 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-pdd: A Novel Multi-scale PCB Defect Detection Method Using Deep Representations with Sequential Images
Jul 22, 2024With the rapid growth of the PCB manufacturing industry, there is an increasing demand for computer vision inspection to detect defects during production. Improving the accuracy and generalization of PCB defect detection models remains a significant challenge. This paper proposes a high-precision, robust, and real-time end-to-end method for PCB defect detection based on deep Convolutional Neural Networks (CNN). Traditional methods often suffer from low accuracy and limited applicability. We propose a novel approach combining YOLOv5 and multiscale modules for hierarchical residual-like connections. In PCB defect detection, noise can confuse the background and small targets. The YOLOv5 model provides a strong foundation with its real-time processing and accurate object detection capabilities. The multi-scale module extends traditional approaches by incorporating hierarchical residual-like connections within a single block, enabling multiscale feature extraction. This plug-and-play module significantly enhances performance by extracting features at multiple scales and levels, which are useful for identifying defects of varying sizes and complexities. Our multi-scale architecture integrates feature extraction, defect localization, and classification into a unified network. Experiments on a large-scale PCB dataset demonstrate significant improvements in precision, recall, and F1-score compared to existing methods. This work advances computer vision inspection for PCB defect detection, providing a reliable solution for high-precision, robust, real-time, and domain-adaptive defect detection in the PCB manufacturing industry.
Enhancing Social Decision-Making of Autonomous Vehicles: A Mixed-Strategy Game Approach With Interaction Orientation Identification
Dec 19, 2023



The integration of Autonomous Vehicles (AVs) into existing human-driven traffic systems poses considerable challenges, especially within environments where human and machine interactions are frequent and complex, such as at unsignalized intersections. Addressing these challenges, we introduce a novel framework predicated on dynamic and socially-aware decision-making game theory to augment the social decision-making prowess of AVs in mixed driving environments.This comprehensive framework is delineated into three primary modules: Social Tendency Recognition, Mixed-Strategy Game Modeling, and Expert Mode Learning. We introduce 'Interaction Orientation' as a metric to evaluate the social decision-making tendencies of various agents, incorporating both environmental factors and trajectory data. The mixed-strategy game model developed as part of this framework considers the evolution of future traffic scenarios and includes a utility function that balances safety, operational efficiency, and the unpredictability of environmental conditions. To adapt to real-world driving complexities, our framework utilizes dynamic optimization techniques for assimilating and learning from expert human driving strategies. These strategies are compiled into a comprehensive library, serving as a reference for future decision-making processes. Our approach is validated through extensive driving datasets, and the results demonstrate marked enhancements in decision timing, precision.
Teaching Autonomous Vehicles to Express Interaction Intent during Unprotected Left Turns: A Human-Driving-Prior-Based Trajectory Planning Approach
Jul 29, 2023With the integration of Autonomous Vehicles (AVs) into our transportation systems, their harmonious coexistence with Human-driven Vehicles (HVs) in mixed traffic settings becomes a crucial focus of research. A vital component of this coexistence is the capability of AVs to mimic human-like interaction intentions within the traffic environment. To address this, we propose a novel framework for Unprotected left-turn trajectory planning for AVs, aiming to replicate human driving patterns and facilitate effective communication of social intent. Our framework comprises three stages: trajectory generation, evaluation, and selection. In the generation stage, we use real human-driving trajectory data to define constraints for an anticipated trajectory space, generating candidate motion trajectories that embody intent expression. The evaluation stage employs maximum entropy inverse reinforcement learning (ME-IRL) to assess human trajectory preferences, considering factors such as traffic efficiency, driving comfort, and interactive safety. In the selection stage, we apply a Boltzmann distribution-based method to assign rewards and probabilities to candidate trajectories, thereby facilitating human-like decision-making. We conduct validation of our proposed framework using a real trajectory dataset and perform a comparative analysis against several baseline methods. The results demonstrate the superior performance of our framework in terms of human-likeness, intent expression capability, and computational efficiency. Limited by the length of the text, more details of this research can be found at https://shorturl.at/jqu35
Multi-Scale Feature Fusion using Parallel-Attention Block for COVID-19 Chest X-ray Diagnosis
Apr 25, 2023



Under the global COVID-19 crisis, accurate diagnosis of COVID-19 from Chest X-ray (CXR) images is critical. To reduce intra- and inter-observer variability, during the radiological assessment, computer-aided diagnostic tools have been utilized to supplement medical decision-making and subsequent disease management. Computational methods with high accuracy and robustness are required for rapid triaging of patients and aiding radiologists in the interpretation of the collected data. In this study, we propose a novel multi-feature fusion network using parallel attention blocks to fuse the original CXR images and local-phase feature-enhanced CXR images at multi-scales. We examine our model on various COVID-19 datasets acquired from different organizations to assess the generalization ability. Our experiments demonstrate that our method achieves state-of-art performance and has improved generalization capability, which is crucial for widespread deployment.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2023:008
Augmenting endometriosis analysis from ultrasound data with deep learning
Feb 19, 2023Endometriosis is a non-malignant disorder that affects 176 million women globally. Diagnostic delays result in severe dysmenorrhea, dyspareunia, chronic pelvic pain, and infertility. Therefore, there is a significant need to diagnose patients at an early stage. Our objective in this work is to investigate the potential of deep learning methods to classify endometriosis from ultrasound data. Retrospective data from 100 subjects were collected at the Rutgers Robert Wood Johnson University Hospital (New Brunswick, NJ, USA). Endometriosis was diagnosed via laparoscopy or laparotomy. We designed and trained five different deep learning methods (Xception, Inception-V4, ResNet50, DenseNet, and EfficientNetB2) for the classification of endometriosis from ultrasound data. Using 5-fold cross-validation study we achieved an average area under the receiver operator curve (AUC) of 0.85 and 0.90 respectively for the two evaluation studies.
