 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction for Class-wise Coverage via Augmented Label Rank Calibration
Jun 10, 2024
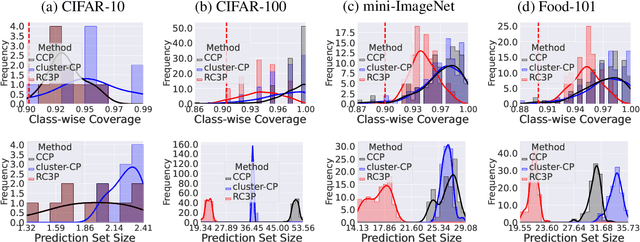


Conformal prediction (CP) is an emerging uncertainty quantification framework that allows us to construct a prediction set to cover the true label with a pre-specified marginal or conditional probability. Although the valid coverage guarantee has been extensively studied for classification problems, CP often produces large prediction sets which may not be practically useful. This issue is exacerbated for the setting of class-conditional coverage on imbalanced classification tasks. This paper proposes the Rank Calibrated Class-conditional CP (RC3P) algorithm to reduce the prediction set sizes to achieve class-conditional coverage, where the valid coverage holds for each class. In contrast to the standard class-conditional CP (CCP) method that uniformly thresholds the class-wise conformity score for each class, the augmented label rank calibration step allows RC3P to selectively iterate this class-wise thresholding subroutine only for a subset of classes whose class-wise top-k error is small. We prove that agnostic to the classifier and data distribution, RC3P achieves class-wise coverage. We also show that RC3P reduces the size of prediction sets compared to the CCP method. Comprehensive experiments on multiple real-world datasets demonstrate that RC3P achieves class-wise coverage and 26.25% reduction in prediction set sizes on average.
Probabilistically robust conformal prediction
Jul 31, 2023Conformal prediction (CP) is a framework to quantify uncertainty of machine learning classifiers including deep neural networks. Given a testing example and a trained classifier, CP produces a prediction set of candidate labels with a user-specified coverage (i.e., true class label is contained with high probability). Almost all the existing work on CP assumes clean testing data and there is not much known about the robustness of CP algorithms w.r.t natural/adversarial perturbations to testing examples. This paper studies the problem of probabilistically robust conformal prediction (PRCP) which ensures robustness to most perturbations around clean input examples. PRCP generalizes the standard CP (cannot handle perturbations) and adversarially robust CP (ensures robustness w.r.t worst-case perturbations) to achieve better trade-offs between nominal performance and robustness. We propose a novel adaptive PRCP (aPRCP) algorithm to achieve probabilistically robust coverage. The key idea behind aPRCP is to determine two parallel thresholds, one for data samples and another one for the perturbations on data (aka "quantile-of-quantile" design). We provide theoretical analysis to show that aPRCP algorithm achieves robust coverage. Our experiments on CIFAR-10, CIFAR-100, and ImageNet datasets using deep neural networks demonstrate that aPRCP achieves better trade-offs than state-of-the-art CP and adversarially robust CP algorithms.
* Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, 2023
Improving Uncertainty Quantification of Deep Classifiers via Neighborhood Conformal Prediction: Novel Algorithm and Theoretical Analysis
Mar 19, 2023Safe deployment of deep neural networks in high-stake real-world applications requires theoretically sound uncertainty quantification. Conformal prediction (CP) is a principled framework for uncertainty quantification of deep models in the form of prediction set for classification tasks with a user-specified coverage (i.e., true class label is contained with high probability). This paper proposes a novel algorithm referred to as Neighborhood Conformal Prediction (NCP) to improve the efficiency of uncertainty quantification from CP for deep classifiers (i.e., reduce prediction set size). The key idea behind NCP is to use the learned representation of the neural network to identify k nearest-neighbors calibration examples for a given testing input and assign them importance weights proportional to their distance to create adaptive prediction sets. We theoretically show that if the learned data representation of the neural network satisfies some mild conditions, NCP will produce smaller prediction sets than traditional CP algorithms. Our comprehensive experiments on CIFAR-10, CIFAR-100, and ImageNet datasets using diverse deep neural networks strongly demonstrate that NCP leads to significant reduction in prediction set size over prior CP methods.
Training Robust Deep Models for Time-Series Domain: Novel Algorithms and Theoretical Analysis
Jul 13, 2022
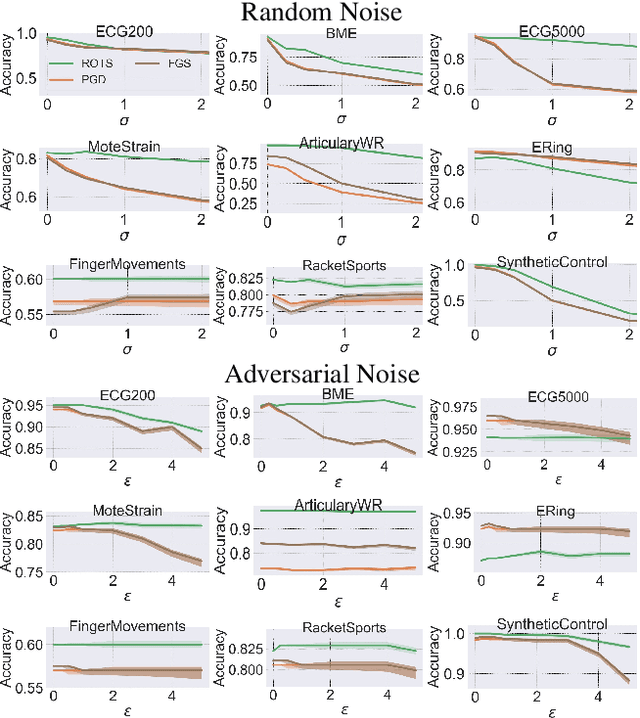

