 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially robust deepfake media detection using fused convolutional neural network predictions
Paper and Code
Feb 11, 2021

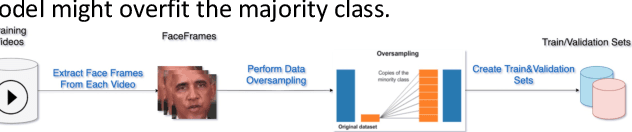
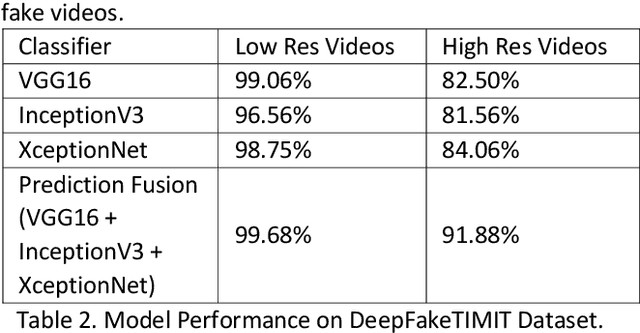
Deepfakes are synthetically generated images, videos or audios, which fraudsters use to manipulate legitimate information. Current deepfake detection systems struggle against unseen data. To address this, we employ three different deep Convolutional Neural Network (CNN) models, (1) VGG16, (2) InceptionV3, and (3) XceptionNet to classify fake and real images extracted from videos. We also constructed a fusion of the deep CNN models to improve the robustness and generalisation capability. The proposed technique outperforms state-of-the-art models with 96.5% accuracy, when tested on publicly available DeepFake Detection Challenge (DFDC) test data, comprising of 400 videos. The fusion model achieves 99% accuracy on lower quality DeepFake-TIMIT dataset videos and 91.88% on higher quality DeepFake-TIMIT videos. In addition to this, we prove that prediction fusion is more robust against adversarial attacks. If one model is compromised by an adversarial attack, the prediction fusion does not let it affect the overall classification.