 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute Coordinates Make Motion Generation Easy
May 26, 2025State-of-the-art text-to-motion generation models rely on the kinematic-aware, local-relative motion representation popularized by HumanML3D, which encodes motion relative to the pelvis and to the previous frame with built-in redundancy. While this design simplifies training for earlier generation models, it introduces critical limitations for diffusion models and hinders applicability to downstream tasks. In this work, we revisit the motion representation and propose a radically simplified and long-abandoned alternative for text-to-motion generation: absolute joint coordinates in global space. Through systematic analysis of design choices, we show that this formulation achieves significantly higher motion fidelity, improved text alignment, and strong scalability, even with a simple Transformer backbone and no auxiliary kinematic-aware losses. Moreover, our formulation naturally supports downstream tasks such as text-driven motion control and temporal/spatial editing without additional task-specific reengineering and costly classifier guidance generation from control signals. Finally, we demonstrate promising generalization to directly generate SMPL-H mesh vertices in motion from text, laying a strong foundation for future research and motion-related applications.
Rethinking Diffusion for Text-Driven Human Motion Generation
Nov 25, 2024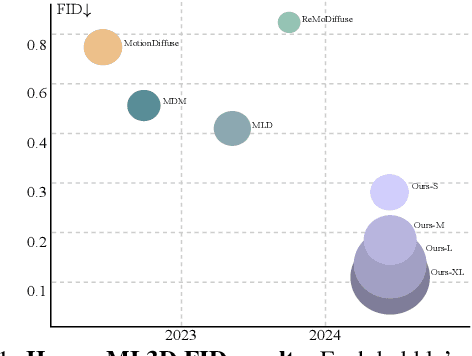
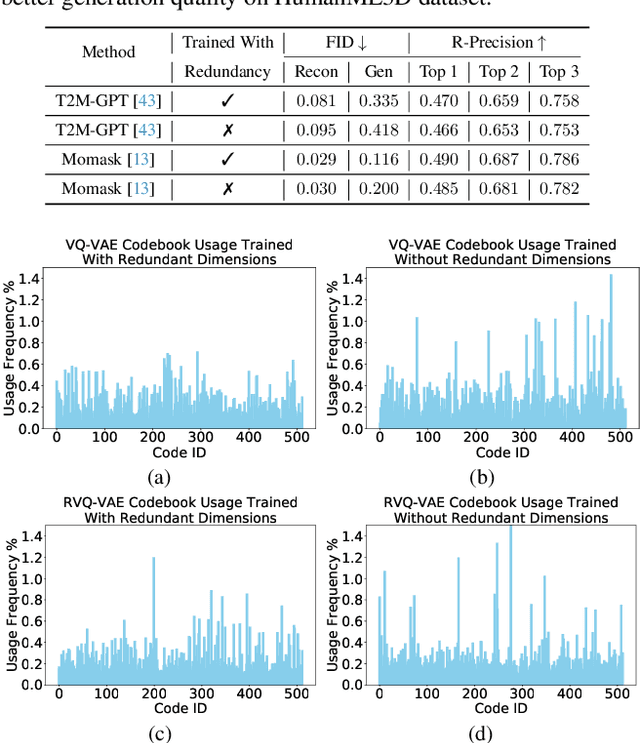
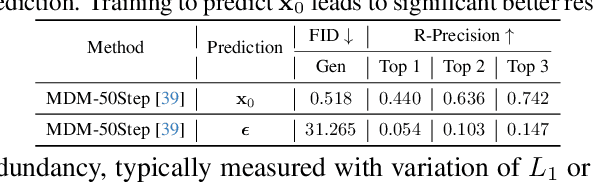
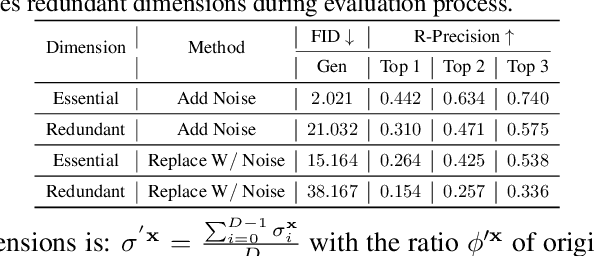
Since 2023, Vector Quantization (VQ)-based discrete generation methods have rapidly dominated human motion generation, primarily surpassing diffusion-based continuous generation methods in standard performance metrics. However, VQ-based methods have inherent limitations. Representing continuous motion data as limited discrete tokens leads to inevitable information