 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute Coordinates Make Motion Generation Easy
May 26, 2025State-of-the-art text-to-motion generation models rely on the kinematic-aware, local-relative motion representation popularized by HumanML3D, which encodes motion relative to the pelvis and to the previous frame with built-in redundancy. While this design simplifies training for earlier generation models, it introduces critical limitations for diffusion models and hinders applicability to downstream tasks. In this work, we revisit the motion representation and propose a radically simplified and long-abandoned alternative for text-to-motion generation: absolute joint coordinates in global space. Through systematic analysis of design choices, we show that this formulation achieves significantly higher motion fidelity, improved text alignment, and strong scalability, even with a simple Transformer backbone and no auxiliary kinematic-aware losses. Moreover, our formulation naturally supports downstream tasks such as text-driven motion control and temporal/spatial editing without additional task-specific reengineering and costly classifier guidance generation from control signals. Finally, we demonstrate promising generalization to directly generate SMPL-H mesh vertices in motion from text, laying a strong foundation for future research and motion-related applications.
Rethinking Diffusion for Text-Driven Human Motion Generation
Nov 25, 2024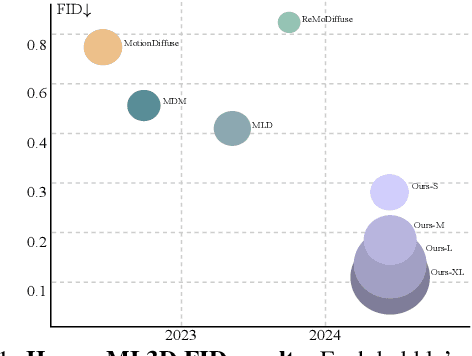
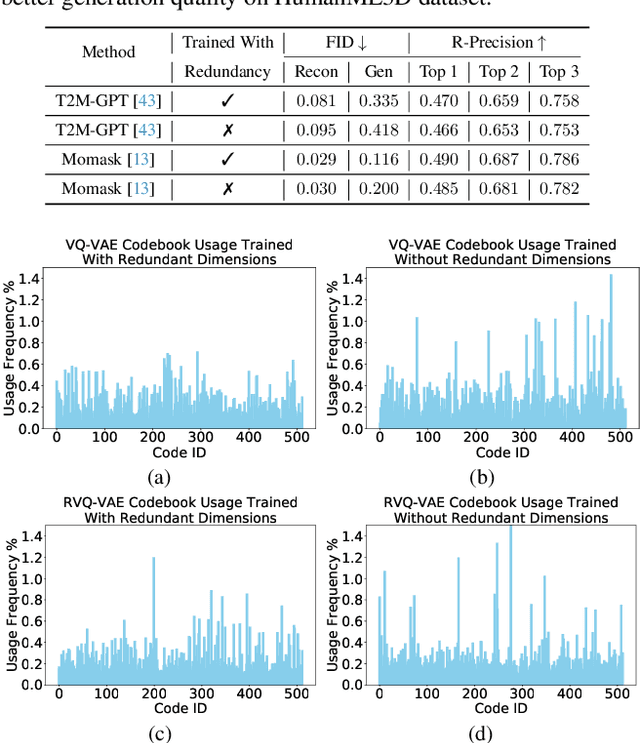
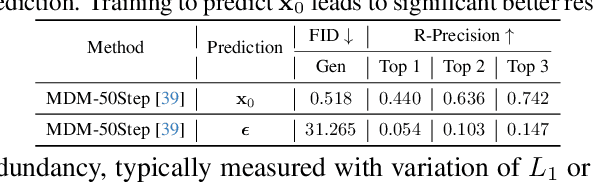
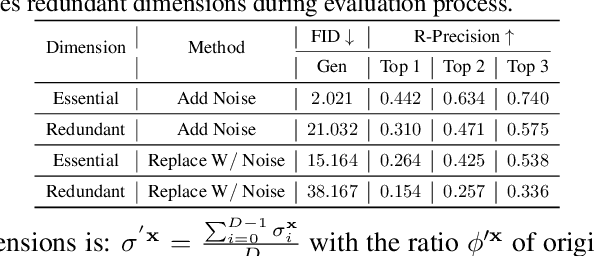
Since 2023, Vector Quantization (VQ)-based discrete generation methods have rapidly dominated human motion generation, primarily surpassing diffusion-based continuous generation methods in standard performance metrics. However, VQ-based methods have inherent limitations. Representing continuous motion data as limited discrete tokens leads to inevitable information loss, reduces the diversity of generated motions, and restricts their ability to function effectively as motion priors or generation guidance. In contrast, the continuous space generation nature of diffusion-based methods makes them well-suited to address these limitations and with even potential for model scalability. In this work, we systematically investigate why current VQ-based methods perform well and explore the limitations of existing diffusion-based methods from the perspective of motion data representation and distribution. Drawing on these insights, we preserve the inherent strengths of a diffusion-based human motion generation model and gradually optimize it with inspiration from VQ-based approaches. Our approach introduces a human motion diffusion model enabled to perform bidirectional masked autoregression, optimized with a reformed data representation and distribution. Additionally, we also propose more robust evaluation methods to fairly assess different-based methods. Extensive experiments on benchmark human motion generation datasets demonstrate that our method excels previous methods and achieves state-of-the-art performances.
