 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoMoFormer: Social-Aware Motion Transformer for Multi-Person Motion Prediction
Paper and Code
Aug 19, 2022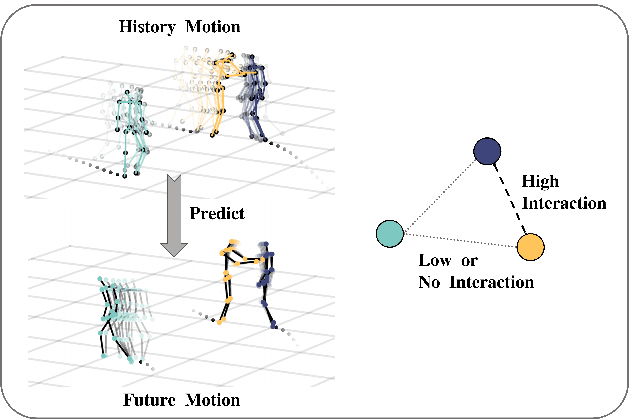
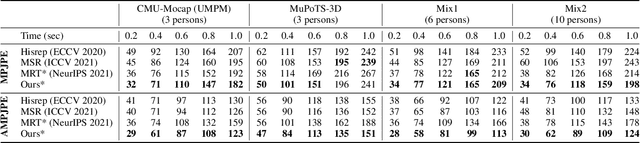
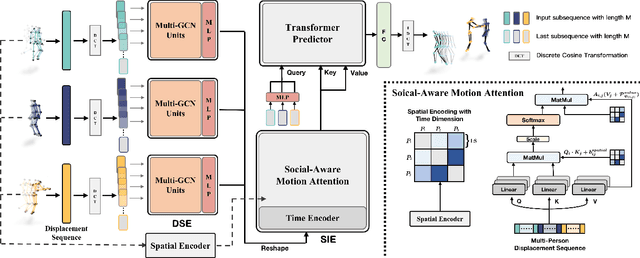
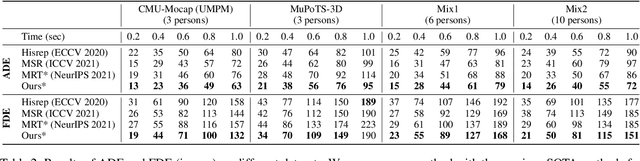
Multi-person motion prediction remains a challenging problem, especially in the joint representation learning of individual motion and social interactions. Most prior methods only involve learning local pose dynamics for individual motion (without global body trajectory) and also struggle to capture complex interaction dependencies for social interactions. In this paper, we propose a novel Social-Aware Motion Transformer (SoMoFormer) to effectively model individual motion and social interactions in a joint manner. Specifically, SoMoFormer extracts motion features from sub-sequences in displacement trajectory space to effectively learn both local and global pose dynamics for each individual. In addition, we devise a novel social-aware motion attention mechanism in SoMoFormer to further optimize dynamics representations and capture interaction dependencies simultaneously via motion similarity calculation across time and social dimensions. On both short- and long-term horizons, we empirically evaluate our framework on multi-person motion datasets and demonstrate that our method greatly outperforms state-of-the-art methods of single- and multi-person motion prediction. Code will be made publicly available upon acceptance.