 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinStyleformer is a favorable choice for image inversion
Jun 19, 2024



This paper proposes the first pure Transformer structure inversion network called SwinStyleformer, which can compensate for the shortcomings of the CNNs inversion framework by handling long-range dependencies and learning the global structure of objects. Experiments found that the inversion network with the Transformer backbone could not successfully invert the image. The above phenomena arise from the differences between CNNs and Transformers, such as the self-attention weights favoring image structure ignoring image details compared to convolution, the lack of multi-scale properties of Transformer, and the distribution differences between the latent code extracted by the Transformer and the StyleGAN style vector. To address these differences, we employ the Swin Transformer with a smaller window size as the backbone of the SwinStyleformer to enhance the local detail of the inversion image. Meanwhile, we design a Transformer block based on learnable queries. Compared to the self-attention transformer block, the Transformer block based on learnable queries provides greater adaptability and flexibility, enabling the model to update the attention weights according to specific tasks. Thus, the inversion focus is not limited to the image structure. To further introduce multi-scale properties, we design multi-scale connections in the extraction of feature maps. Multi-scale connections allow the model to gain a comprehensive understanding of the image to avoid loss of detail due to global modeling. Moreover, we propose an inversion discriminator and distribution alignment loss to minimize the distribution differences. Based on the above designs, our SwinStyleformer successfully solves the Transformer's inversion failure issue and demonstrates SOTA performance in image inversion and several related vision tasks.
More comprehensive facial inversion for more effective expression recognition
Nov 24, 2022Facial expression recognition (FER) plays a significant role in the ubiquitous application of computer vision. We revisit this problem with a new perspective on whether it can acquire useful representations that improve FER performance in the image generation process, and propose a novel generative method based on the image inversion mechanism for the FER task, termed Inversion FER (IFER). Particularly, we devise a novel Adversarial Style Inversion Transformer (ASIT) towards IFER to comprehensively extract features of generated facial images. In addition, ASIT is equipped with an image inversion discriminator that measures the cosine similarity of semantic features between source and generated images, constrained by a distribution alignment loss. Finally, we introduce a feature modulation module to fuse the structural code and latent codes from ASIT for the subsequent FER work. We extensively evaluate ASIT on facial datasets such as FFHQ and CelebA-HQ, showing that our approach achieves state-of-the-art facial inversion performance. IFER also achieves competitive results in facial expression recognition datasets such as RAF-DB, SFEW and AffectNet. The code and models are available at https://github.com/Talented-Q/IFER-master.
Self-Supervised Deep Subspace Clustering with Entropy-norm
Jun 10, 2022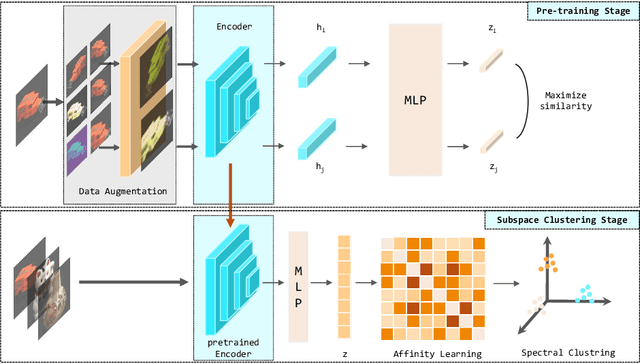
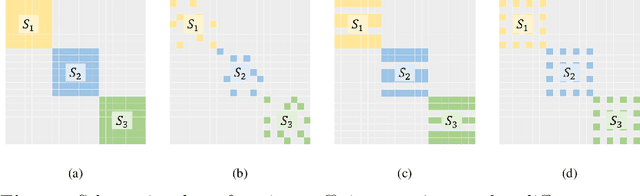

Auto-Encoder based deep subspace clustering (DSC) is widely used in computer vision, motion segmentation and image processing. However, it suffers from the following three issues in the self-expressive matrix learning process: the first one is less useful information for learning self-expressive weights due to the simple reconstruction loss; the second one is that the construction of the self-expression layer associated with the sample size requires high-computational cost; and the last one is the limited connectivity of the existing regularization terms. In order to address these issues, in this paper we propose a novel model named Self-Supervised deep Subspace Clustering with Entropy-norm (S$^{3}$CE). Specifically, S$^{3}$CE exploits a self-supervised contrastive network to gain a more effetive feature vector. The local structure and dense connectivity of the original data benefit from the self-expressive layer and additional entropy-norm constraint. Moreover, a new module with data enhancement is designed to help S$^{3}$CE focus on the key information of data, and improve the clustering performance of positive and negative instances through spectral clustering. Extensive experimental results demonstrate the superior performance of S$^{3}$CE in comparison to the state-of-the-art approaches.