 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Feature Fusion using Parallel-Attention Block for COVID-19 Chest X-ray Diagnosis
Apr 25, 2023



Under the global COVID-19 crisis, accurate diagnosis of COVID-19 from Chest X-ray (CXR) images is critical. To reduce intra- and inter-observer variability, during the radiological assessment, computer-aided diagnostic tools have been utilized to supplement medical decision-making and subsequent disease management. Computational methods with high accuracy and robustness are required for rapid triaging of patients and aiding radiologists in the interpretation of the collected data. In this study, we propose a novel multi-feature fusion network using parallel attention blocks to fuse the original CXR images and local-phase feature-enhanced CXR images at multi-scales. We examine our model on various COVID-19 datasets acquired from different organizations to assess the generalization ability. Our experiments demonstrate that our method achieves state-of-art performance and has improved generalization capability, which is crucial for widespread deployment.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2023:008
Multi-Feature Vision Transformer via Self-Supervised Representation Learning for Improvement of COVID-19 Diagnosis
Aug 03, 2022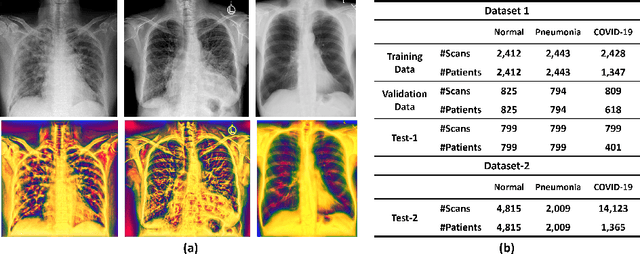
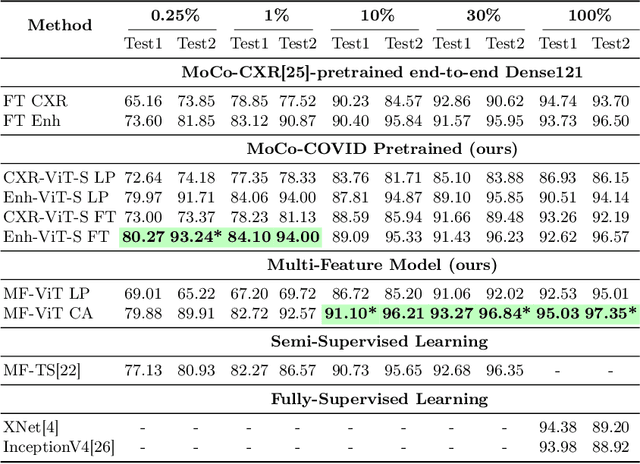
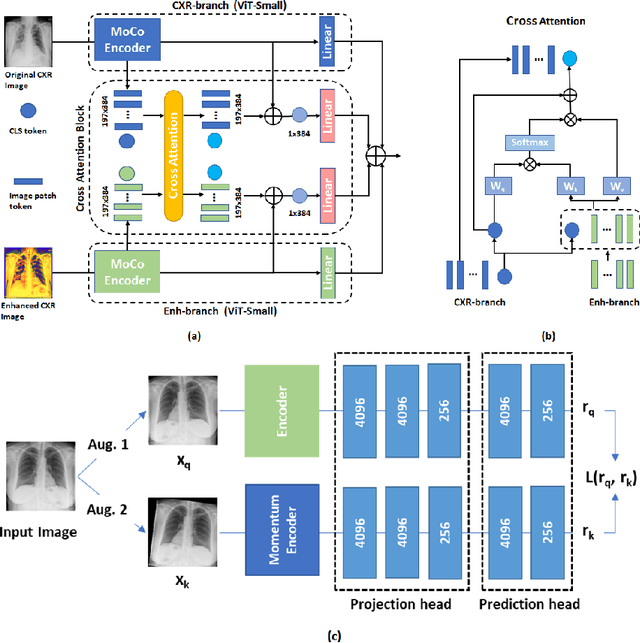

