 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAllRestorer: All-in-One Transformer for Image Restoration under Composite Degradations
Nov 16, 2024Image restoration models often face the simultaneous interaction of multiple degradations in real-world scenarios. Existing approaches typically handle single or composite degradations based on scene descriptors derived from text or image embeddings. However, due to the varying proportions of different degradations within an image, these scene descriptors may not accurately differentiate between degradations, leading to suboptimal restoration in practical applications. To address this issue, we propose a novel Transformer-based restoration framework, AllRestorer. In AllRestorer, we enable the model to adaptively consider all image impairments, thereby avoiding errors from scene descriptor misdirection. Specifically, we introduce an All-in-One Transformer Block (AiOTB), which adaptively removes all degradations present in a given image by modeling the relationships between all degradations and the image embedding in latent space. To accurately address different variations potentially present within the same type of degradation and minimize ambiguity, AiOTB utilizes a composite scene descriptor consisting of both image and text embeddings to define the degradation. Furthermore, AiOTB includes an adaptive weight for each degradation, allowing for precise control of the restoration intensity. By leveraging AiOTB, AllRestorer avoids misdirection caused by inaccurate scene descriptors, achieving a 5.00 dB increase in PSNR compared to the baseline on the CDD-11 dataset.
SwinStyleformer is a favorable choice for image inversion
Jun 19, 2024



This paper proposes the first pure Transformer structure inversion network called SwinStyleformer, which can compensate for the shortcomings of the CNNs inversion framework by handling long-range dependencies and learning the global structure of objects. Experiments found that the inversion network with the Transformer backbone could not successfully invert the image. The above phenomena arise from the differences between CNNs and Transformers, such as the self-attention weights favoring image structure ignoring image details compared to convolution, the lack of multi-scale properties of Transformer, and the distribution differences between the latent code extracted by the Transformer and the StyleGAN style vector. To address these differences, we employ the Swin Transformer with a smaller window size as the backbone of the SwinStyleformer to enhance the local detail of the inversion image. Meanwhile, we design a Transformer block based on learnable queries. Compared to the self-attention transformer block, the Transformer block based on learnable queries provides greater adaptability and flexibility, enabling the model to update the attention weights according to specific tasks. Thus, the inversion focus is not limited to the image structure. To further introduce multi-scale properties, we design multi-scale connections in the extraction of feature maps. Multi-scale connections allow the model to gain a comprehensive understanding of the image to avoid loss of detail due to global modeling. Moreover, we propose an inversion discriminator and distribution alignment loss to minimize the distribution differences. Based on the above designs, our SwinStyleformer successfully solves the Transformer's inversion failure issue and demonstrates SOTA performance in image inversion and several related vision tasks.
Restorer: Solving Multiple Image Restoration Tasks with One Set of Parameters
Jun 18, 2024
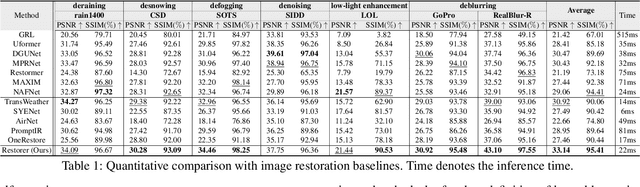
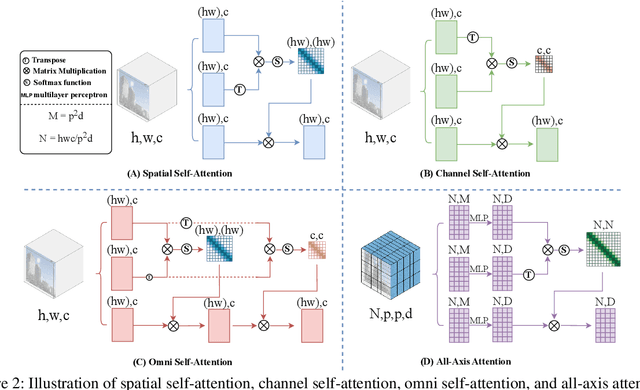
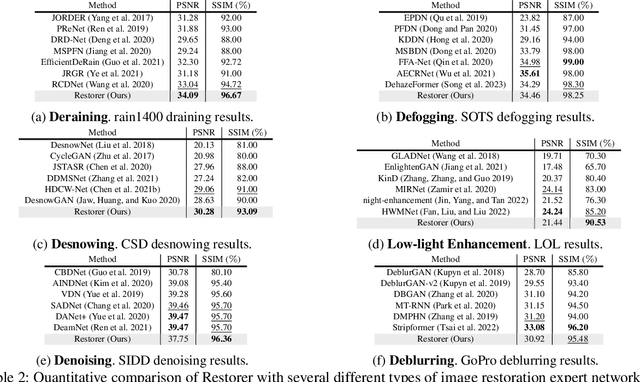
Although there are many excellent solutions in image restoration, the fact that they are specifically designed for a single image restoration task may prevent them from being state-of-the-art (SOTA) in other types of image restoration tasks. While some approaches require considering multiple image restoration tasks, they are still not sufficient for the requirements of the real world and may suffer from the task confusion issue. In this work, we focus on designing a unified and effective solution for multiple image restoration tasks including deraining, desnowing, defogging, deblurring, denoising, and low-light enhancement. Based on the above purpose, we propose a Transformer network Restorer with U-Net architecture. In order to effectively deal with degraded information in multiple image restoration tasks, we need a more comprehensive attention mechanism. Thus, we design all-axis attention (AAA) through stereo embedding and 3D convolution, which can simultaneously model the long-range dependencies in both spatial and channel dimensions, capturing potential correlations among all axis. Moreover, we propose a Restorer based on textual prompts. Compared to previous methods that employ learnable queries, textual prompts bring explicit task priors to solve the task confusion issue arising from learnable queries and introduce interactivity. Based on these designs, Restorer demonstrates SOTA or comparable performance in multiple image restoration tasks compared to universal image restoration frameworks and methods specifically designed for these individual tasks. Meanwhile, Restorer is faster during inference. The above results along with the real-world test results show that Restorer has the potential to serve as a backbone for multiple real-world image restoration tasks.
Exploring the Correlation Between Ultrasound Speed and the State of Health of LiFePO$_4$ Prismatic Cells
Sep 24, 2023



