 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Learning Weakly Supervised Audio-Visual Violence Detection in Hyperbolic Space
Jun 02, 2023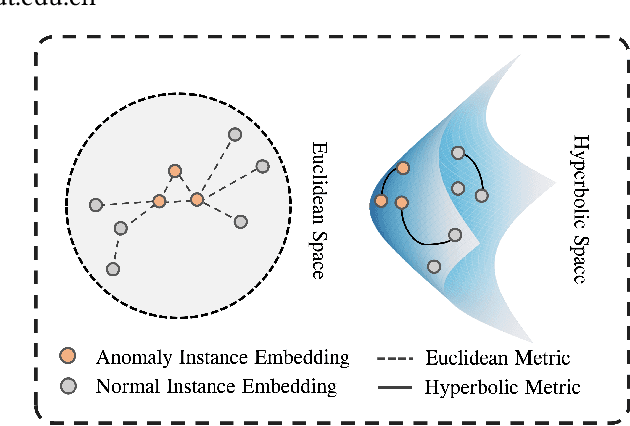
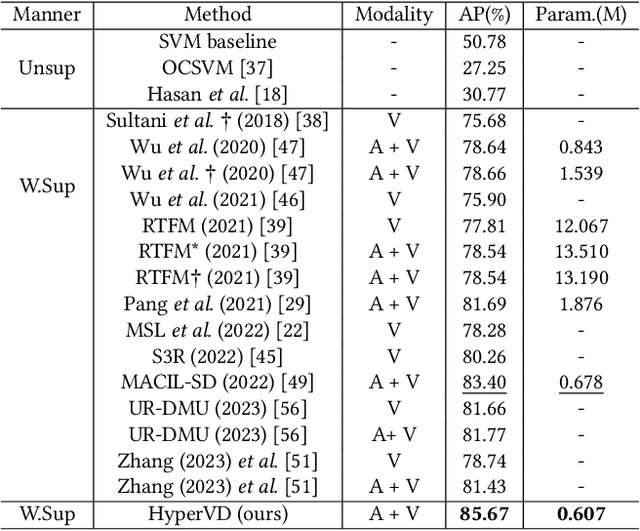
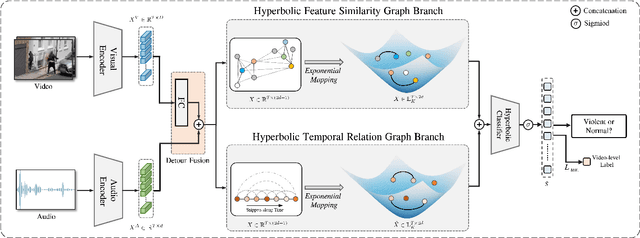
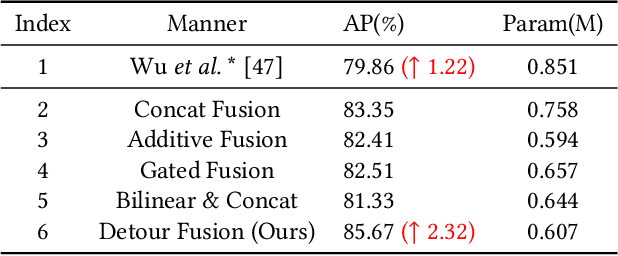
In recent years, the task of weakly supervised audio-visual violence detection has gained considerable attention. The goal of this task is to identify violent segments within multimodal data based on video-level labels. Despite advances in this field, traditional Euclidean neural networks, which have been used in prior research, encounter difficulties in capturing highly discriminative representations due to limitations of the feature space. To overcome this, we propose HyperVD, a novel framework that learns snippet embeddings in hyperbolic space to improve model discrimination. Our framework comprises a detour fusion module for multimodal fusion, effectively alleviating modality inconsistency between audio and visual signals. Additionally, we contribute two branches of fully hyperbolic graph convolutional networks that excavate feature similarities and temporal relationships among snippets in hyperbolic space. By learning snippet representations in this space, the framework effectively learns semantic discrepancies between violent and normal events. Extensive experiments on the XD-Violence benchmark demonstrate that our method outperforms state-of-the-art methods by a sizable margin.
