 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Blockchain-empowered Multi-Aggregator Federated Learning Architecture in Edge Computing with Deep Reinforcement Learning Optimization
Oct 14, 2023



Federated learning (FL) is emerging as a sought-after distributed machine learning architecture, offering the advantage of model training without direct exposure of raw data. With advancements in network infrastructure, FL has been seamlessly integrated into edge computing. However, the limited resources on edge devices introduce security vulnerabilities to FL in the context. While blockchain technology promises to bolster security, practical deployment on resource-constrained edge devices remains a challenge. Moreover, the exploration of FL with multiple aggregators in edge computing is still new in the literature. Addressing these gaps, we introduce the Blockchain-empowered Heterogeneous Multi-Aggregator Federated Learning Architecture (BMA-FL). We design a novel light-weight Byzantine consensus mechanism, namely PBCM, to enable secure and fast model aggregation and synchronization in BMA-FL. We also dive into the heterogeneity problem in BMA-FL that the aggregators are associated with varied number of connected trainers with Non-IID data distributions and diverse training speed. We proposed a multi-agent deep reinforcement learning algorithm to help aggregators decide the best training strategies. The experiments on real-word datasets demonstrate the efficiency of BMA-FL to achieve better models faster than baselines, showing the efficacy of PBCM and proposed deep reinforcement learning algorithm.
Surveying the Landscape of Text Summarization with Deep Learning: A Comprehensive Review
Oct 13, 2023



In recent years, deep learning has revolutionized natural language processing (NLP) by enabling the development of models that can learn complex representations of language data, leading to significant improvements in performance across a wide range of NLP tasks. Deep learning models for NLP typically use large amounts of data to train deep neural networks, allowing them to learn the patterns and relationships in language data. This is in contrast to traditional NLP approaches, which rely on hand-engineered features and rules to perform NLP tasks. The ability of deep neural networks to learn hierarchical representations of language data, handle variable-length input sequences, and perform well on large datasets makes them well-suited for NLP applications. Driven by the exponential growth of textual data and the increasing demand for condensed, coherent, and informative summaries, text summarization has been a critical research area in the field of NLP. Applying deep learning to text summarization refers to the use of deep neural networks to perform text summarization tasks. In this survey, we begin with a review of fashionable text summarization tasks in recent years, including extractive, abstractive, multi-document, and so on. Next, we discuss most deep learning-based models and their experimental results on these tasks. The paper also covers datasets and data representation for summarization tasks. Finally, we delve into the opportunities and challenges associated with summarization tasks and their corresponding methodologies, aiming to inspire future research efforts to advance the field further. A goal of our survey is to explain how these methods differ in their requirements as understanding them is essential for choosing a technique suited for a specific setting.
A Survey on Influence Maximization: From an ML-Based Combinatorial Optimization
Nov 06, 2022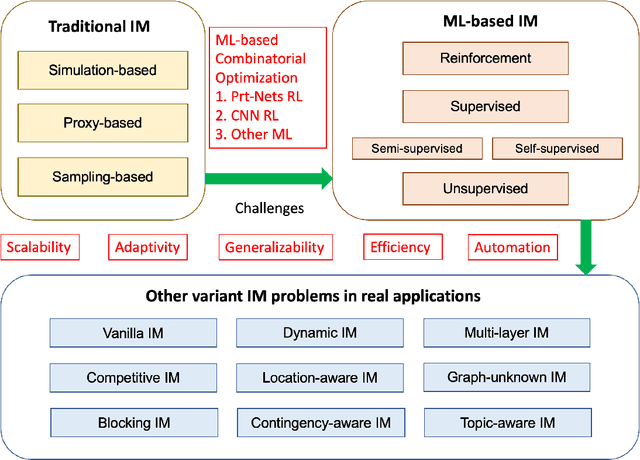
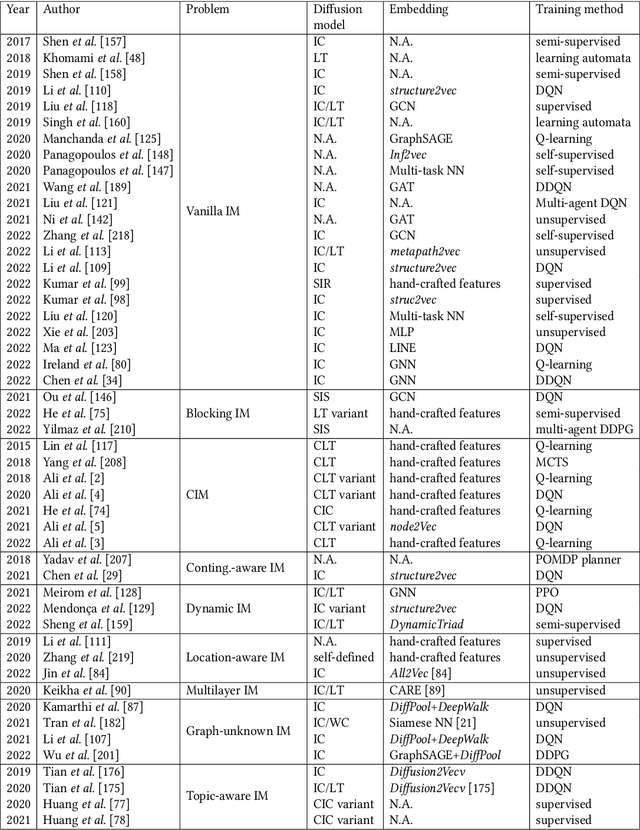
