 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep chroma compression of tone-mapped images
Sep 24, 2024



Acquisition of high dynamic range (HDR) images is thriving due to the increasing use of smart devices and the demand for high-quality output. Extensive research has focused on developing methods for reducing the luminance range in HDR images using conventional and deep learning-based tone mapping operators to enable accurate reproduction on conventional 8 and 10-bit digital displays. However, these methods often fail to account for pixels that may lie outside the target display's gamut, resulting in visible chromatic distortions or color clipping artifacts. Previous studies suggested that a gamut management step ensures that all pixels remain within the target gamut. However, such approaches are computationally expensive and cannot be deployed on devices with limited computational resources. We propose a generative adversarial network for fast and reliable chroma compression of HDR tone-mapped images. We design a loss function that considers the hue property of generated images to improve color accuracy, and train the model on an extensive image dataset. Quantitative experiments demonstrate that the proposed model outperforms state-of-the-art image generation and enhancement networks in color accuracy, while a subjective study suggests that the generated images are on par or superior to those produced by conventional chroma compression methods in terms of visual quality. Additionally, the model achieves real-time performance, showing promising results for deployment on devices with limited computational resources.
Hybrid-Segmentor: A Hybrid Approach to Automated Fine-Grained Crack Segmentation in Civil Infrastructure
Sep 04, 2024
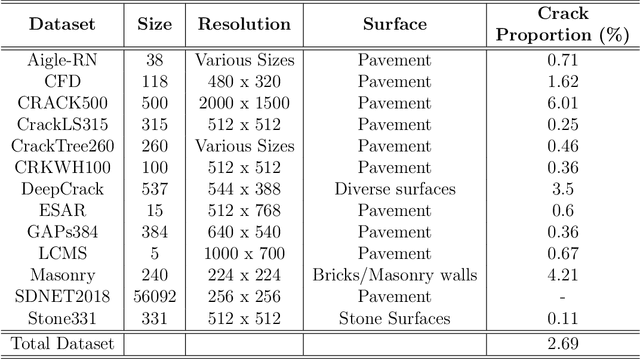

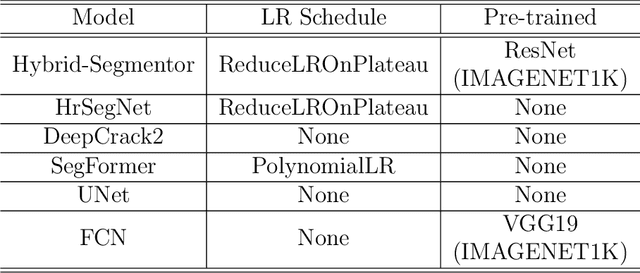
Detecting and segmenting cracks in infrastructure, such as roads and buildings, is crucial for safety and cost-effective maintenance. In spite of the potential of deep learning, there are challenges in achieving precise results and handling diverse crack types. With the proposed dataset and model, we aim to enhance crack detection and infrastructure maintenance. We introduce Hybrid-Segmentor, an encoder-decoder based approach that is capable of extracting both fine-grained local and global crack features. This allows the model to improve its generalization capabilities in distinguish various type of shapes, surfaces and sizes of cracks. To keep the computational performances low for practical purposes, while maintaining the high the generalization capabilities of the model, we incorporate a self-attention model at the encoder level, while reducing the complexity of the decoder component. The proposed model outperforms existing benchmark models across 5 quantitative metrics (accuracy 0.971, precision 0.804, recall 0.744, F1-score 0.770, and IoU score 0.630), achieving state-of-the-art status.
Quantifying Noise of Dynamic Vision Sensor
Apr 02, 2024



Dynamic visual sensors (DVS) are characterized by a large amount of background activity (BA) noise, which it is mixed with the original (cleaned) sensor signal. The dynamic nature of the signal and the absence in practical application of the ground truth, it clearly makes difficult to distinguish between noise and the cleaned sensor signals using standard image processing techniques. In this letter, a new technique is presented to characterise BA noise derived from the Detrended Fluctuation Analysis (DFA). The proposed technique can be used to address an existing DVS issues, which is how to quantitatively characterised noise and signal without ground truth, and how to derive an optimal denoising filter parameters. The solution of the latter problem is demonstrated for the popular real moving-car dataset.
Adversarially robust deepfake media detection using fused convolutional neural network predictions
Feb 11, 2021

