 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransUNext: towards a more advanced U-shaped framework for automatic vessel segmentation in the fundus image
Nov 05, 2024
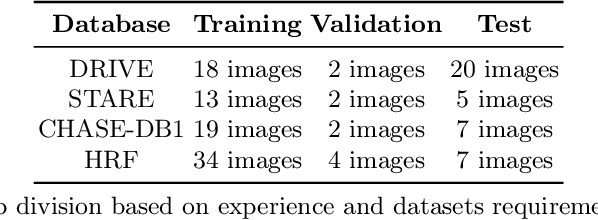

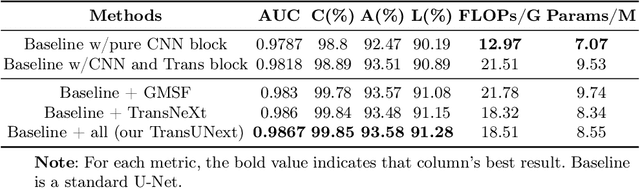
Purpose: Automatic and accurate segmentation of fundus vessel images has become an essential prerequisite for computer-aided diagnosis of ophthalmic diseases such as diabetes mellitus. The task of high-precision retinal vessel segmentation still faces difficulties due to the low contrast between the branch ends of retinal vessels and the background, the long and thin vessel span, and the variable morphology of the optic disc and optic cup in fundus vessel images. Methods: We propose a more advanced U-shaped architecture for a hybrid Transformer and CNN: TransUNext, which integrates an Efficient Self-attention Mechanism into the encoder and decoder of U-Net to capture both local features and global dependencies with minimal computational overhead. Meanwhile, the Global Multi-Scale Fusion (GMSF) module is further introduced to upgrade skip-connections, fuse high-level semantic and low-level detailed information, and eliminate high- and low-level semantic differences. Inspired by ConvNeXt, TransNeXt Block is designed to optimize the computational complexity of each base block in U-Net and avoid the information loss caused by the compressed dimension when the information is converted between the feature spaces of different dimensions. Results: We evaluated the proposed method on four public datasets DRIVE, STARE, CHASE-DB1, and HRF. In the experimental results, the AUC (area under the ROC curve) values were 0.9867, 0.9869, 0.9910, and 0.9887, which exceeded the other state-of-the-art.