Multi-Feature Vision Transformer via Self-Supervised Representation Learning for Improvement of COVID-19 Diagnosis
Aug 03, 2022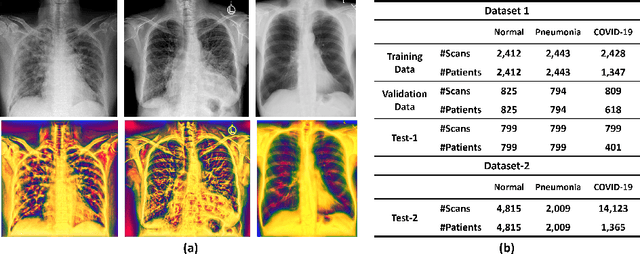
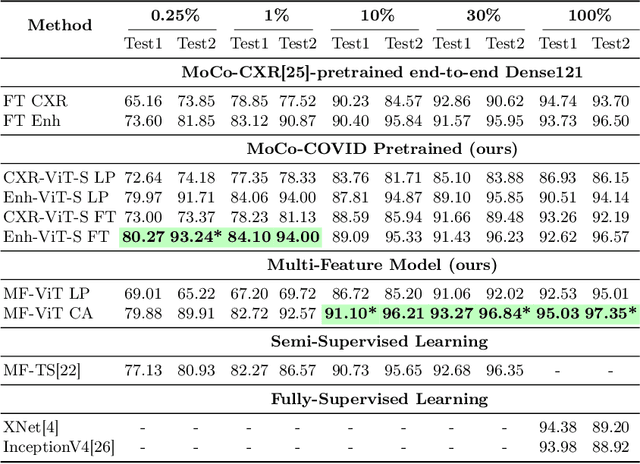
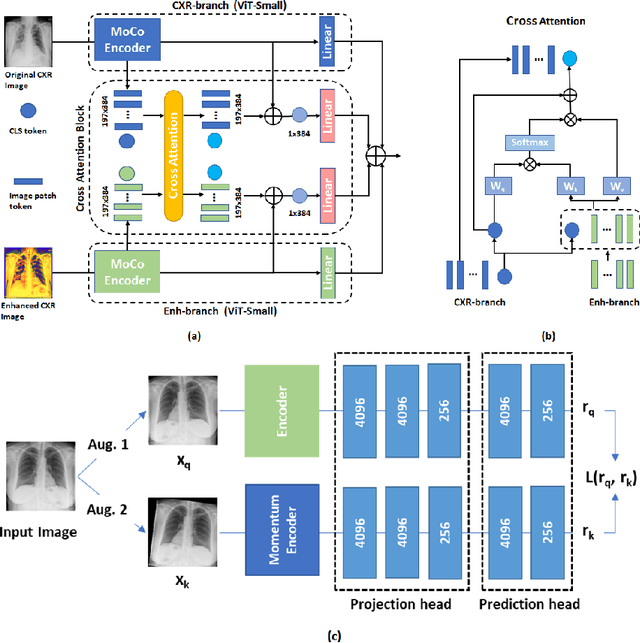

The role of chest X-ray (CXR) imaging, due to being more cost-effective, widely available, and having a faster acquisition time compared to CT, has evolved during the COVID-19 pandemic. To improve the diagnostic performance of CXR imaging a growing number of studies have investigated whether supervised deep learning methods can provide additional support. However, supervised methods rely on a large number of labeled radiology images, which is a time-consuming and complex procedure requiring expert clinician input. Due to the relative scarcity of COVID-19 patient data and the costly labeling process, self-supervised learning methods have gained momentum and has been proposed achieving comparable results to fully supervised learning approaches. In this work, we study the effectiveness of self-supervised learning in the context of diagnosing COVID-19 disease from CXR images. We propose a multi-feature Vision Transformer (ViT) guided architecture where we deploy a cross-attention mechanism to learn information from both original CXR images and corresponding enhanced local phase CXR images. We demonstrate the performance of the baseline self-supervised learning models can be further improved by leveraging the local phase-based enhanced CXR images. By using 10\% labeled CXR scans, the proposed model achieves 91.10\% and 96.21\% overall accuracy tested on total 35,483 CXR images of healthy (8,851), regular pneumonia (6,045), and COVID-19 (18,159) scans and shows significant improvement over state-of-the-art techniques. Code is available https://github.com/endiqq/Multi-Feature-ViT
Multi-Feature Semi-Supervised Learning for COVID-19 Diagnosis from Chest X-ray Images
Apr 14, 2021

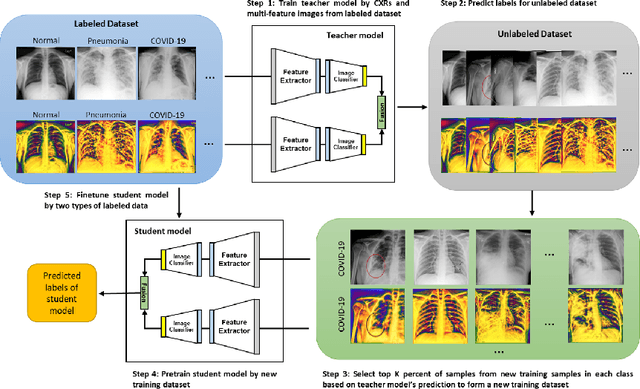

Computed tomography (CT) and chest X-ray (CXR) have been the two dominant imaging modalities deployed for improved management of Coronavirus disease 2019 (COVID-19). Due to faster imaging, less radiation exposure, and being cost-effective CXR is preferred over CT. However, the interpretation of CXR images, compared to CT, is more challenging due to low image resolution and COVID-19 image features being similar to regular pneumonia. Computer-aided diagnosis via deep learning has been investigated to help mitigate these problems and help clinicians during the decision-making process. The requirement for a large amount of labeled data is one of the major problems of deep learning methods when deployed in the medical domain. To provide a solution to this, in this