The role of chest X-ray (CXR) imaging, due to being more cost-effective, widely available, and having a faster acquisition time compared to CT, has evolved during the COVID-19 pandemic. To improve the diagnostic performance of CXR imaging a growing number of studies have investigated whether supervised deep learning methods can provide additional support. However, supervised methods rely on a large number of labeled radiology images, which is a time-consuming and complex procedure requiring expert clinician input. Due to the relative scarcity of COVID-19 patient data and the costly labeling process, self-supervised learning methods have gained momentum and has been proposed achieving comparable results to fully supervised learning approaches. In this work, we study the effectiveness of self-supervised learning in the context of diagnosing COVID-19 disease from CXR images. We propose a multi-feature Vision Transformer (ViT) guided architecture where we deploy a cross-attention mechanism to learn information from both original CXR images and corresponding enhanced local phase CXR images. We demonstrate the performance of the baseline self-supervised learning models can be further improved by leveraging the local phase-based enhanced CXR images. By using 10\% labeled CXR scans, the proposed model achieves 91.10\% and 96.21\% overall accuracy tested on total 35,483 CXR images of healthy (8,851), regular pneumonia (6,045), and COVID-19 (18,159) scans and shows significant improvement over state-of-the-art techniques. Code is available https://github.com/endiqq/Multi-Feature-ViT
Multi-Feature Semi-Supervised Learning for COVID-19 Diagnosis from Chest X-ray Images
Apr 14, 2021

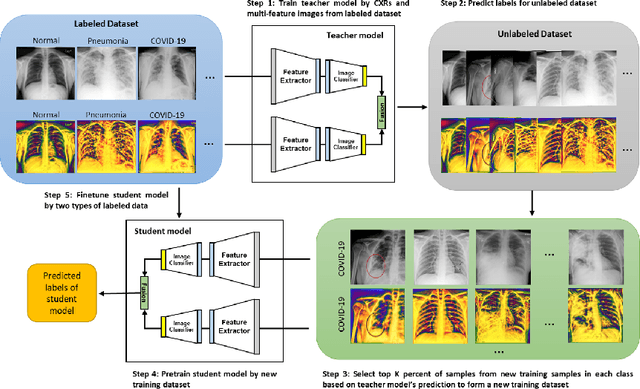

Computed tomography (CT) and chest X-ray (CXR) have been the two dominant imaging modalities deployed for improved management of Coronavirus disease 2019 (COVID-19). Due to faster imaging, less radiation exposure, and being cost-effective CXR is preferred over CT. However, the interpretation of CXR images, compared to CT, is more challenging due to low image resolution and COVID-19 image features being similar to regular pneumonia. Computer-aided diagnosis via deep learning has been investigated to help mitigate these problems and help clinicians during the decision-making process. The requirement for a large amount of labeled data is one of the major problems of deep learning methods when deployed in the medical domain. To provide a solution to this, in this work, we propose a semi-supervised learning (SSL) approach using minimal data for training. We integrate local-phase CXR image features into a multi-feature convolutional neural network architecture where the training of SSL method is obtained with a teacher/student paradigm. Quantitative evaluation is performed on 8,851 normal (healthy), 6,045 pneumonia, and 3,795 COVID-19 CXR scans. By only using 7.06% labeled and 16.48% unlabeled data for training, 5.53% for validation, our method achieves 93.61\% mean accuracy on a large-scale (70.93%) test data. We provide comparison results against fully supervised and SSL methods. Code: https://github.com/endiqq/Multi-Feature-Semi-Supervised-Learning-for-COVID-19-CXR-Images
Chest X-ray Image Phase Features for Improved Diagnosis of COVID-19 Using Convolutional Neural Network
Nov 06, 2020
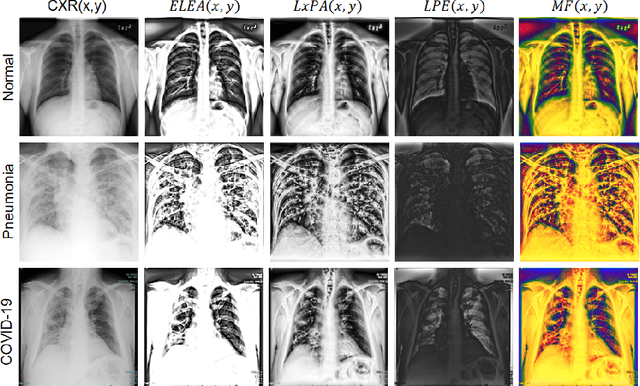