Influence Maximization (IM) is a classical combinatorial optimization problem, which can be widely used in mobile networks, social computing, and recommendation systems. It aims at selecting a small number of users such that maximizing the influence spread across the online social network. Because of its potential commercial and academic value, there are a lot of researchers focusing on studying the IM problem from different perspectives. The main challenge comes from the NP-hardness of the IM problem and \#P-hardness of estimating the influence spread, thus traditional algorithms for overcoming them can be categorized into two classes: heuristic algorithms and approximation algorithms. However, there is no theoretical guarantee for heuristic algorithms, and the theoretical design is close to the limit. Therefore, it is almost impossible to further optimize and improve their performance. With the rapid development of artificial intelligence, the technology based on Machine Learning (ML) has achieved remarkable achievements in many fields. In view of this, in recent years, a number of new methods have emerged to solve combinatorial optimization problems by using ML-based techniques. These methods have the advantages of fast solving speed and strong generalization ability to unknown graphs, which provide a brand-new direction for solving combinatorial optimization problems. Therefore, we abandon the traditional algorithms based on iterative search and review the recent development of ML-based methods, especially Deep Reinforcement Learning, to solve the IM problem and other variants in social networks. We focus on summarizing the relevant background knowledge, basic principles, common methods, and applied research. Finally, the challenges that need to be solved urgently in future IM research are pointed out.
ToupleGDD: A Fine-Designed Solution of Influence Maximization by Deep Reinforcement Learning
Oct 18, 2022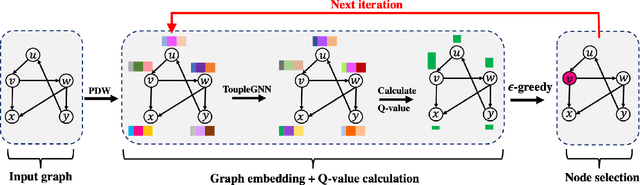

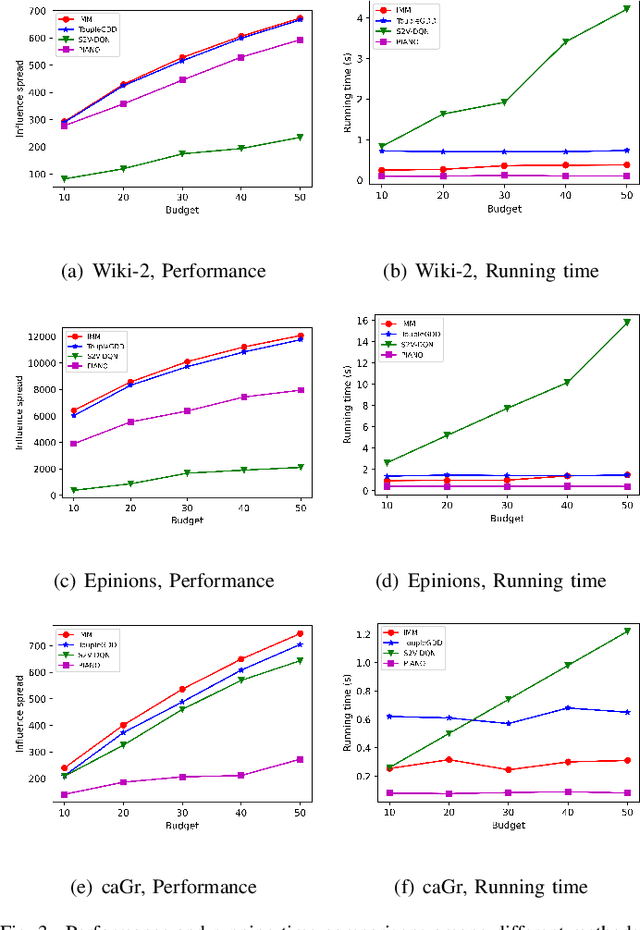

Online social platforms have become more and more popular, and the dissemination of information on social networks has attracted wide attention of the industries and academia. Aiming at selecting a small subset of nodes with maximum influence on networks, the Influence Maximization (IM) problem has been extensively studied. Since it is #P-hard to compute the influence spread given a seed set, the state-of-art methods, including heuristic and approximation algorithms, faced with great difficulties such as theoretical guarantee, time efficiency, generalization, etc. This makes it unable to adapt to large-scale networks and more complex applications. With the latest achievements of Deep Reinforcement Learning (DRL) in artificial intelligence and other fields, a lot of works has focused on exploiting DRL to solve the combinatorial optimization problems. Inspired by this, we propose a novel end-to-end DRL framework, ToupleGDD, to address the IM problem in this paper, which incorporates three coupled graph neural networks for network embedding and double deep Q-networks for parameters learning. Previous efforts to solve the IM problem with DRL trained their models on the subgraph of the whole network, and then tested their performance on the whole graph, which makes the performance of their models unstable among different networks. However, our model is trained on several small randomly generated graphs and tested on completely different networks, and can obtain results that are very close to the state-of-the-art methods. In addition, our model is trained with a small budget, and it can perform well under various large budgets in the test, showing strong generalization ability. Finally, we conduct entensive experiments on synthetic and realistic datasets, and the experimental results prove the effectiveness and superiority of our model.