loss, reduces the diversity of generated motions, and restricts their ability to function effectively as motion priors or generation guidance. In contrast, the continuous space generation nature of diffusion-based methods makes them well-suited to address these limitations and with even potential for model scalability. In this work, we systematically investigate why current VQ-based methods perform well and explore the limitations of existing diffusion-based methods from the perspective of motion data representation and distribution. Drawing on these insights, we preserve the inherent strengths of a diffusion-based human motion generation model and gradually optimize it with inspiration from VQ-based approaches. Our approach introduces a human motion diffusion model enabled to perform bidirectional masked autoregression, optimized with a reformed data representation and distribution. Additionally, we also propose more robust evaluation methods to fairly assess different-based methods. Extensive experiments on benchmark human motion generation datasets demonstrate that our method excels previous methods and achieves state-of-the-art performances.
HOI-Diff: Text-Driven Synthesis of 3D Human-Object Interactions using Diffusion Models
Dec 11, 2023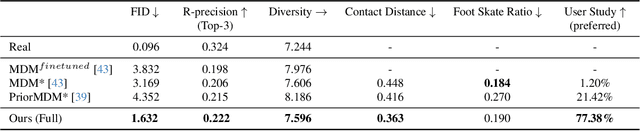
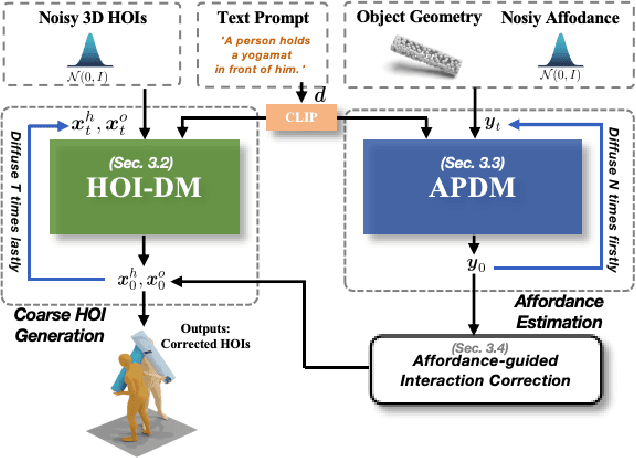
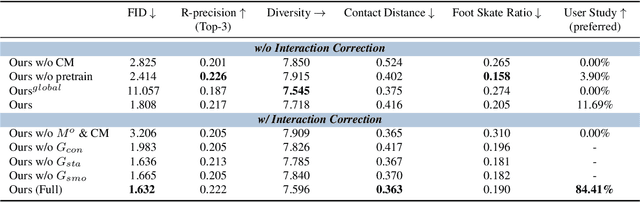
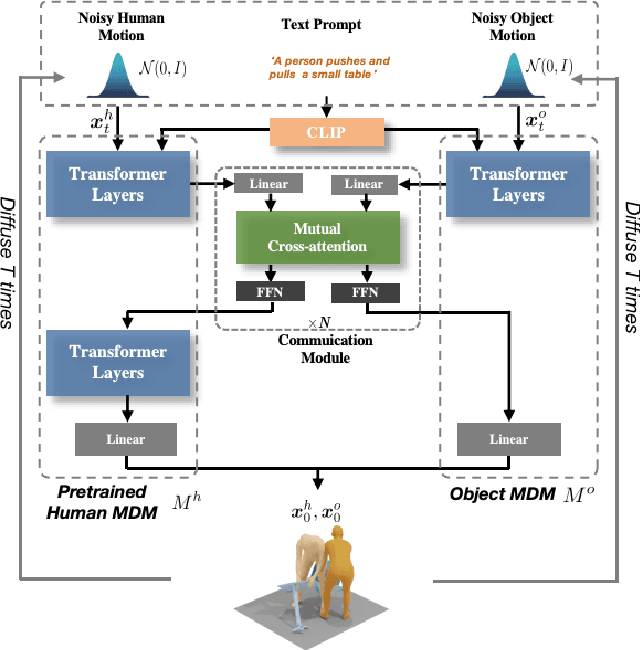
We address the problem of generating realistic 3D human-object interactions (HOIs) driven by textual prompts. Instead of a single model, our key insight is to take a modular design and decompose the complex task into simpler sub-tasks. We first develop a dual-branch diffusion model (HOI-DM) to generate both human and object motions conditioning on the input text, and encourage coherent motions by a cross-attention communication module between the human and object motion generation branches. We also develop an affordance prediction diffusion model (APDM) to predict the contacting