Recently, the outbreak of the novel Coronavirus disease 2019 (COVID-19) pandemic has seriously endangered human health and life. Due to limited availability of test kits, the need for auxiliary diagnostic approach has increased. Recent research has shown radiography of COVID-19 patient, such as CT and X-ray, contains salient information about the COVID-19 virus and could be used as an alternative diagnosis method. Chest X-ray (CXR) due to its faster imaging time, wide availability, low cost and portability gains much attention and becomes very promising. Computational methods with high accuracy and robustness are required for rapid triaging of patients and aiding radiologist in the interpretation of the collected data. In this study, we design a novel multi-feature convolutional neural network (CNN) architecture for multi-class improved classification of COVID-19 from CXR images. CXR images are enhanced using a local phase-based image enhancement method. The enhanced images, together with the original CXR data, are used as an input to our proposed CNN architecture. Using ablation studies, we show the effectiveness of the enhanced images in improving the diagnostic accuracy. We provide quantitative evaluation on two datasets and qualitative results for visual inspection. Quantitative evaluation is performed on data consisting of 8,851 normal (healthy), 6,045 pneumonia, and 3,323 Covid-19 CXR scans. In Dataset-1, our model achieves 95.57\% average accuracy for a three classes classification, 99\% precision, recall, and F1-scores for COVID-19 cases. For Dataset-2, we have obtained 94.44\% average accuracy, and 95\% precision, recall, and F1-scores for detection of COVID-19. Conclusions: Our proposed multi-feature guided CNN achieves improved results compared to single-feature CNN proving the importance of the local phase-based CXR image enhancement.
Adversarial Domain Adaptation for Classification of Prostate Histopathology Whole-Slide Images
Jun 06, 2018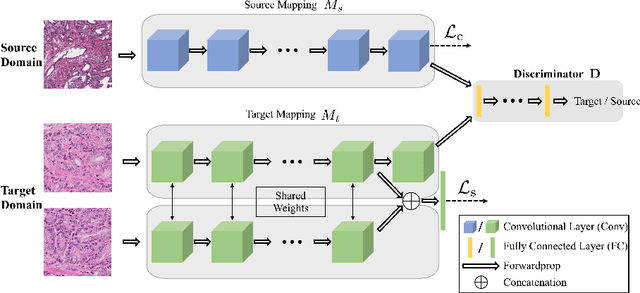

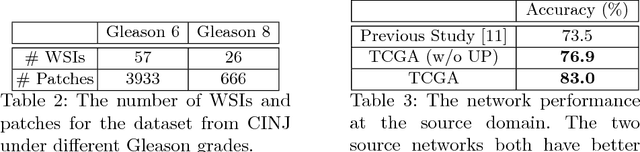
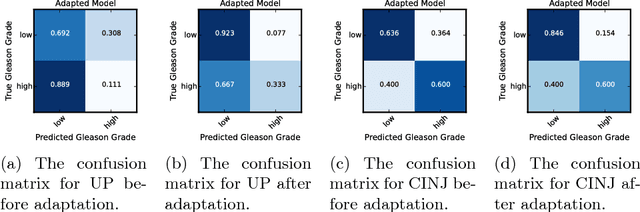
Automatic and accurate Gleason grading of histopathology tissue slides is crucial for prostate cancer diagnosis, treatment, and prognosis. Usually, histopathology tissue slides from different institutions show heterogeneous appearances because of different tissue preparation and staining procedures, thus the predictable model learned from one domain may not be applicable to a new domain directly. Here we propose to adopt unsupervised domain adaptation to transfer the discriminative knowledge obtained from the source domain to the target domain without requiring labeling of images at the target domain. The adaptation is achieved through adversarial training to find an invariant feature space along with the proposed Siamese architecture on the target domain to add a regularization that is appropriate for the whole-slide images. We validate the method on two prostate cancer datasets and obtain significant classification improvement of Gleason scores as compared with the baseline models.
EIGEN: Ecologically-Inspired GENetic Approach for Neural Network Structure Searching
Jun 05, 2018