Graph Representation Learning for Popularity Prediction Problem: A Survey
Mar 15, 2022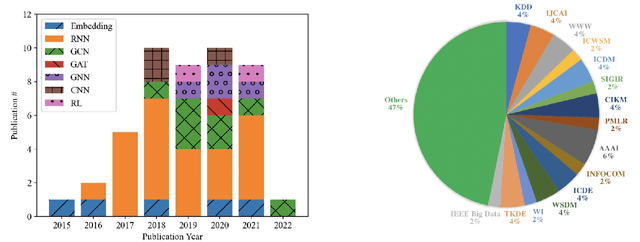
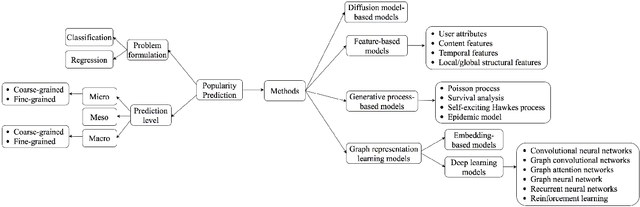
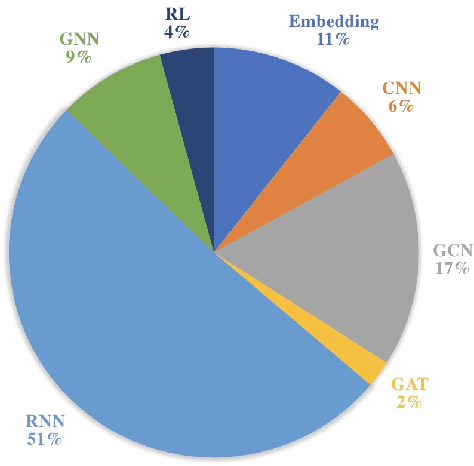
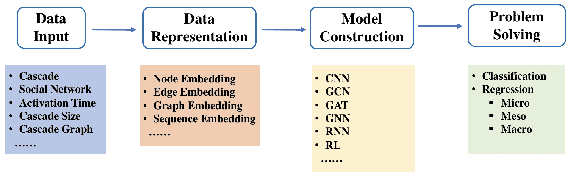
The online social platforms, like Twitter, Facebook, LinkedIn and WeChat, have grown really fast in last decade and have been one of the most effective platforms for people to communicate and share information with each other. Due to the "word of mouth" effects, information usually can spread rapidly on these social media platforms. Therefore, it is important to study the mechanisms driving the information diffusion and quantify the consequence of information spread. A lot of efforts have been focused on this problem to help us better understand and achieve higher performance in viral marketing and advertising. On the other hand, the development of neural networks has blossomed in the last few years, leading to a large number of graph representation learning (GRL) models. Compared to traditional models, GRL methods are often shown to be more effective. In this paper, we present a comprehensive review for existing works using GRL methods for popularity prediction problem, and categorize related literatures into two big classes, according to their mainly used model and techniques: embedding-based methods and deep learning methods. Deep learning method is further classified into six small classes: convolutional neural networks, graph convolutional networks, graph attention networks, graph neural networks, recurrent neural networks, and reinforcement learning. We compare the performance of these different models and discuss their strengths and limitations. Finally, we outline the challenges and future chances for popularity prediction problem.