work, we propose a semi-supervised learning (SSL) approach using minimal data for training. We integrate local-phase CXR image features into a multi-feature convolutional neural network architecture where the training of SSL method is obtained with a teacher/student paradigm. Quantitative evaluation is performed on 8,851 normal (healthy), 6,045 pneumonia, and 3,795 COVID-19 CXR scans. By only using 7.06% labeled and 16.48% unlabeled data for training, 5.53% for validation, our method achieves 93.61\% mean accuracy on a large-scale (70.93%) test data. We provide comparison results against fully supervised and SSL methods. Code: https://github.com/endiqq/Multi-Feature-Semi-Supervised-Learning-for-COVID-19-CXR-Images
Chest X-ray Image Phase Features for Improved Diagnosis of COVID-19 Using Convolutional Neural Network
Nov 06, 2020
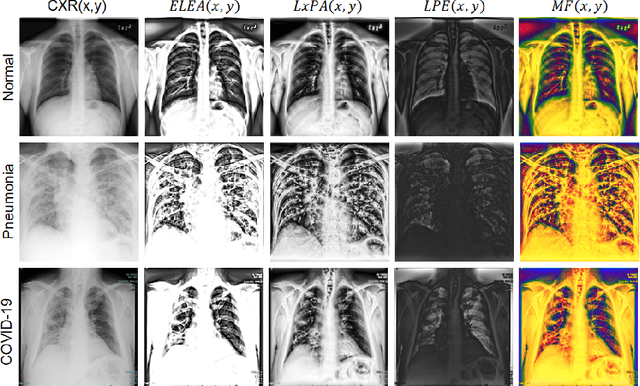


Recently, the outbreak of the novel Coronavirus disease 2019 (COVID-19) pandemic has seriously endangered human health and life. Due to limited availability of test kits, the need for auxiliary diagnostic approach has increased. Recent research has shown radiography of COVID-19 patient, such as CT and X-ray, contains salient information about the COVID-19 virus and could be used as an alternative diagnosis method. Chest X-ray (CXR) due to its faster imaging time, wide availability, low cost and portability gains much attention and becomes very promising. Computational methods with high accuracy and robustness are required for rapid triaging of patients and aiding radiologist in the interpretation of the collected data. In this study, we design a novel multi-feature convolutional neural network (CNN) architecture for multi-class improved classification of COVID-19 from CXR images. CXR images are enhanced using a local phase-based image enhancement method. The enhanced images, together with the original CXR data, are used as an input to our proposed CNN architecture. Using ablation studies, we show the effectiveness of the enhanced images in improving the diagnostic accuracy. We provide quantitative evaluation on two datasets and qualitative results for visual inspection. Quantitative evaluation is performed on data consisting of 8,851 normal (healthy), 6,045 pneumonia, and 3,323 Covid-19 CXR scans. In Dataset-1, our model achieves 95.57\% average accuracy for a three classes classification, 99\% precision, recall, and F1-scores for COVID-19 cases. For Dataset-2, we have obtained 94.44\% average accuracy, and 95\% precision, recall, and F1-scores for detection of COVID-19. Conclusions: Our proposed multi-feature guided CNN achieves improved results compared to single-feature CNN proving the importance of the local phase-based CXR image enhancement.