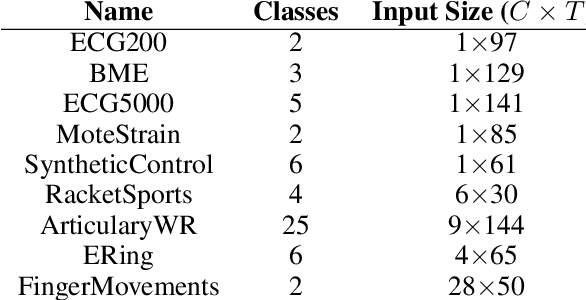
Despite the success of deep neural networks (DNNs) for real-world applications over time-series data such as mobile health, little is known about how to train robust DNNs for time-series domain due to its unique characteristics compared to images and text data. In this paper, we propose a novel algorithmic framework referred as RObust Training for Time-Series (RO-TS) to create robust DNNs for time-series classification tasks. Specifically, we formulate a min-max optimization problem over the model parameters by explicitly reasoning about the robustness criteria in terms of additive perturbations to time-series inputs measured by the global alignment kernel (GAK) based distance. We also show the generality and advantages of our formulation using the summation structure over time-series alignments by relating both GAK and dynamic time warping (DTW). This problem is an instance of a family of compositional min-max optimization problems, which are challenging and open with unclear theoretical guarantee. We propose a principled stochastic compositional alternating gradient descent ascent (SCAGDA) algorithm for this family of optimization problems. Unlike traditional methods for time-series that require approximate computation of distance measures, SCAGDA approximates the GAK based distance on-the-fly using a moving average approach. We theoretically analyze the convergence rate of SCAGDA and provide strong theoretical support for the estimation of GAK based distance. Our experiments on real-world benchmarks demonstrate that RO-TS creates more robust DNNs when compared to adversarial training using prior methods that rely on data augmentation or new definitions of loss functions. We also demonstrate the importance of GAK for time-series data over the Euclidean distance. The source code of RO-TS algorithms is available at https://github.com/tahabelkhouja/Robust-Training-for-Time-Series
* Published AAAI 2022
Dynamic Time Warping based Adversarial Framework for Time-Series Domain
Jul 09, 2022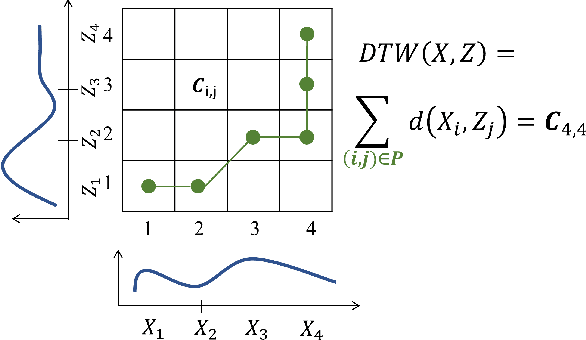



