 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCMC: Cross-Modal Multi-Scale Correspondences Learning for Point Cloud Understanding
Paper and Code
Nov 23, 2022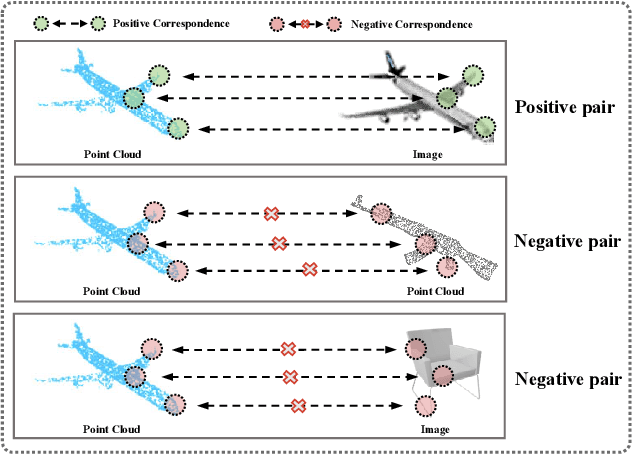

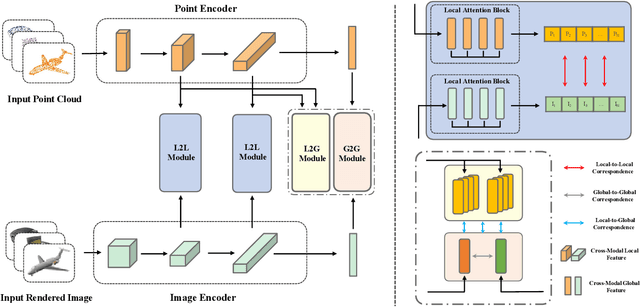
Some self-supervised cross-modal learning approaches have recently demonstrated the potential of image signals for enhancing point cloud representation. However, it remains a question on how to directly model cross-modal local and global correspondences in a self-supervised fashion. To solve it, we proposed PointCMC, a novel cross-modal method to model multi-scale correspondences across modalities for self-supervised point cloud representation learning. In particular, PointCMC is composed of: (1) a local-to-local (L2L) module that learns local correspondences through optimized cross-modal local geometric features, (2) a local-to-global (L2G) module that aims to learn the correspondences between local and global features across modalities via local-global discrimination, and (3) a global-to-global (G2G) module, which leverages auxiliary global contrastive loss between the point cloud and image to learn high-level semantic correspondences. Extensive experiment results show that our approach outperforms existing state-of-the-art methods in various downstream tasks such as 3D object classification and segmentation. Code will be made publicly available upon acceptance.