 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovements to Self-Supervised Representation Learning for Masked Image Modeling
Paper and Code
May 21, 2022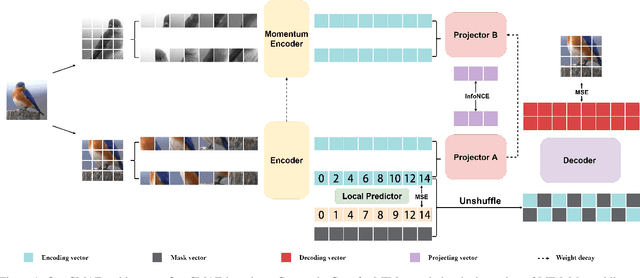
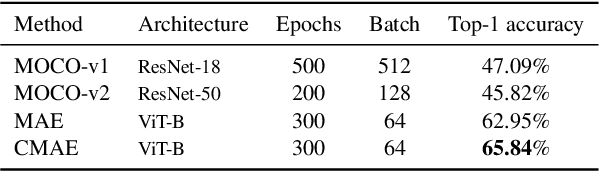

This paper explores improvements to the masked image modeling (MIM) paradigm. The MIM paradigm enables the model to learn the main object features of the image by masking the input image and predicting the masked part by the unmasked part. We found the following three main directions for MIM to be improved. First, since both encoders and decoders contribute to representation learning, MIM uses only encoders for downstream tasks, which ignores the impact of decoders on representation learning. Although the MIM paradigm already employs small decoders with asymmetric structures, we believe that continued reduction of decoder parameters is beneficial to improve the representational learning capability of the encoder . Second, MIM solves the image prediction task by training the encoder and decoder together , and does not design a separate task for the encoder . To further enhance the performance of the encoder when performing downstream tasks, we designed the encoder for the tasks of comparative learning and token position prediction. Third, since the input image may contain background and other objects, and the proportion of each object in the image varies, reconstructing the tokens related to the background or to other objects is not meaningful for MIM to understand the main object representations. Therefore we use ContrastiveCrop to crop the input image so that the input image contains as much as possible only the main objects. Based on the above three improvements to MIM, we propose a new model, Contrastive Masked AutoEncoders (CMAE). We achieved a Top-1 accuracy of 65.84% on tinyimagenet using the ViT-B backbone, which is +2.89 outperforming the MAE of competing methods when all conditions are equal. Code will be made available.