 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical supervised masked autoencoders: Crafting a better masking strategy and efficient fine-tuning schedule for medical image classification
May 10, 2023



Masked autoencoders (MAEs) have displayed significant potential in the classification and semantic segmentation of medical images in the last year. Due to the high similarity of human tissues, even slight changes in medical images may represent diseased tissues, necessitating fine-grained inspection to pinpoint diseased tissues. The random masking strategy of MAEs is likely to result in areas of lesions being overlooked by the model. At the same time, inconsistencies between the pre-training and fine-tuning phases impede the performance and efficiency of MAE in medical image classification. To address these issues, we propose a medical supervised masked autoencoder (MSMAE) in this paper. In the pre-training phase, MSMAE precisely masks medical images via the attention maps obtained from supervised training, contributing to the representation learning of human tissue in the lesion area. During the fine-tuning phase, MSMAE is also driven by attention to the accurate masking of medical images. This improves the computational efficiency of the MSMAE while increasing the difficulty of fine-tuning, which indirectly improves the quality of MSMAE medical diagnosis. Extensive experiments demonstrate that MSMAE achieves state-of-the-art performance in case with three official medical datasets for various diseases. Meanwhile, transfer learning for MSMAE also demonstrates the great potential of our approach for medical semantic segmentation tasks. Moreover, the MSMAE accelerates the inference time in the fine-tuning phase by 11.2% and reduces the number of floating-point operations (FLOPs) by 74.08% compared to a traditional MAE.
Star-Net: Improving Single Image Desnowing Model With More Efficient Connection and Diverse Feature Interaction
Mar 17, 2023Compared to other severe weather image restoration tasks, single image desnowing is a more challenging task. This is mainly due to the diversity and irregularity of snow shape, which makes it extremely difficult to restore images in snowy scenes. Moreover, snow particles also have a veiling effect similar to haze or mist. Although current works can effectively remove snow particles with various shapes, they also bring distortion to the restored image. To address these issues, we propose a novel single image desnowing network called Star-Net. First, we design a Star type Skip Connection (SSC) to establish information channels for all different scale features, which can deal with the complex shape of snow particles.Second, we present a Multi-Stage Interactive Transformer (MIT) as the base module of Star-Net, which is designed to better understand snow particle shapes and to address image distortion by explicitly modeling a variety of important image recovery features. Finally, we propose a Degenerate Filter Module (DFM) to filter the snow particle and snow fog residual in the SSC on the spatial and channel domains. Extensive experiments show that our Star-Net achieves state-of-the-art snow removal performances on three standard snow removal datasets and retains the original sharpness of the images.
POSTER++: A simpler and stronger facial expression recognition network
Feb 12, 2023



Facial expression recognition (FER) plays an important role in a variety of real-world applications such as human-computer interaction. POSTER achieves the state-of-the-art (SOTA) performance in FER by effectively combining facial landmark and image features through two-stream pyramid cross-fusion design. However, the architecture of POSTER is undoubtedly complex. It causes expensive computational costs. In order to relieve the computational pressure of POSTER, in this paper, we propose POSTER++. It improves POSTER in three directions: cross-fusion, two-stream, and multi-scale feature extraction. In cross-fusion, we use window-based cross-attention mechanism replacing vanilla cross-attention mechanism. We remove the image-to-landmark branch in the two-stream design. For multi-scale feature extraction, POSTER++ combines images with landmark's multi-scale features to replace POSTER's pyramid design. Extensive experiments on several standard datasets show that our POSTER++ achieves the SOTA FER performance with the minimum computational cost. For example, POSTER++ reached 92.21% on RAF-DB, 67.49% on AffectNet (7 cls) and 63.77% on AffectNet (8 cls), respectively, using only 8.4G floating point operations (FLOPs) and 43.7M parameters (Param). This demonstrates the effectiveness of our improvements.
SoMoFormer: Social-Aware Motion Transformer for Multi-Person Motion Prediction
Aug 19, 2022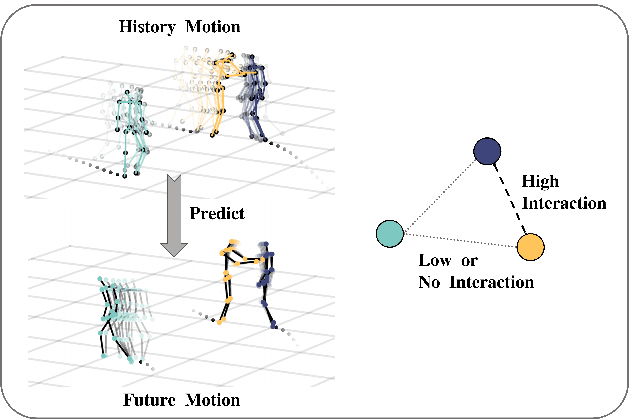
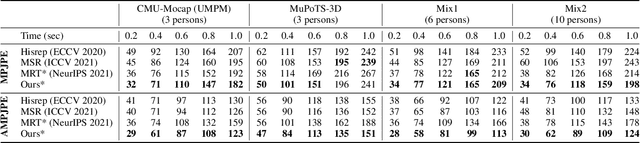
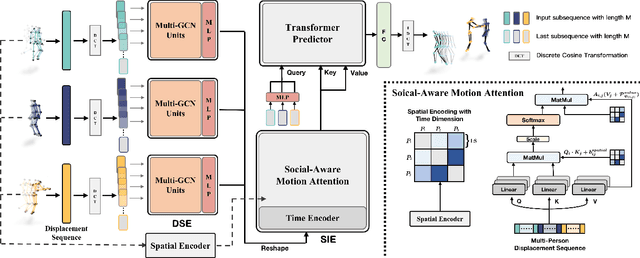
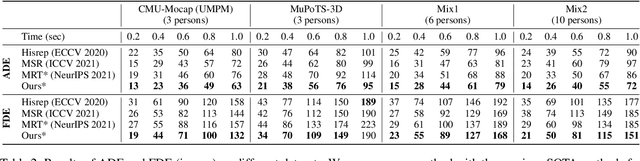
Multi-person motion prediction remains a challenging problem, especially in the joint representation learning of individual motion and social interactions. Most prior methods only involve learning local pose dynamics for individual motion (without global body trajectory) and also struggle to capture complex interaction dependencies for social interactions. In this paper, we propose a novel Social-Aware Motion Transformer (SoMoFormer) to effectively model individual motion and social interactions in a joint manner. Specifically, SoMoFormer extracts motion features from sub-sequences in displacement trajectory space to effectively learn both local and global pose dynamics for each individual. In addition, we devise a novel social-aware motion attention mechanism in SoMoFormer to further optimize dynamics representations and capture interaction dependencies simultaneously via motion similarity calculation across time and social dimensions. On both short- and long-term horizons, we empirically evaluate our framework on multi-person motion datasets and demonstrate that our method greatly outperforms state-of-the-art methods of single- and multi-person motion prediction. Code will be made publicly available upon acceptance.