Schemes of Propagation Models and Source Estimators for Rumor Source Detection in Online Social Networks: A Short Survey of a Decade of Research
Jan 04, 2021
Recent years have seen various rumor diffusion models being assumed in detection of rumor source research of the online social network. Diffusion model is arguably considered as a very important and challengeable factor for source detection in networks but it is less studied. This paper provides an overview of three representative schemes of Independent Cascade-based, Epidemic-based, and Learning-based to model the patterns of rumor propagation as well as three major schemes of estimators for rumor sources since its inception a decade ago.
A Blockchain Transaction Graph based Machine Learning Method for Bitcoin Price Prediction
Aug 21, 2020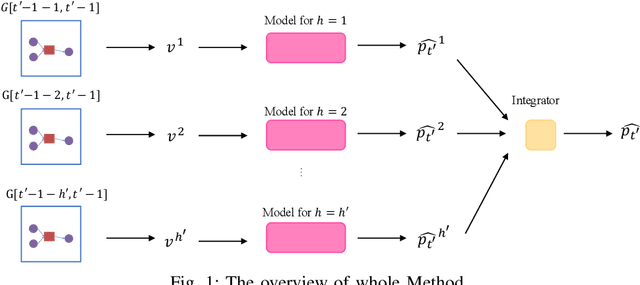
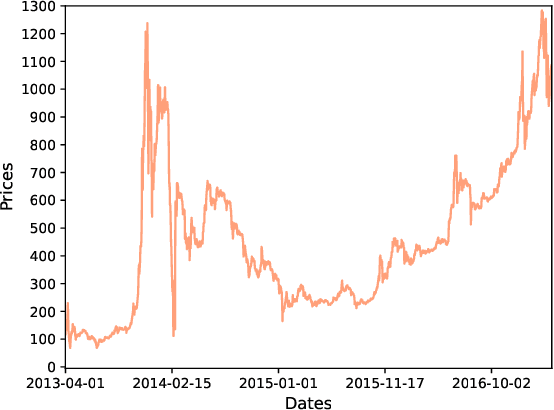

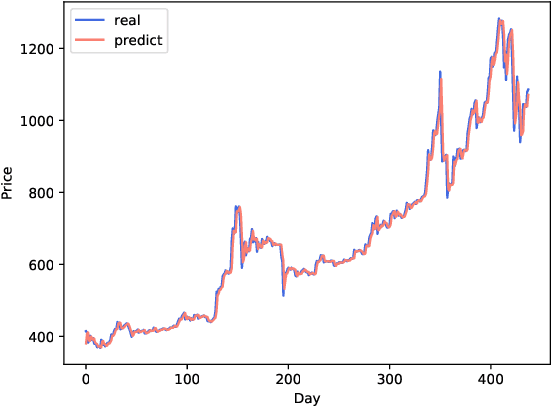
Bitcoin, as one of the most popular cryptocurrency, is recently attracting much attention of investors. Bitcoin price prediction task is consequently a rising academic topic for providing valuable insights and suggestions. Existing bitcoin prediction works mostly base on trivial feature engineering, that manually designs features or factors from multiple areas, including Bticoin Blockchain information, finance and social media sentiments. The feature engineering not only requires much human effort, but the effectiveness of the intuitively designed features can not be guaranteed. In this paper, we aim to mining the abundant patterns encoded in bitcoin transactions, and propose k-order transaction graph to reveal patterns under different scope. We propose the transaction graph based feature to automatically encode the patterns. A novel prediction method is proposed to accept the features and make price prediction, which can take advantage from particular patterns from different history period. The results of comparison experiments demonstrate that the proposed method outperforms the most recent state-of-art methods.
Continuous Profit Maximization: A Study of Unconstrained Dr-submodular Maximization
Apr 12, 2020



Profit maximization (PM) is to select a subset of users as seeds for viral marketing in online social networks, which balances between the cost and the profit from influence spread. We extend PM to that under the general marketing strategy, and form continuous profit maximization (CPM-MS) problem, whose domain is on integer lattices. The objective function of our CPM-MS is dr-submodular, but non-monotone. It is a typical case of unconstrained dr-submodular maximization (UDSM) problem, and take it as a starting point, we study UDSM systematically in this paper, which is very different from those existing researcher. First, we introduce the lattice-based double greedy algorithm, which can obtain a constant approximation guarantee. However, there is a strict and unrealistic condition that requiring the objective value is non-negative on the whole domain, or else no theoretical bounds. Thus, we propose a technique, called lattice-based iterative pruning. It can shrink the search space effectively, thereby greatly increasing the possibility of satisfying the non-negative objective function on this smaller domain without losing approximation ratio. Then, to overcome the difficulty to estimate the objective value of CPM-MS, we adopt reverse sampling strategies, and combine it with lattice-based double greedy, including pruning, without losing its performance but reducing its running time. The entire process can be considered as a general framework to solve the UDSM problem, especially for applying to social networks. Finally, we conduct experiments on several real datasets to evaluate the effectiveness and efficiency of our proposed algorithms.