Despite the rapid progress on research in adversarial robustness of deep neural networks (DNNs), there is little principled work for the time-series domain. Since time-series data arises in diverse applications including mobile health, finance, and smart grid, it is important to verify and improve the robustness of DNNs for the time-series domain. In this paper, we propose a novel framework for the time-series domain referred as {\em Dynamic Time Warping for Adversarial Robustness (DTW-AR)} using the dynamic time warping measure. Theoretical and empirical evidence is provided to demonstrate the effectiveness of DTW over the standard Euclidean distance metric employed in prior methods for the image domain. We develop a principled algorithm justified by theoretical analysis to efficiently create diverse adversarial examples using random alignment paths. Experiments on diverse real-world benchmarks show the effectiveness of DTW-AR to fool DNNs for time-series data and to improve their robustness using adversarial training. The source code of DTW-AR algorithms is available at https://github.com/tahabelkhouja/DTW-AR
Adversarial Framework with Certified Robustness for Time-Series Domain via Statistical Features
Jul 09, 2022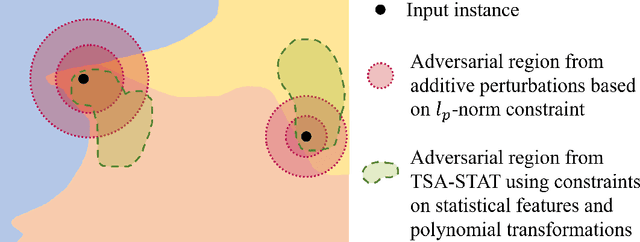

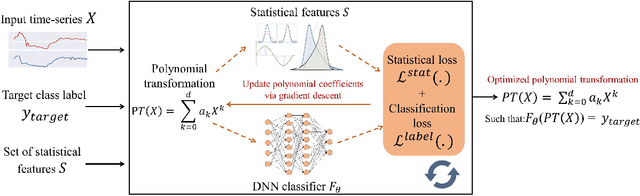
Time-series data arises in many real-world applications (e.g., mobile health) and deep neural networks (DNNs) have shown great success in solving them. Despite their success, little is known about their robustness to adversarial attacks. In this paper, we propose a novel adversarial framework referred to as Time-Series Attacks via STATistical Features (TSA-STAT)}. To address the unique challenges of time-series domain, TSA-STAT employs constraints on statistical features of the time-series data to construct adversarial examples. Optimized polynomial transformations are used to create attacks that are more effective (in terms of successfully fooling DNNs) than those based on additive perturbations. We also provide certified bounds on the norm of the statistical features for constructing adversarial examples. Our experiments on diverse real-world benchmark datasets show the effectiveness of TSA-STAT in fooling DNNs for time-series domain and in improving their robustness. The source code of TSA-STAT algorithms is available at https://github.com/tahabelkhouja/Time-Series-Attacks-via-STATistical-Features
* Published at Journal of Artificial Intelligence Research
Out-of-Distribution Detection in Time-Series Domain: A Novel Seasonal Ratio Scoring Approach
Jul 09, 2022


Safe deployment of time-series classifiers for real-world applications relies on the ability to detect the data which is not generated from the same distribution as training data. This task is referred to as out-of-distribution (OOD) detection. We consider the novel problem of OOD detection for the time-series domain. We discuss the unique challenges posed by time-series data and explain why prior methods from the image domain will perform poorly. Motivated by these challenges, this paper proposes a novel {\em Seasonal Ratio Scoring (SRS)} approach. SRS consists of three key algorithmic steps. First, each input is decomposed into class-wise semantic component and remainder. Second, this decomposition is employed to estimate the class-wise conditional likelihoods of the input and remainder using deep generative models. The seasonal ratio score is computed from these estimates. Third, a threshold interval is identified from the in-distribution data to detect OOD examples. Experiments on diverse real-world benchmarks demonstrate that the SRS method is well-suited for time-series OOD detection when compared to baseline methods. Open-source code for SRS method is provided at https://github.com/tahabelkhouja/SRS