 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in Attention Sharing: Improving Complex Non-rigid Image Editing Faithfulness via Attention Synergy
Dec 17, 2025Training-free image editing with large diffusion models has become practical, yet faithfully performing complex non-rigid edits (e.g., pose or shape changes) remains highly challenging. We identify a key underlying cause: attention collapse in existing attention sharing mechanisms, where either positional embeddings or semantic features dominate visual content retrieval, leading to over-editing or under-editing. To address this issue, we introduce SynPS, a method that Synergistically leverages Positional embeddings and Semantic information for faithful non-rigid image editing. We first propose an editing measurement that quantifies the required editing magnitude at each denoising step. Based on this measurement, we design an attention synergy pipeline that dynamically modulates the influence of positional embeddings, enabling SynPS to balance semantic modifications and fidelity preservation. By adaptively integrating positional and semantic cues, SynPS effectively avoids both over- and under-editing. Extensive experiments on public and newly curated benchmarks demonstrate the superior performance and faithfulness of our approach.
The Devil is in the Spurious Correlation: Boosting Moment Retrieval via Temporal Dynamic Learning
Jan 13, 2025



Given a textual query along with a corresponding video, the objective of moment retrieval aims to localize the moments relevant to the query within the video. While commendable results have been demonstrated by existing transformer-based approaches, predicting the accurate temporal span of the target moment is currently still a major challenge. In this paper, we reveal that a crucial reason stems from the spurious correlation between the text queries and the moment context. Namely, the model may associate the textual query with the background frames rather than the target moment. To address this issue, we propose a temporal dynamic learning approach for moment retrieval, where two strategies are designed to mitigate the spurious correlation. First, we introduce a novel video synthesis approach to construct a dynamic context for the relevant moment. With separate yet similar videos mixed up, the synthesis approach empowers our model to attend to the target moment of the corresponding query under various dynamic contexts. Second, we enhance the representation by learning temporal dynamics. Besides the visual representation, text queries are aligned with temporal dynamic representations, which enables our model to establish a non-spurious correlation between the query-related moment and context. With the aforementioned proposed method, the spurious correlation issue in moment retrieval can be largely alleviated. Our method establishes a new state-of-the-art performance on two popular benchmarks of moment retrieval, \ie, QVHighlights and Charades-STA. In addition, the detailed ablation analyses demonstrate the effectiveness of the proposed strategies. Our code will be publicly available.
Powerful and Flexible: Personalized Text-to-Image Generation via Reinforcement Learning
Jul 09, 2024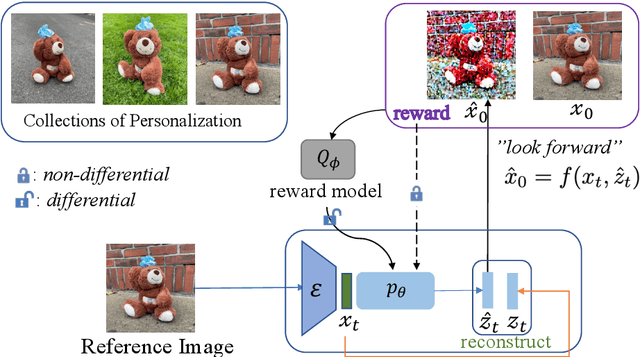
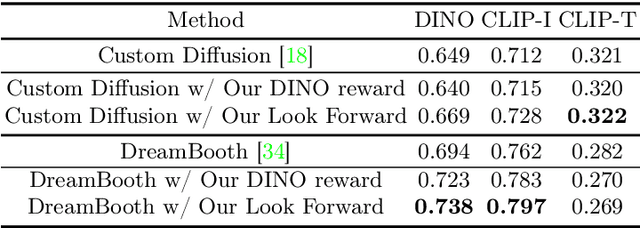

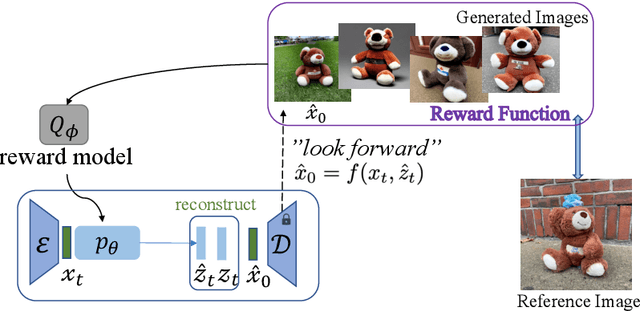
Personalized text-to-image models allow users to generate varied styles of images (specified with a sentence) for an object (specified with a set of reference images). While remarkable results have been achieved using diffusion-based generation models, the visual structure and details of the object are often unexpectedly changed during the diffusion process. One major reason is that these diffusion-based approaches typically adopt a simple reconstruction objective during training, which can hardly enforce appropriate structural consistency between the generated and the reference images. To this end, in this paper, we design a novel reinforcement learning framework by utilizing the deterministic policy gradient method for personalized text-to-image generation, with which various objectives, differential or even non-differential, can be easily incorporated to supervise the diffusion models to improve the quality of the generated images. Experimental results on personalized text-to-image generation benchmark datasets demonstrate that our proposed approach outperforms existing state-of-the-art methods by a large margin on visual fidelity while maintaining text-alignment. Our code is available at: \url{https://github.com/wfanyue/DPG-T2I-Personalization}.
Learning Pixel-Level Distinctions for Video Highlight Detection
Apr 10, 2022

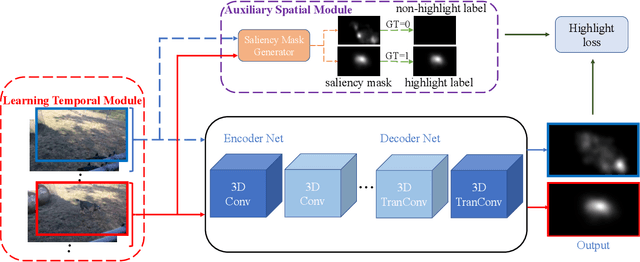
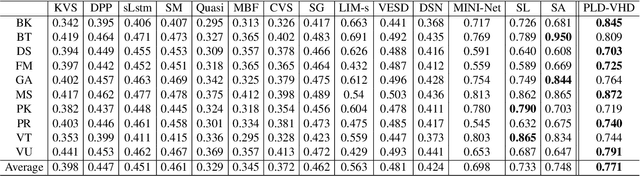
The goal of video highlight detection is to select the most attractive segments from a long video to depict the most interesting parts of the video. Existing methods typically focus on modeling relationship between different video segments in order to learning a model that can assign highlight scores to these segments; however, these approaches do not explicitly consider the contextual dependency within individual segments. To this end, we propose to learn pixel-level distinctions to improve the video highlight detection. This pixel-level distinction indicates whether or not each pixel in one video belongs to an interesting section. The advantages of modeling such fine-level distinctions are two-fold. First, it allows us to exploit the temporal and spatial relations of the content in one video, since the distinction of a pixel in one frame is highly dependent on both the content before this frame and the content around this pixel in this frame. Second, learning the pixel-level distinction also gives a good explanation to the video highlight task regarding what contents in a highlight segment will be attractive to people. We design an encoder-decoder network to estimate the pixel-level distinction, in which we leverage the 3D convolutional neural networks to exploit the temporal context information, and further take advantage of the visual saliency to model the spatial distinction. State-of-the-art performance on three public benchmarks clearly validates the effectiveness of our framework for video highlight detection.