area between the human and object during the interactions driven by the textual prompt. The APDM is independent of the results by the HOI-DM and thus can correct potential errors by the latter. Moreover, it stochastically generates the contacting points to diversify the generated motions. Finally, we incorporate the estimated contacting points into the classifier-guidance to achieve accurate and close contact between humans and objects. To train and evaluate our approach, we annotate BEHAVE dataset with text descriptions. Experimental results demonstrate that our approach is able to produce realistic HOIs with various interactions and different types of objects.
The MI-Motion Dataset and Benchmark for 3D Multi-Person Motion Prediction
Jun 26, 2023



3D multi-person motion prediction is a challenging task that involves modeling individual behaviors and interactions between people. Despite the emergence of approaches for this task, comparing them is difficult due to the lack of standardized training settings and benchmark datasets. In this paper, we introduce the Multi-Person Interaction Motion (MI-Motion) Dataset, which includes skeleton sequences of multiple individuals collected by motion capture systems and refined and synthesized using a game engine. The dataset contains 167k frames of interacting people's skeleton poses and is categorized into 5 different activity scenes. To facilitate research in multi-person motion prediction, we also provide benchmarks to evaluate the performance of prediction methods in three settings: short-term, long-term, and ultra-long-term prediction. Additionally, we introduce a novel baseline approach that leverages graph and temporal convolutional networks, which has demonstrated competitive results in multi-person motion prediction. We believe that the proposed MI-Motion benchmark dataset and baseline will facilitate future research in this area, ultimately leading to better understanding and modeling of multi-person interactions.