Fast and Memory-Efficient Video Diffusion Using Streamlined Inference
Nov 02, 2024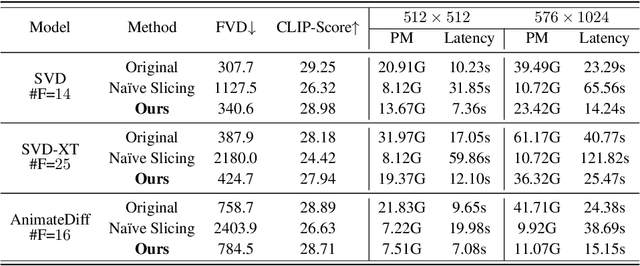
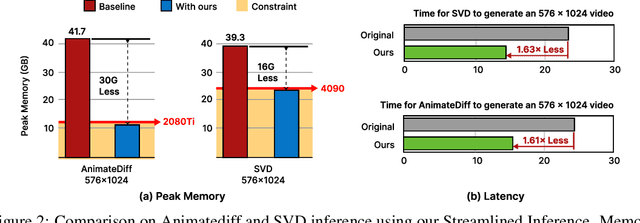

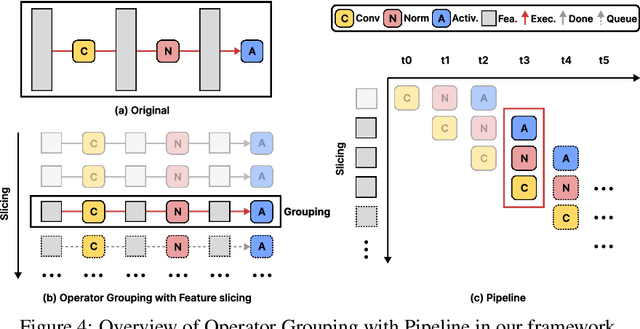
The rapid progress in artificial intelligence-generated content (AIGC), especially with diffusion models, has significantly advanced development of high-quality video generation. However, current video diffusion models exhibit demanding computational requirements and high peak memory usage, especially for generating longer and higher-resolution videos. These limitations greatly hinder the practical application of video diffusion models on standard hardware platforms. To tackle this issue, we present a novel, training-free framework named Streamlined Inference, which leverages the temporal and spatial properties of video diffusion models. Our approach integrates three core components: Feature Slicer, Operator Grouping, and Step Rehash. Specifically, Feature Slicer effectively partitions input features into sub-features and Operator Grouping processes each sub-feature with a group of consecutive operators, resulting in significant memory reduction without sacrificing the quality or speed. Step Rehash further exploits the similarity between adjacent steps in diffusion, and accelerates inference through skipping unnecessary steps. Extensive experiments demonstrate that our approach significantly reduces peak memory and computational overhead, making it feasible to generate high-quality videos on a single consumer GPU (e.g., reducing peak memory of AnimateDiff from 42GB to 11GB, featuring faster inference on 2080Ti).