Electric vehicles (EVs) have become a popular mode of transportation, with their performance depending on the ageing of the Li-ion batteries used to power them. However, it can be challenging and time-consuming to determine the capacity retention of a battery in service. A rapid and reliable testing method for state of health (SoH) determination is desired. Ultrasonic testing techniques are promising due to their efficient, portable, and non-destructive features. In this study, we demonstrate that ultrasonic speed decreases with the degradation of the capacity of an LFP prismatic cell. We explain this correlation through numerical simulation, which describes wave propagation in porous media. We propose that the reduction of binder stiffness can be a primary cause of the change in ultrasonic speed during battery ageing. This work brings new insights into ultrasonic SoH estimation techniques.
Medical supervised masked autoencoders: Crafting a better masking strategy and efficient fine-tuning schedule for medical image classification
May 10, 2023



Masked autoencoders (MAEs) have displayed significant potential in the classification and semantic segmentation of medical images in the last year. Due to the high similarity of human tissues, even slight changes in medical images may represent diseased tissues, necessitating fine-grained inspection to pinpoint diseased tissues. The random masking strategy of MAEs is likely to result in areas of lesions being overlooked by the model. At the same time, inconsistencies between the pre-training and fine-tuning phases impede the performance and efficiency of MAE in medical image classification. To address these issues, we propose a medical supervised masked autoencoder (MSMAE) in this paper. In the pre-training phase, MSMAE precisely masks medical images via the attention maps obtained from supervised training, contributing to the representation learning of human tissue in the lesion area. During the fine-tuning phase, MSMAE is also driven by attention to the accurate masking of medical images. This improves the computational efficiency of the MSMAE while increasing the difficulty of fine-tuning, which indirectly improves the quality of MSMAE medical diagnosis. Extensive experiments demonstrate that MSMAE achieves state-of-the-art performance in case with three official medical datasets for various diseases. Meanwhile, transfer learning for MSMAE also demonstrates the great potential of our approach for medical semantic segmentation tasks. Moreover, the MSMAE accelerates the inference time in the fine-tuning phase by 11.2% and reduces the number of floating-point operations (FLOPs) by 74.08% compared to a traditional MAE.
Star-Net: Improving Single Image Desnowing Model With More Efficient Connection and Diverse Feature Interaction
Mar 17, 2023Compared to other severe weather image restoration tasks, single image desnowing is a more challenging task. This is mainly due to the diversity and irregularity of snow shape, which makes it extremely difficult to restore images in snowy scenes. Moreover, snow particles also have a veiling effect similar to haze or mist. Although current works can effectively remove snow particles with various shapes, they also bring distortion to the restored image. To address these issues, we propose a novel single image desnowing network called Star-Net. First, we design a Star type Skip Connection (SSC) to establish information channels for all different scale features, which can deal with the complex shape of snow particles.Second, we present a Multi-Stage Interactive Transformer (MIT) as the base module of Star-Net, which is designed to better understand snow particle shapes and to address image distortion by explicitly modeling a variety of important image recovery features. Finally, we propose a Degenerate Filter Module (DFM) to filter the snow particle and snow fog residual in the SSC on the spatial and channel domains. Extensive experiments show that our Star-Net achieves state-of-the-art snow removal performances on three standard snow removal datasets and retains the original sharpness of the images.
POSTER++: A simpler and stronger facial expression recognition network
Feb 12, 2023