Learning Weakly Supervised Audio-Visual Violence Detection in Hyperbolic Space
Jun 02, 2023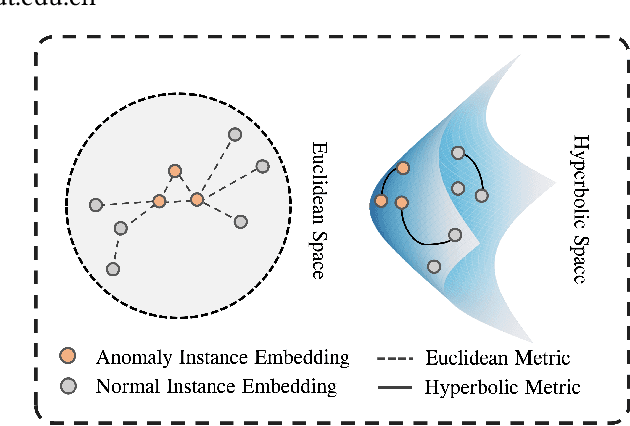
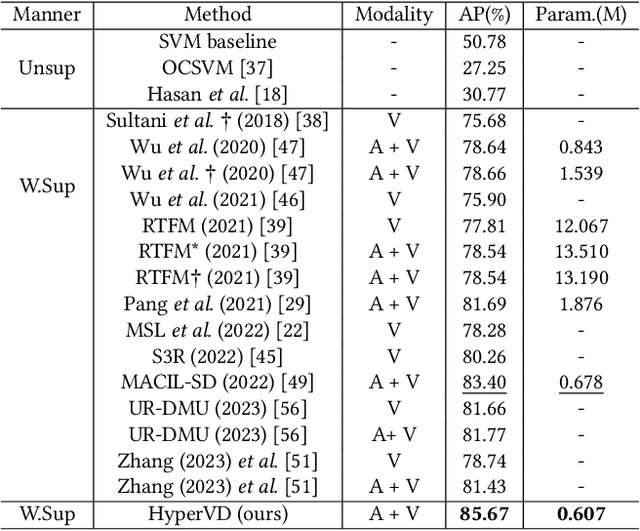
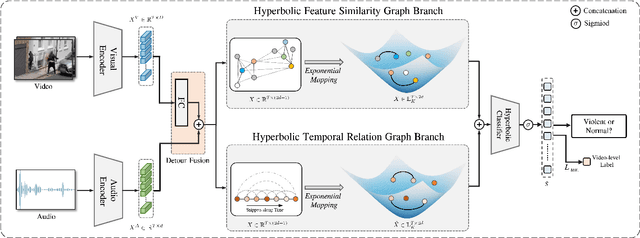
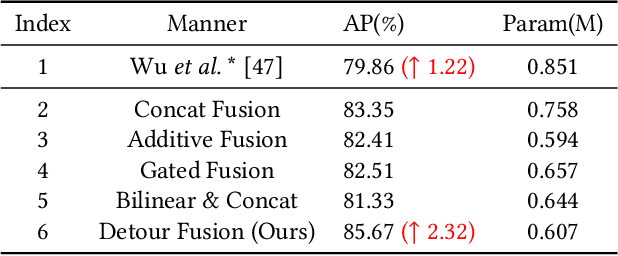
In recent years, the task of weakly supervised audio-visual violence detection has gained considerable attention. The goal of this task is to identify violent segments within multimodal data based on video-level labels. Despite advances in this field, traditional Euclidean neural networks, which have been used in prior research, encounter difficulties in capturing highly discriminative representations due to limitations of the feature space. To overcome this, we propose HyperVD, a novel framework that learns snippet embeddings in hyperbolic space to improve model discrimination. Our framework comprises a detour fusion module for multimodal fusion, effectively alleviating modality inconsistency between audio and visual signals. Additionally, we contribute two branches of fully hyperbolic graph convolutional networks that excavate feature similarities and temporal relationships among snippets in hyperbolic space. By learning snippet representations in this space, the framework effectively learns semantic discrepancies between violent and normal events. Extensive experiments on the XD-Violence benchmark demonstrate that our method outperforms state-of-the-art methods by a sizable margin.
Trajectory-Aware Body Interaction Transformer for Multi-Person Pose Forecasting
Mar 13, 2023



Multi-person pose forecasting remains a challenging problem, especially in modeling fine-grained human body interaction in complex crowd scenarios. Existing methods typically represent the whole pose sequence as a temporal series, yet overlook interactive influences among people based on skeletal body parts. In this paper, we propose a novel Trajectory-Aware Body Interaction Transformer (TBIFormer) for multi-person pose forecasting via effectively modeling body part interactions. Specifically, we construct a Temporal Body Partition Module that transforms all the pose sequences into a Multi-Person Body-Part sequence to retain spatial and temporal information based on body semantics. Then, we devise a Social Body Interaction Self-Attention (SBI-MSA) module, utilizing the transformed sequence to learn body part dynamics for inter- and intra-individual interactions. Furthermore, different from prior Euclidean distance-based spatial encodings, we present a novel and efficient Trajectory-Aware Relative Position Encoding for SBI-MSA to offer discriminative spatial information and additional interactive clues. On both short- and long-term horizons, we empirically evaluate our framework on CMU-Mocap, MuPoTS-3D as well as synthesized datasets (6 ~ 10 persons), and demonstrate that our method greatly outperforms the state-of-the-art methods. Code will be made publicly available upon acceptance.