Designing the structure of neural networks is considered one of the most challenging tasks in deep learning. Recently, a few approaches have been proposed to automatically search for the optimal structure of neural networks, however, they suffer from either prohibitive computation cost (e.g., 256 Hours on 250 GPU in [1]) or unsatisfactory performance compared to those of hand-crafted neural networks. In this paper, we propose an Ecologically-Inspired GENetic approach for neural network structure search (EIGEN), that includes succession, mimicry and gene duplication. Specifically, we first use primary succession to rapidly evolve a community of poor initialized neural network structures into a more diverse community, followed by a secondary succession stage for fine-grained searching based on the networks from the primary succession. Extinction is applied in both stages to reduce computational cost. Mimicry is employed during the entire evolution process to help the inferior networks imitate the behavior of a superior network and gene duplication is utilized to duplicate the learned blocks of novel structures, both of which help to find the better network structures. Extensive experimental results show that our proposed approach can achieve the similar or better performance compared to the existing genetic approaches with dramatically reduced computation cost. For example, the network discovered by our approach on CIFAR-100 dataset achieves 78.1% test accuracy under 120 GPU hours, compared to 77.0% test accuracy in more than 65, 536 GPU hours in [1].
Factorized Adversarial Networks for Unsupervised Domain Adaptation
Jun 04, 2018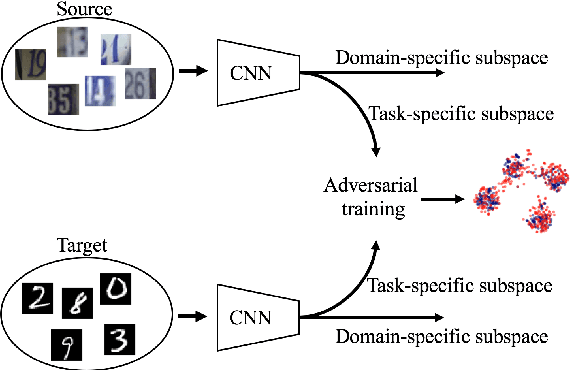
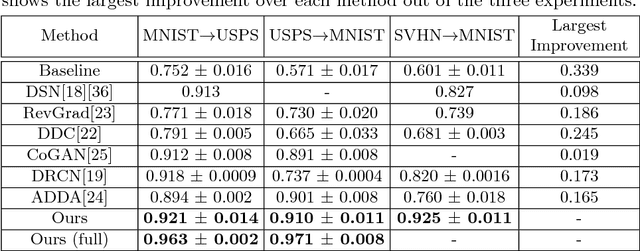
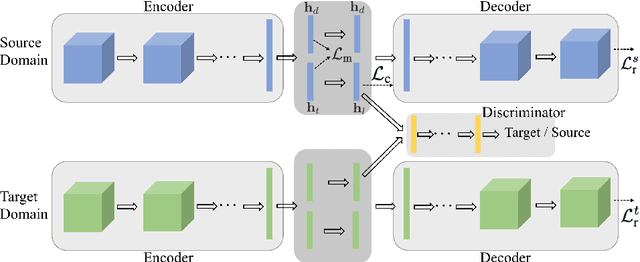

In this paper, we propose Factorized Adversarial Networks (FAN) to solve unsupervised domain adaptation problems for image classification tasks. Our networks map the data distribution into a latent feature space, which is factorized into a domain-specific subspace that contains domain-specific characteristics and a task-specific subspace that retains category information, for both source and target domains, respectively. Unsupervised domain adaptation is achieved by adversarial training to minimize the discrepancy between the distributions of two task-specific subspaces from source and target domains. We demonstrate that the proposed approach outperforms state-of-the-art methods on multiple benchmark datasets used in the literature for unsupervised domain adaptation. Furthermore, we collect two real-world tagging datasets that are much larger than existing benchmark datasets, and get significant improvement upon baselines, proving the practical value of our approach.