Exploring Token Pruning in Vision State Space Models
Sep 27, 2024



State Space Models (SSMs) have the advantage of keeping linear computational complexity compared to attention modules in transformers, and have been applied to vision tasks as a new type of powerful vision foundation model. Inspired by the observations that the final prediction in vision transformers (ViTs) is only based on a subset of most informative tokens, we take the novel step of enhancing the efficiency of SSM-based vision models through token-based pruning. However, direct applications of existing token pruning techniques designed for ViTs fail to deliver good performance, even with extensive fine-tuning. To address this issue, we revisit the unique computational characteristics of SSMs and discover that naive application disrupts the sequential token positions. This insight motivates us to design a novel and general token pruning method specifically for SSM-based vision models. We first introduce a pruning-aware hidden state alignment method to stabilize the neighborhood of remaining tokens for performance enhancement. Besides, based on our detailed analysis, we propose a token importance evaluation method adapted for SSM models, to guide the token pruning. With efficient implementation and practical acceleration methods, our method brings actual speedup. Extensive experiments demonstrate that our approach can achieve significant computation reduction with minimal impact on performance across different tasks. Notably, we achieve 81.7\% accuracy on ImageNet with a 41.6\% reduction in the FLOPs for pruned PlainMamba-L3. Furthermore, our work provides deeper insights into understanding the behavior of SSM-based vision models for future research.
InstructGIE: Towards Generalizable Image Editing
Mar 08, 2024
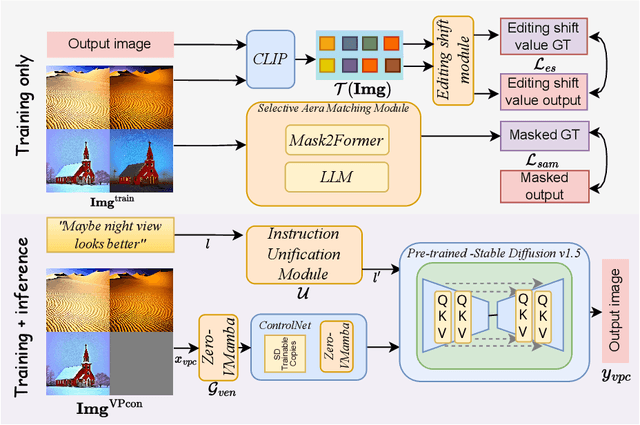


Recent advances in image editing have been driven by the development of denoising diffusion models, marking a significant leap forward in this field. Despite these advances, the generalization capabilities of recent image editing approaches remain constrained. In response to this challenge, our study introduces a novel image editing framework with enhanced generalization robustness by boosting in-context learning capability and unifying language instruction. This framework incorporates a module specifically optimized for image editing tasks, leveraging the VMamba Block and an editing-shift matching strategy to augment in-context learning. Furthermore, we unveil a selective area-matching technique specifically engineered to address and rectify corrupted details in generated images, such as human facial features, to further improve the quality. Another key innovation of our approach is the integration of a language unification technique, which aligns language embeddings with editing semantics to elevate the quality of image editing. Moreover, we compile the first dataset for image editing with visual prompts and editing instructions that could be used to enhance in-context capability. Trained on this dataset, our methodology not only achieves superior synthesis quality for trained tasks, but also demonstrates robust generalization capability across unseen vision tasks through tailored prompts.
DiffClass: Diffusion-Based Class Incremental Learning
Mar 08, 2024



Class Incremental Learning (CIL) is challenging due to catastrophic forgetting. On top of that, Exemplar-free Class Incremental Learning is even more challenging due to forbidden access to previous task data. Recent exemplar-free CIL methods attempt to mitigate catastrophic forgetting by synthesizing previous task data. However, they fail to overcome the catastrophic forgetting due to the inability to deal with the significant domain gap between real and synthetic data. To overcome these issues, we propose a novel exemplar-free CIL method. Our method adopts multi-distribution matching (MDM) diffusion models to unify quality and bridge domain gaps among all domains of training data. Moreover, our approach integrates selective synthetic image augmentation (SSIA) to expand the distribution of the training data, thereby improving the model's plasticity and reinforcing the performance of our method's ultimate component, multi-domain adaptation (MDA). With the proposed integrations, our method then reformulates exemplar-free CIL into a multi-domain adaptation problem to implicitly address the domain gap problem to enhance model stability during incremental training. Extensive experiments on benchmark class incremental datasets and settings demonstrate that our method excels previous exemplar-free CIL methods and achieves state-of-the-art performance.