More comprehensive facial inversion for more effective expression recognition
Nov 24, 2022Facial expression recognition (FER) plays a significant role in the ubiquitous application of computer vision. We revisit this problem with a new perspective on whether it can acquire useful representations that improve FER performance in the image generation process, and propose a novel generative method based on the image inversion mechanism for the FER task, termed Inversion FER (IFER). Particularly, we devise a novel Adversarial Style Inversion Transformer (ASIT) towards IFER to comprehensively extract features of generated facial images. In addition, ASIT is equipped with an image inversion discriminator that measures the cosine similarity of semantic features between source and generated images, constrained by a distribution alignment loss. Finally, we introduce a feature modulation module to fuse the structural code and latent codes from ASIT for the subsequent FER work. We extensively evaluate ASIT on facial datasets such as FFHQ and CelebA-HQ, showing that our approach achieves state-of-the-art facial inversion performance. IFER also achieves competitive results in facial expression recognition datasets such as RAF-DB, SFEW and AffectNet. The code and models are available at https://github.com/Talented-Q/IFER-master.
PointCMC: Cross-Modal Multi-Scale Correspondences Learning for Point Cloud Understanding
Nov 23, 2022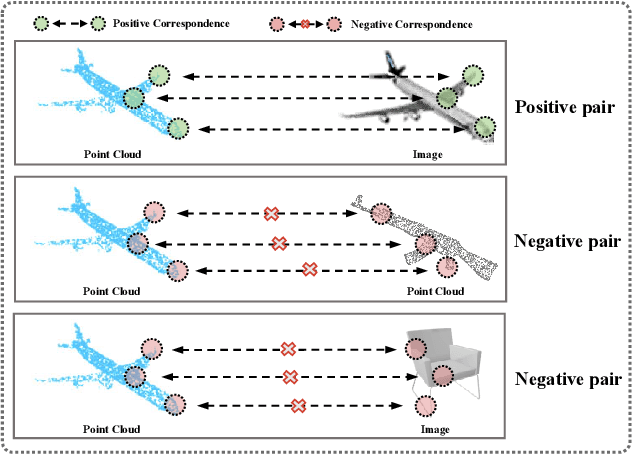

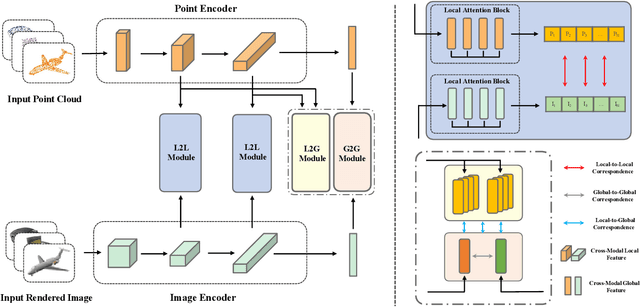
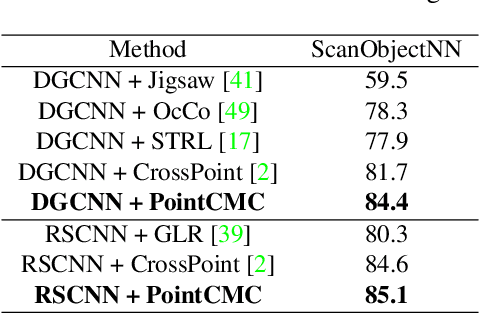
Some self-supervised cross-modal learning approaches have recently demonstrated the potential of image signals for enhancing point cloud representation. However, it remains a question on how to directly model cross-modal local and global correspondences in a self-supervised fashion. To solve it, we proposed PointCMC, a novel cross-modal method to model multi-scale correspondences across modalities for self-supervised point cloud representation learning. In particular, PointCMC is composed of: (1) a local-to-local (L2L) module that learns local correspondences through optimized cross-modal local geometric features, (2) a local-to-global (L2G) module that aims to learn the correspondences between local and global features across modalities via local-global discrimination, and (3) a global-to-global (G2G) module, which leverages auxiliary global contrastive loss between the point cloud and image to learn high-level semantic correspondences. Extensive experiment results show that our approach outperforms existing state-of-the-art methods in various downstream tasks such as 3D object classification and segmentation. Code will be made publicly available upon acceptance.
