 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked autoencoders are effective solution to transformer data-hungry
Dec 13, 2022



Vision Transformers (ViTs) outperforms convolutional neural networks (CNNs) in several vision tasks with its global modeling capabilities. However, ViT lacks the inductive bias inherent to convolution making it require a large amount of data for training. This results in ViT not performing as well as CNNs on small datasets like medicine and science. We experimentally found that masked autoencoders (MAE) can make the transformer focus more on the image itself, thus alleviating the data-hungry issue of ViT to some extent. Yet the current MAE model is too complex resulting in over-fitting problems on small datasets. This leads to a gap between MAEs trained on small datasets and advanced CNNs models still. Therefore, we investigated how to reduce the decoder complexity in MAE and found a more suitable architectural configuration for it with small datasets. Besides, we additionally designed a location prediction task and a contrastive learning task to introduce localization and invariance characteristics for MAE. Our contrastive learning task not only enables the model to learn high-level visual information but also allows the training of MAE's class token. This is something that most MAE improvement efforts do not consider. Extensive experiments have shown that our method shows state-of-the-art performance on standard small datasets as well as medical datasets with few samples compared to the current popular masked image modeling (MIM) and vision transformers for small datasets.The code and models are available at https://github.com/Talented-Q/SDMAE.
PointCMC: Cross-Modal Multi-Scale Correspondences Learning for Point Cloud Understanding
Nov 23, 2022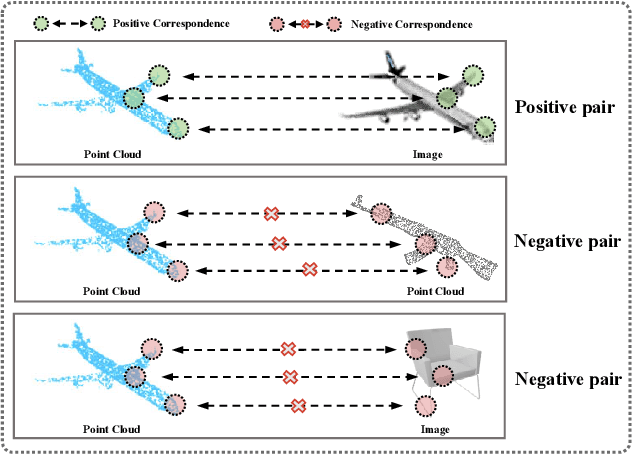

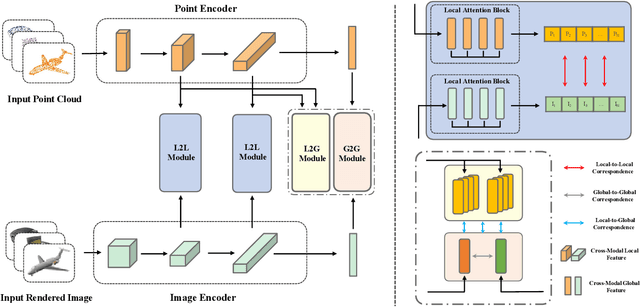
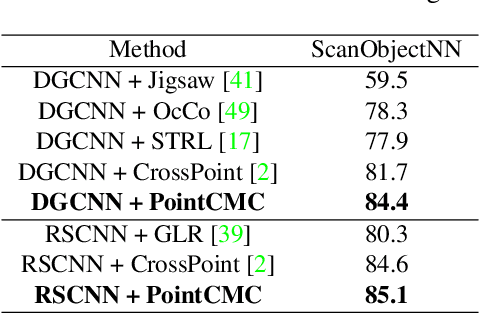
Some self-supervised cross-modal learning approaches have recently demonstrated the potential of image signals for enhancing point cloud representation. However, it remains a question on how to directly model cross-modal local and global correspondences in a self-supervised fashion. To solve it, we proposed PointCMC, a novel cross-modal method to model multi-scale correspondences across modalities for self-supervised point cloud representation learning. In particular, PointCMC is composed of: (1) a local-to-local (L2L) module that learns local correspondences through optimized cross-modal local geometric features, (2) a local-to-global (L2G) module that aims to learn the correspondences between local and global features across modalities via local-global discrimination, and (3) a global-to-global (G2G) module, which leverages auxiliary global contrastive loss between the point cloud and image to learn high-level semantic correspondences. Extensive experiment results show that our approach outperforms existing state-of-the-art methods in various downstream tasks such as 3D object classification and segmentation. Code will be made publicly available upon acceptance.
Improvements to Self-Supervised Representation Learning for Masked Image Modeling
May 21, 2022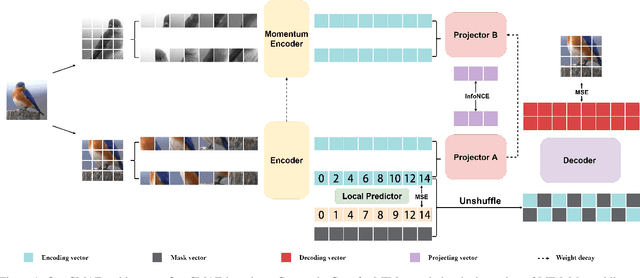
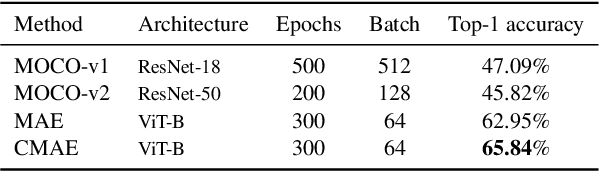

This paper explores improvements to the masked image modeling (MIM) paradigm. The MIM paradigm enables the model to learn the main object features of the image by masking the input image and predicting the masked part by the unmasked part. We found the following three main directions for MIM to be improved. First, since both encoders and decoders contribute to representation learning, MIM uses only encoders for downstream tasks, which ignores the impact of decoders on representation learning. Although the MIM paradigm already employs small decoders with asymmetric structures, we believe that continued reduction of decoder parameters is beneficial to improve the representational learning capability of the encoder . Second, MIM solves the image prediction task by training the encoder and decoder together , and does not design a separate task for the encoder . To further enhance the performance of the encoder when performing downstream tasks, we designed the encoder for the tasks of comparative learning and token position prediction. Third, since the input image may contain background and other objects, and the proportion of each object in the image varies, reconstructing the tokens related to the background or to other objects is not meaningful for MIM to understand the main object representations. Therefore we use ContrastiveCrop to crop the input image so that the input image contains as much as possible only the main objects. Based on the above three improvements to MIM, we propose a new model, Contrastive Masked AutoEncoders (CMAE). We achieved a Top-1 accuracy of 65.84% on tinyimagenet using the ViT-B backbone, which is +2.89 outperforming the MAE of competing methods when all conditions are equal. Code will be made available.