Shape-from-Mask: A Deep Learning Based Human Body Shape Reconstruction from Binary Mask Images
Jun 22, 2018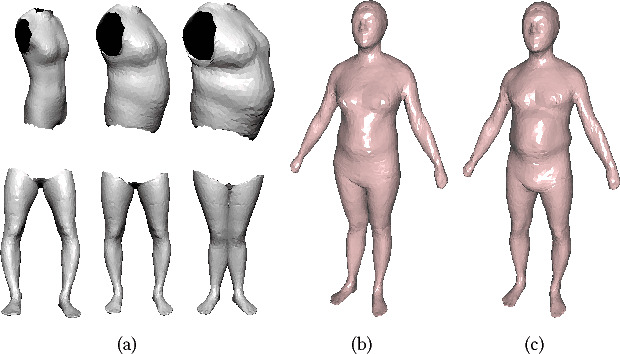
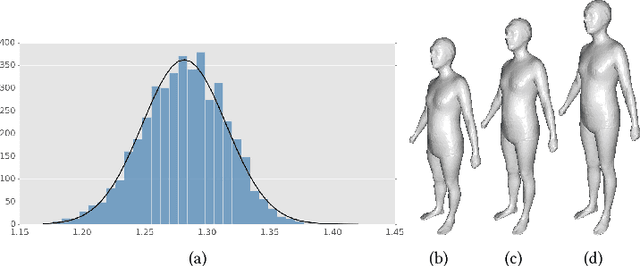
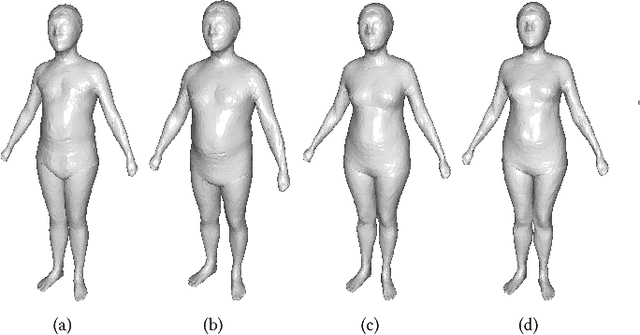
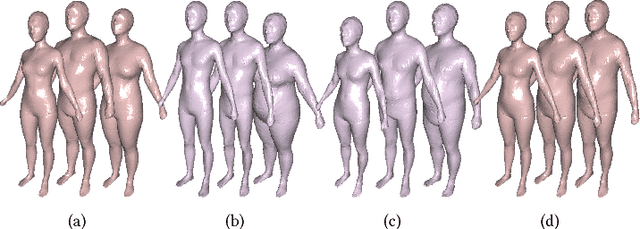
3D content creation is referred to as one of the most fundamental tasks of computer graphics. And many 3D modeling algorithms from 2D images or curves have been developed over the past several decades. Designers are allowed to align some conceptual images or sketch some suggestive curves, from front, side, and top views, and then use them as references in constructing a 3D model automatically or manually. However, to the best of our knowledge, no studies have investigated on 3D human body reconstruction in a similar manner. In this paper, we propose a deep learning based reconstruction of 3D human body shape from 2D orthographic views. A novel CNN-based regression network, with two branches corresponding to frontal and lateral views respectively, is designed for estimating 3D human body shape from 2D mask images. We train our networks separately to decouple the feature descriptors which encode the body parameters from different views, and fuse them to estimate an accurate human body shape. In addition, to overcome the shortage of training data required for this purpose, we propose some significantly data augmentation schemes for 3D human body shapes, which can be used to promote further research on this topic. Extensive experimen- tal results demonstrate that visually realistic and accurate reconstructions can be achieved effectively using our algorithm. Requiring only binary mask images, our method can help users create their own digital avatars quickly, and also make it easy to create digital human body for 3D game, virtual reality, online fashion shopping.