SoMoFormer: Social-Aware Motion Transformer for Multi-Person Motion Prediction
Aug 19, 2022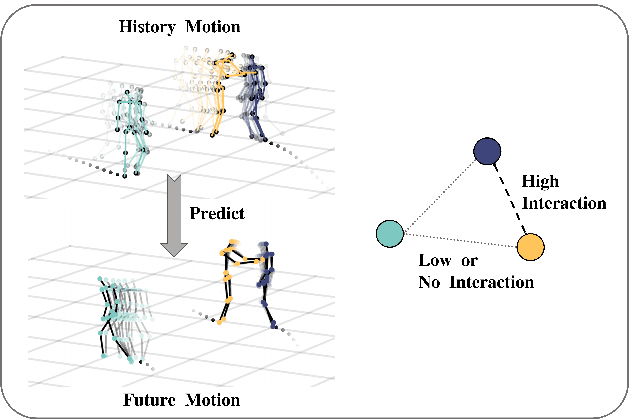
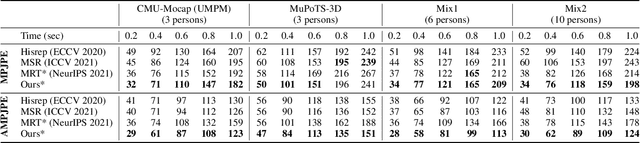
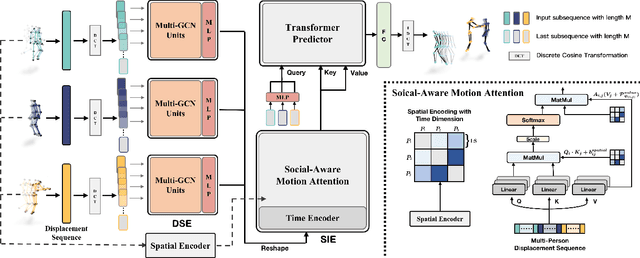
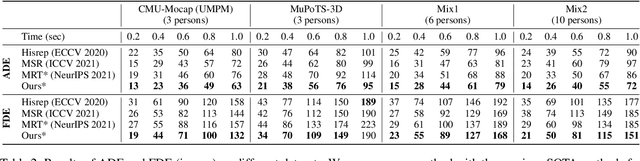
Multi-person motion prediction remains a challenging problem, especially in the joint representation learning of individual motion and social interactions. Most prior methods only involve learning local pose dynamics for individual motion (without global body trajectory) and also struggle to capture complex interaction dependencies for social interactions. In this paper, we propose a novel Social-Aware Motion Transformer (SoMoFormer) to effectively model individual motion and social interactions in a joint manner. Specifically, SoMoFormer extracts motion features from sub-sequences in displacement trajectory space to effectively learn both local and global pose dynamics for each individual. In addition, we devise a novel social-aware motion attention mechanism in SoMoFormer to further optimize dynamics representations and capture interaction dependencies simultaneously via motion similarity calculation across time and social dimensions. On both short- and long-term horizons, we empirically evaluate our framework on multi-person motion datasets and demonstrate that our method greatly outperforms state-of-the-art methods of single- and multi-person motion prediction. Code will be made publicly available upon acceptance.