SoMoFormer: Social-Aware Motion Transformer for Multi-Person Motion Prediction
Aug 19, 2022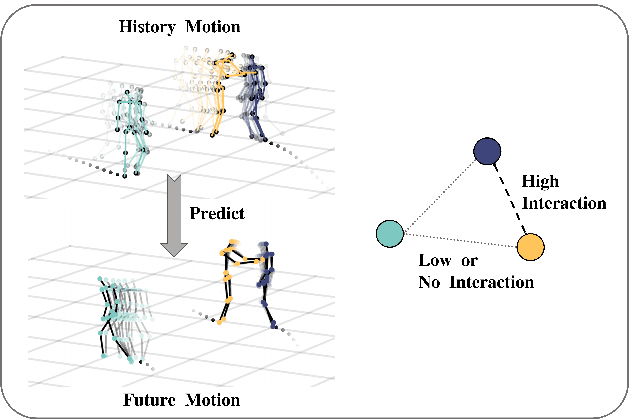
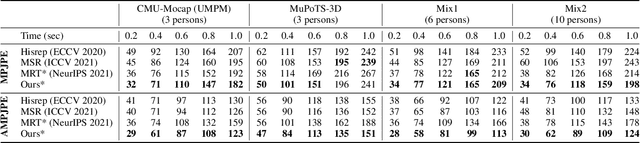
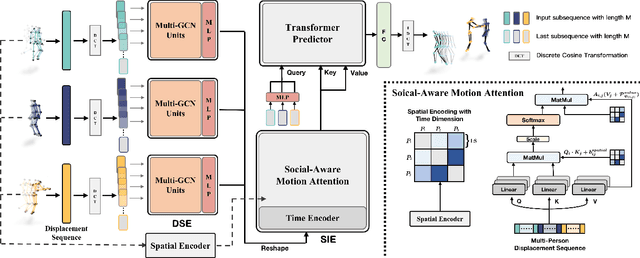
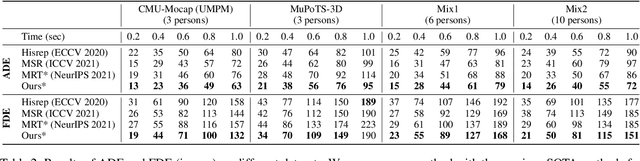
Multi-person motion prediction remains a challenging problem, especially in the joint representation learning of individual motion and social interactions. Most prior methods only involve learning local pose dynamics for individual motion (without global body trajectory) and also struggle to capture complex interaction dependencies for social interactions. In this paper, we propose a novel Social-Aware Motion Transformer (SoMoFormer) to effectively model individual motion and social interactions in a joint manner. Specifically, SoMoFormer extracts motion features from sub-sequences in displacement trajectory space to effectively learn both local and global pose dynamics for each individual. In addition, we devise a novel social-aware motion attention mechanism in SoMoFormer to further optimize dynamics representations and capture interaction dependencies simultaneously via motion similarity calculation across time and social dimensions. On both short- and long-term horizons, we empirically evaluate our framework on multi-person motion datasets and demonstrate that our method greatly outperforms state-of-the-art methods of single- and multi-person motion prediction. Code will be made publicly available upon acceptance.
Shape-from-Mask: A Deep Learning Based Human Body Shape Reconstruction from Binary Mask Images
Jun 22, 2018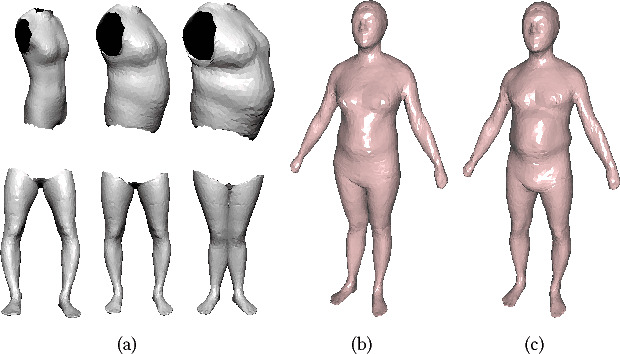
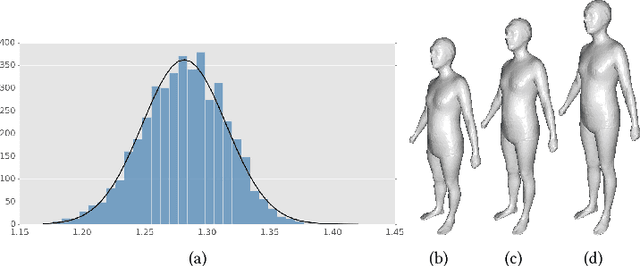
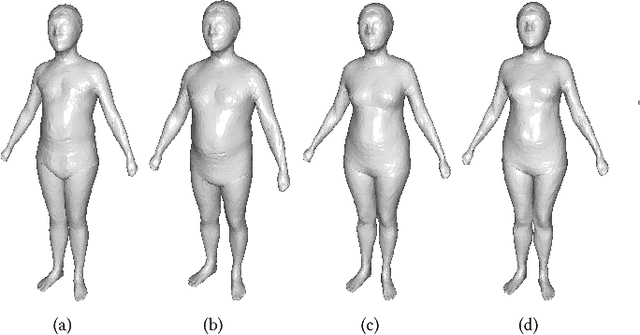
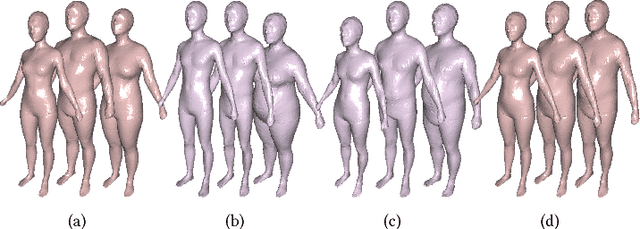
3D content creation is referred to as one of the most fundamental tasks of computer graphics. And many 3D modeling algorithms from 2D images or curves have been developed over the past several decades. Designers are allowed to align some conceptual images or sketch some suggestive curves, from front, side, and top views, and then use them as references in constructing a 3D model automatically or manually. However, to the best of our knowledge, no studies have investigated on 3D human body reconstruction in a similar manner. In this paper, we propose a deep learning based reconstruction of 3D human body shape from 2D orthographic views. A novel CNN-based regression network, with two branches corresponding to frontal and lateral views respectively, is designed for estimating 3D human body shape from 2D mask images. We train our networks separately to decouple the feature descriptors which encode the body parameters from different views, and fuse them to estimate an accurate human body shape. In addition, to overcome the shortage of training data required for this purpose, we propose some significantly data augmentation schemes for 3D human body shapes, which can be used to promote further research on this topic. Extensive experimen- tal results demonstrate that visually realistic and accurate reconstructions can be achieved effectively using our algorithm. Requiring only binary mask images, our method can help users create their own digital avatars quickly, and also make it easy to create digital human body for 3D game, virtual reality, online fashion shopping.