 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pixel-Level Distinctions for Video Highlight Detection
Paper and Code
Apr 10, 2022

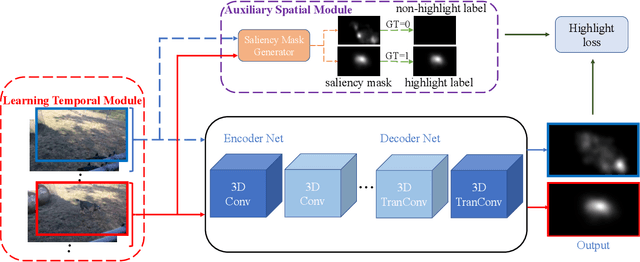
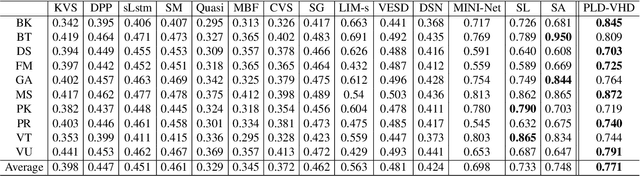
The goal of video highlight detection is to select the most attractive segments from a long video to depict the most interesting parts of the video. Existing methods typically focus on modeling relationship between different video segments in order to learning a model that can assign highlight scores to these segments; however, these approaches do not explicitly consider the contextual dependency within individual segments. To this end, we propose to learn pixel-level distinctions to improve the video highlight detection. This pixel-level distinction indicates whether or not each pixel in one video belongs to an interesting section. The advantages of modeling such fine-level distinctions are two-fold. First, it allows us to exploit the temporal and spatial relations of the content in one video, since the distinction of a pixel in one frame is highly dependent on both the content before this frame and the content around this pixel in this frame. Second, learning the pixel-level distinction also gives a good explanation to the video highlight task regarding what contents in a highlight segment will be attractive to people. We design an encoder-decoder network to estimate the pixel-level distinction, in which we leverage the 3D convolutional neural networks to exploit the temporal context information, and further take advantage of the visual saliency to model the spatial distinction. State-of-the-art performance on three public benchmarks clearly validates the effectiveness of our framework for video highlight detection.