near-lossless image compression. In the lossless mode, the DLPR coding system first performs lossy compression and then lossless coding of residuals. We solve the joint lossy and residual compression problem in the approach of VAEs, and add autoregressive context modeling of the residuals to enhance lossless compression performance. In the near-lossless mode, we quantize the original residuals to satisfy a given $\ell_\infty$ error bound, and propose a scalable near-lossless compression scheme that works for variable $\ell_\infty$ bounds instead of training multiple networks. To expedite the DLPR coding, we increase the degree of algorithm parallelization by a novel design of coding context, and accelerate the entropy coding with adaptive residual interval. Experimental results demonstrate that the DLPR coding system achieves both the state-of-the-art lossless and near-lossless image compression performance with competitive coding speed.
Semantic-Aware Latent Space Exploration for Face Image Restoration
Mar 06, 2022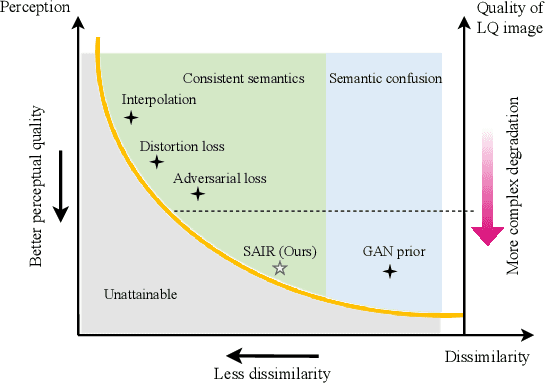
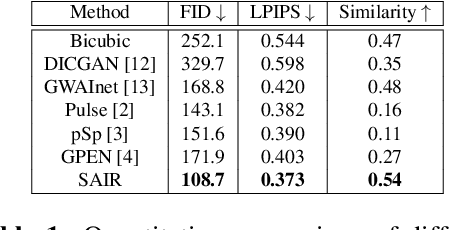
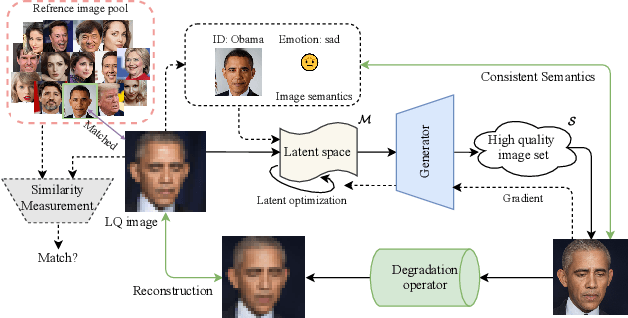
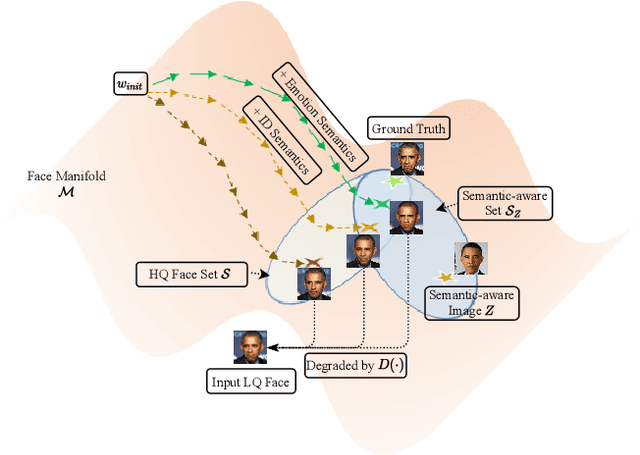
For image restoration, most existing deep learning based methods tend to overfit the training data leading to bad results when encountering unseen degradations out of the assumptions for training. To improve the robustness, generative adversarial network (GAN) prior based methods have been proposed, revealing a promising capability to restore photo-realistic and high-quality results. But these methods suffer from semantic confusion, especially on semantically significant images such as face images. In this paper, we propose a semantic-aware latent space exploration method for image restoration (SAIR). By explicitly modeling referenced semantics information, SAIR can consistently restore severely degraded images not only to high-resolution highly-realistic looks but also to correct semantics. Quantitative and qualitative experiments collectively demonstrate the effectiveness of the proposed SAIR. Our code can be found in https://github.com/Liamkuo/SAIR.