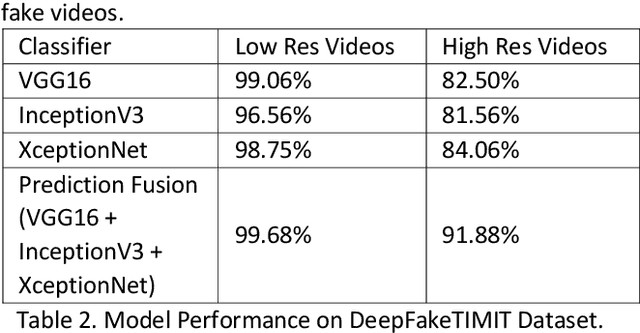
Deepfakes are synthetically generated images, videos or audios, which fraudsters use to manipulate legitimate information. Current deepfake detection systems struggle against unseen data. To address this, we employ three different deep Convolutional Neural Network (CNN) models, (1) VGG16, (2) InceptionV3, and (3) XceptionNet to classify fake and real images extracted from videos. We also constructed a fusion of the deep CNN models to improve the robustness and generalisation capability. The proposed technique outperforms state-of-the-art models with 96.5% accuracy, when tested on publicly available DeepFake Detection Challenge (DFDC) test data, comprising of 400 videos. The fusion model achieves 99% accuracy on lower quality DeepFake-TIMIT dataset videos and 91.88% on higher quality DeepFake-TIMIT videos. In addition to this, we prove that prediction fusion is more robust against adversarial attacks. If one model is compromised by an adversarial attack, the prediction fusion does not let it affect the overall classification.
High Dynamic Range Imaging Technology
Nov 30, 2017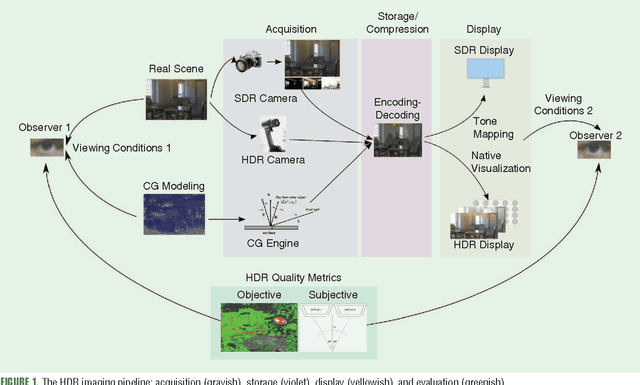

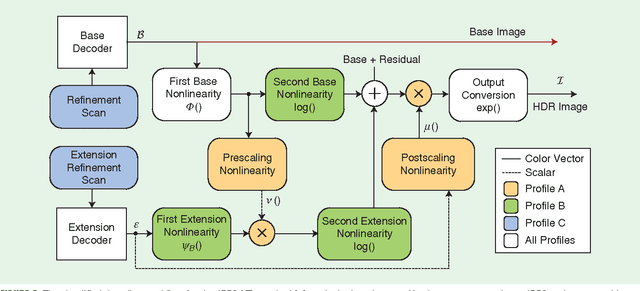
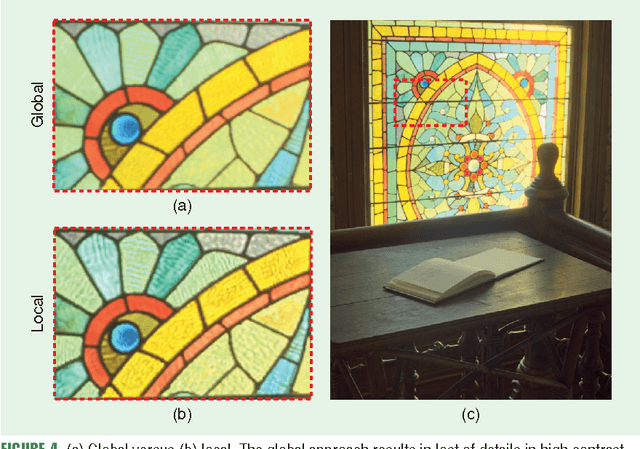
In this lecture note, we describe high dynamic range (HDR) imaging systems; such systems are able to represent luminances of much larger brightness and, typically, also a larger range of colors than conventional standard dynamic range (SDR) imaging systems. The larger luminance range greatly improve the overall quality of visual content, making it appears much more realistic and appealing to observers. HDR is one of the key technologies of the future imaging pipeline, which will change the way the digital visual content is represented and manipulated today.
* Lecture Notes