Facial expression recognition (FER) plays an important role in a variety of real-world applications such as human-computer interaction. POSTER achieves the state-of-the-art (SOTA) performance in FER by effectively combining facial landmark and image features through two-stream pyramid cross-fusion design. However, the architecture of POSTER is undoubtedly complex. It causes expensive computational costs. In order to relieve the computational pressure of POSTER, in this paper, we propose POSTER++. It improves POSTER in three directions: cross-fusion, two-stream, and multi-scale feature extraction. In cross-fusion, we use window-based cross-attention mechanism replacing vanilla cross-attention mechanism. We remove the image-to-landmark branch in the two-stream design. For multi-scale feature extraction, POSTER++ combines images with landmark's multi-scale features to replace POSTER's pyramid design. Extensive experiments on several standard datasets show that our POSTER++ achieves the SOTA FER performance with the minimum computational cost. For example, POSTER++ reached 92.21% on RAF-DB, 67.49% on AffectNet (7 cls) and 63.77% on AffectNet (8 cls), respectively, using only 8.4G floating point operations (FLOPs) and 43.7M parameters (Param). This demonstrates the effectiveness of our improvements.
Masked autoencoders are effective solution to transformer data-hungry
Dec 13, 2022



Vision Transformers (ViTs) outperforms convolutional neural networks (CNNs) in several vision tasks with its global modeling capabilities. However, ViT lacks the inductive bias inherent to convolution making it require a large amount of data for training. This results in ViT not performing as well as CNNs on small datasets like medicine and science. We experimentally found that masked autoencoders (MAE) can make the transformer focus more on the image itself, thus alleviating the data-hungry issue of ViT to some extent. Yet the current MAE model is too complex resulting in over-fitting problems on small datasets. This leads to a gap between MAEs trained on small datasets and advanced CNNs models still. Therefore, we investigated how to reduce the decoder complexity in MAE and found a more suitable architectural configuration for it with small datasets. Besides, we additionally designed a location prediction task and a contrastive learning task to introduce localization and invariance characteristics for MAE. Our contrastive learning task not only enables the model to learn high-level visual information but also allows the training of MAE's class token. This is something that most MAE improvement efforts do not consider. Extensive experiments have shown that our method shows state-of-the-art performance on standard small datasets as well as medical datasets with few samples compared to the current popular masked image modeling (MIM) and vision transformers for small datasets.The code and models are available at https://github.com/Talented-Q/SDMAE.
More comprehensive facial inversion for more effective expression recognition
Nov 24, 2022Facial expression recognition (FER) plays a significant role in the ubiquitous application of computer vision. We revisit this problem with a new perspective on whether it can acquire useful representations that improve FER performance in the image generation process, and propose a novel generative method based on the image inversion mechanism for the FER task, termed Inversion FER (IFER). Particularly, we devise a novel Adversarial Style Inversion Transformer (ASIT) towards IFER to comprehensively extract features of generated facial images. In addition, ASIT is equipped with an image inversion discriminator that measures the cosine similarity of semantic features between source and generated images, constrained by a distribution alignment loss. Finally, we introduce a feature modulation module to fuse the structural code and latent codes from ASIT for the subsequent FER work. We extensively evaluate ASIT on facial datasets such as FFHQ and CelebA-HQ, showing that our approach achieves state-of-the-art facial inversion performance. IFER also achieves competitive results in facial expression recognition datasets such as RAF-DB, SFEW and AffectNet. The code and models are available at https://github.com/Talented-Q/IFER-master.
Token Transformer: Can class token help window-based transformer build better long-range interactions?
Nov 11, 2022Compared with the vanilla transformer, the window-based transformer offers a better trade-off between accuracy and efficiency. Although the window-based transformer has made great progress, its long-range modeling capabilities are limited due to the size of the local window and the window connection scheme. To address this problem, we propose a novel Token Transformer (TT). The core mechanism of TT is the addition of a Class (CLS) token for summarizing window information in each local window. We refer to this type of token interaction as CLS Attention. These CLS tokens will interact spatially with the tokens in each window to enable long-range modeling. In order to preserve the hierarchical design of the window-based transformer, we designed Feature Inheritance Module (FIM) in each phase of TT to deliver the local window information from the previous phase to the CLS token in the next phase. In addition, we have designed a Spatial-Channel Feedforward Network (SCFFN) in TT, which can mix CLS tokens and embedded tokens on the spatial domain and channel domain without additional parameters. Extensive experiments have shown that our TT achieves competitive results with low parameters in image classification and downstream tasks.